DeepSeek揭秘:清北应届生打造AI奇迹团队
DeepSeek大模型横空出世,以1/11的算力训练出超越Llama 3的开源模型,震撼了整个AI圈。紧接着,“雷军开千万年薪挖DeepSeek研究员罗福莉”的传闻,更将人们的目光聚焦向DeepSeek的人才团队。科技圈内外无不好奇,这只究竟是怎样的团队?国际上也掀起热潮,有人将创始人梁文锋的访谈翻译成英语并附上注释,试图从中窥探这家公司崛起的奥秘。


量子位通过整理资料发现,DeepSeek团队最大的特点就是年轻。其中活跃着大量应届生和在读生,尤其是来自清华、北大的优秀学子。他们中的一些人,2024年一边在DeepSeek从事研究工作,一边刚获得博士学位论文奖项。他们有的全程参与了从DeepSeek LLM v1到DeepSeek-v3的研发,有的虽仅实习一段时间,却取得了重要成果。DeepSeek提出MLA新型注意力、GRPO强化学习对齐算法等关键创新,几乎都出自这些年轻人之手。

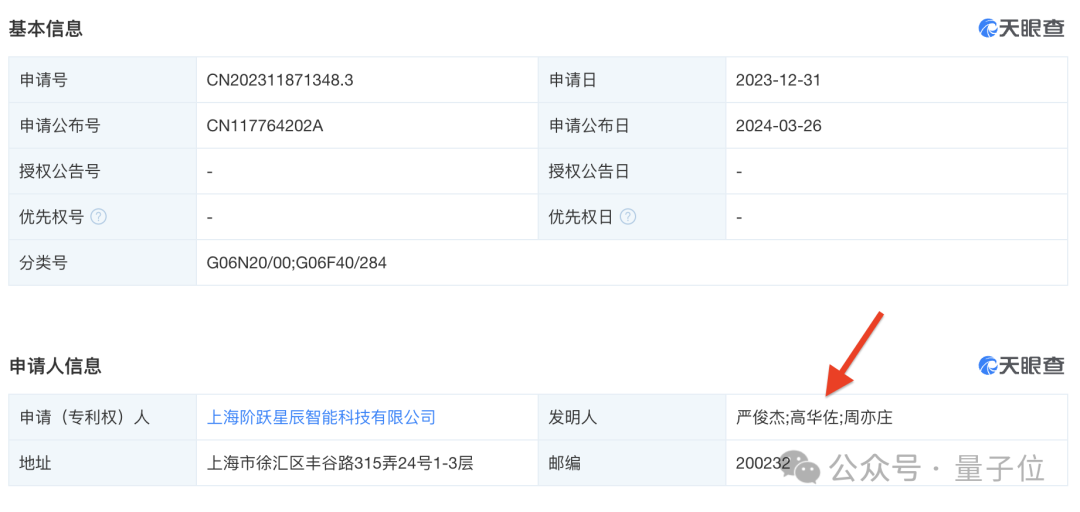
2024年5月发布的DeepSeek-V2,成为DeepSeek这家大模型公司破圈的关键一环。其中最重要的创新是提出了一种新型注意力机制MLA(Multi-head Latent Attention),在Transformer架构基础上替代传统多头注意力,大幅减少计算量和推理显存。高华佐和曾旺丁为MLA架构做出了关键创新。高华佐非常低调,目前只知道是北大物理系毕业。在“大模型创业六小强”之一阶跃星辰的专利信息中也可以看到这个名字,但暂不确定是否为同一人。而曾旺丁来自北邮,研究生导师是北邮人工智能与网络搜索教研中心主任张洪刚。

