OpenAI Deep Research全面开放ChatGPT用户使用并发布系统卡
Deep Research 的卓越能力想必许多用户已经有所耳闻。就在今天凌晨,OpenAI 宣布这项强大的智能工具已正式面向所有 ChatGPT Plus、Team、Edu 和 Enterprise 用户开放,而此前它仅对 Pro 用户可用。与此同时,OpenAI 还发布了 Deep Research 系统卡作为重要补充。更令人瞩目的是,OpenAI 研究科学家 Noam Brown 在 𝕏 平台上确认:Deep Research 所依赖的基础模型是 o3 正式版,而非 o3-mini。这款由 OpenAI 本月初推出的强大智能体,能够通过推理能力整合海量在线信息,协助用户完成多步骤研究任务,从而在深入、复杂的信息查询与分析方面提供强大支持。关于 Deep Research 的详细介绍,可参阅机器之心报道《刚刚,OpenAI 上线 Deep Research!人类终极考试远超 DeepSeek R1》。


在发布后的二十多天里,OpenAI 对 Deep Research 进行了持续升级。此次发布的 Deep Research 系统卡报告,详细介绍了推出该功能前所进行的安全工作,包括外部红队测试、基于准备度框架的风险评估,以及 OpenAI 为解决关键风险领域所采取的缓解措施。以下我们整理了这份报告的主要内容:https://cdn.openai.com/deep-research-system-card.pdf
Deep Research 是一种创新的智能体能力,专为处理复杂任务而设计,能够在互联网上进行多步骤研究。该模型基于为网页浏览优化的 OpenAI o3 早期版本,通过推理能力搜索、解读和分析互联网上的大量文本、图像及 PDF 文件,并根据获取的信息灵活调整策略。此外,Deep Research 还能读取用户提供的文件,并通过编写和执行 Python 代码来分析数据。OpenAI 表示:”我们相信 Deep Research 可以帮助人们应对多种多样的情形。” 在正式发布并开放给 Pro 用户前,OpenAI 进行了严格的安全测试、准备度评估和治理审查。为更好地理解 Deep Research 浏览网页能力带来的增量风险,OpenAI 还进行了额外测试,并增加了新的缓解措施。重点改进领域包括加强对在线发布个人信息的隐私保护,