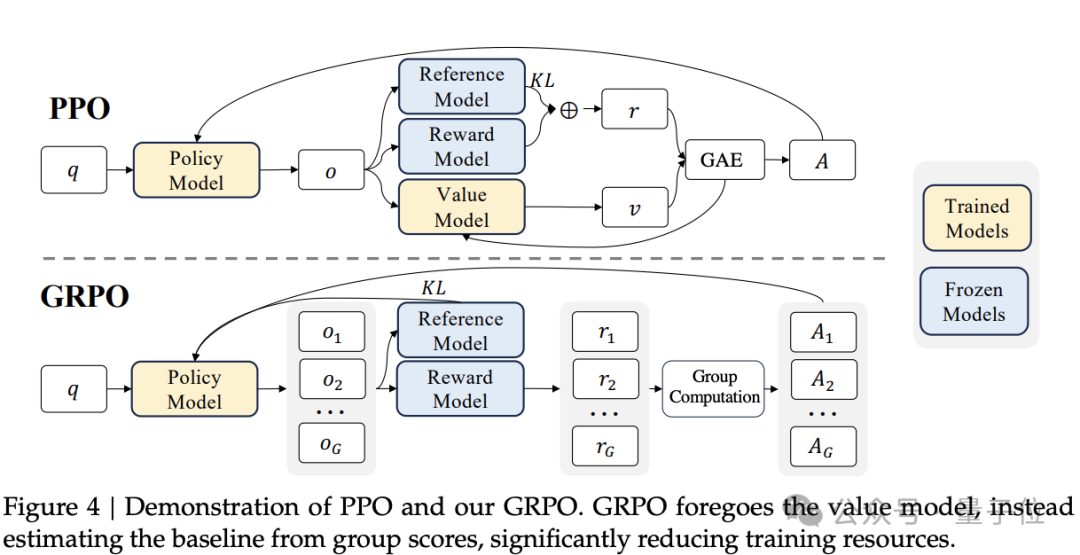
DeepSeek-V2工作中还涉及另一项关键成果——GRPO。DeepSeek-V2发布前三个月,DeepSeek-Math问世,其中提出了GRPO(Group Relative Policy Optimization)。GRPO是PPO的一种变体RL算法,放弃了critic模型,而是从群体得分中估算baseline,显著减少训练资源需求。GRPO在圈内得到广泛关注,另一家国内开源大模型阿里Qwen 2.5的技术报告中也透露用到了GRPO。

DeepSeekMath有三位核心作者是在DeepSeek实习期间完成的工作。核心作者之一邵智宏是清华交互式人工智能(CoAI)课题组博士生,师从黄民烈教授。他的研究领域包括自然语言处理、深度学习,特别对如何构建稳健且可扩展的AI系统感兴趣,这个系统能利用多样化技能整合异构信息,准确回答复杂自然语言问题。邵智宏之前还曾在微软研究院工作过。DeepSeekMath之后,他还参与了DeepSeek-Prover、DeepSeek-Coder-v2、DeepSeek-R1等项目。

另一位核心作者朱琪豪是北大计算机学院软件研究所2024届博士毕业生,受熊英飞副教授和张路教授指导,研究方向为深度代码学习。据北大计算机学院官方介绍,朱琪豪曾发表CCF-A类论文16篇,在ASE和ESEC/FSE上分别获得ACM SIGSOFT杰出论文奖一次,提名一次。一篇论文进入ESEC/FSE会议同年的引用前三名。在DeepSeek团队,朱琪豪还基于博士论文工作,主导开发了DeepSeek-Coder-V1。其博士论文《语言定义感知的深度代码学习技术及应用》也入选了2024CCF软件工程专业委员会博士学位论文激励计划。

还有一位核心作者同样来自北大。北大博士生Peiyi Wang,受北京大学计算语言学教育部重点实验室穗志方教授指导。除了DeepSeek-V2 MLA、DeepSeekMath GRPO这两项关键破圈成果,值得一提的是,还有一些成员从v1就加入其中,一直参与到v3。代表人物之一代达劢,2024年博士毕业于北京大学计算机学院计算语言所,导师同样是穗志方教授。代达劢学术成果颇丰,曾获EMNLP 2023最佳长论文奖、CCL 2021最佳中文论文奖,在各大顶会发表学术论文20篇以上。2024年中国中文信息学会“博士学位论文激励计划”共入选10篇来自中国大陆高校的博士毕业论文,其中就有他的《预训练语言模型知识记忆的机理分析及能力增强关键技术研究》。以及北大元培学院的王炳宣。王炳宣来自山东烟台,2017年进入北大。硕士毕业加入DeepSeek,参与了从DeepSeek LLM v1开始的一系列重要工作。清华这边的代表人物还有赵成钢。赵成钢此前是衡水中学信息学竞赛班成员,CCF NOI2016银牌得主。之后赵成钢进入清华,大二时成为清华学生超算团队正式成员,三次获得世界大学生超算竞赛冠军。赵成钢在DeepSeek担任训练/推理基础架构工程师,有英伟达实习经历。

DeepSeek是一支怎样的团队?这些鲜活的个体足以引发人们的赞叹。但还不足以回答最初的问题,DeepSeek到底是一支怎样的团队?有怎样的组织架构?答案或许还要从创始人梁文锋身上找。早在2023年5月,DeepSeek刚刚宣布下场做大模型,还没发布成果的时候,梁文锋在接受36氪旗下「暗涌」采访时透露过招人标准:看能力,而不是看经验。我们的核心技术岗位,基本以应届和毕业一两年的人为主。从后面一年多陆续发表的论文贡献名单中也可以看出,确实如此,博士在读、应届以及毕业一两年的成员占很大一部分。即使是团队leader级别也偏年轻化,以毕业4-6年的为主。例如领导DeepSeek的后训练团队的吴俣,2019年北航博士毕业、在微软MSRA参与过小冰和必应百科项目。吴俣博士期间接受北航李舟军教授和MSRA前副院长周明博士的联合培养。与他师出半个同门的是郭达雅,中山大学印鉴教授与MSRA周明博士联合培养,2023年博士毕业。2024年7月他加入DeepSeek,主要参与了一系列数学和代码大模型的工作。郭达雅上学期间还有一项事迹,本科期间在MSRA实习一年里发表两篇顶会论文,他笑称“在刚入学的第三天,就完成了中大博士生的毕业要求。”
除了团队成员年轻化之外,DeepSeek在国内AI公司中突出的特点:非常重视模型算法和硬件工程的配合。DeepSeek v3论文总共200位作者,并不都是负责AI算法或数据。有这样一批人从早期的DeepSeek LLM v1到v3一直都在参与,他们更多偏向算力的部分,负责优化硬件。他们以DeepSeek AI的名义发表了论文《Fire-Flyer AI-HPC》,通过软硬件协同设计降低训练成本,解决传统超算架构在AI训练需求上的不足。Fire-Flyer也就是幻方AI搭建的萤火2号万卡集群,使用英伟达A100 GPU,却做到相比英伟达官方的DGX-A100服务器有成本和能耗的优势。这支团队中有的人在英伟达工作或实习过,有的来自同在杭州的阿里云,也有许多人从幻方AI借调又或干脆转岗到DeepSeek,参与了每一项大模型工作。而如此重视软硬件协同的成果,就是以Llama 3 405B的1/11算力,训练出性能更高的DeepSeek-v3了。
最后,我们还发现DeepSeek开源项目中有一个特别的存在,不是语言模型相关工作,却是3D生成相关。这项成果由清华博士生孙景翔在DeepSeek实习期间,与导师刘烨斌以及DeepSeek成员合作完成。像这样实习生在DeepSeek做出重要成果的还有中山大学逻辑学专业的辛华剑。他在DeepSeek实习期间参与了用大模型证明数学定理的DeepSeek-Prover,现在在爱丁堡大学读博士。
看过这些例子,再一次回到梁文锋的访谈,或许更能理解这只团队的运作结构。不做前置的岗位分工,而是自然分工,每个人对于卡和人的调动是不设上限的,每个人可以随时调用训练集群,只要几个人都有兴趣就可以开始一个项目。当一个idea显示出潜力,也会自上而下地去调配资源。这难免让人想起AI界另一家不可忽视的力量,没错就是OpenAI。同样的用人不看经验,本科生、辍学生只要有能力照样招进来。同样的重用新人,应届生与00后可以调动资源从无到有研究Sora。同样的面对潜力方向,整个公司从顶层开始设计布局和资源推动。DeepSeek,可能是组织形态上最像OpenAI的一家中国AI公司了。









相关推荐
-
黄仁勋AI战略解析:英伟达能否再创辉煌
硅基研究室 | 作者 | kiki谢浩 今年的英伟达GTC大会,似乎比去年少了些许狂热,但黄仁勋的AI叙事依旧引人瞩目。在美国加州圣何塞,英伟达的绿色身影依旧是科技圈最耀眼的符号。…
-
市值暴降超6万亿!英伟达从明星变“梦魇”,黄仁勋不愿当中美关税战的“棋子”
英伟达CEO黄仁勋(Jensen Huang) 当前局势对于英伟达CEO黄仁勋(Jensen Huang)来说,实在太难了。 六个月前,英伟达在投资人心目中堪称美国经济领头羊,不仅…
-
Claude 25000字提示词泄露:AI行为“隐形脚本”曝光内幕
AI领域近日再起波澜,焦点集中于Anthropic公司旗下的明星大语言模型Claude。据广泛报道,一份据称是Claude应用的系统提示词(System Prompt)遭遇泄露,其…
-
DeepEP开源王炸:MoE全栈通信库引爆AI算力革命
2月25日,DeepSeek以开源姿态震撼业界,推出全球首款面向MoE模型的全栈通信库——DeepEP,为AI算力瓶颈带来革命性解决方案。GitHub平台数据飙升1500星,圈内反…
-
MiniMax震撼开源,突破传统Transformer架构,4560亿参数,支持400万长上下文
Image source: Generated by AI 「2025 年,我们可能会看到第一批 AI Agent 加入劳动力大军,并对公司的生产力产生实质性的影响。」——Open…
-
Manus与Lovart对比评测:谁更适合AI内容创作?
这几天,社交媒体被一张张 AI 绘制的杂志封面刷屏,引发热议。这些封面并非出自即梦或 Midjourney,而是来自一个鲜为人知的新名字——Lovart。你是否也经历过被“设计圈 …
-
腾讯AI视频生成对决Sora同提示词效果测评
腾讯版Sora迎来重大进展,相关视频生成模型与产品正经历紧张的升级与调试阶段。虽然正式上线时间尚未确定,但幸运的内测用户已率先体验其强大功能,让我们抢先一探究竟。 作为腾讯首款文生…
-
GPT-4o批量生成宫崎骏风格引争议 艺术家集体抗议AI侵权
在AI浪潮席卷全球的今天,惊喜如同连珠炮般接连不断。以OpenAI为例,其推出的GPT-4o图像生成功能一经问世,便在社交媒体上掀起了一股前所未有的吉卜力工作室风格热潮。短短24小…
-
2025AI中场战事:巨头围剿新贵谁主沉浮
国内AI大模型市场正经历从”百模大战”到淘汰整合的中场阶段转型。经过2023年以来的激烈竞争和资本热潮,行业格局逐渐明朗,形成了新老巨头与新兴独角兽两大阵营…
-
达闼机器人200亿估值陷危机 黄晓庆独家回应公司正常运营
达闼机器人创始人兼CEO黄晓庆近日发声,透露这家备受瞩目的人形机器人企业正面临严峻挑战。据多方报道,达闼机器人过去一年内遭遇欠薪、裁员风波,部分员工反映公司采取“折半发放工资”等临…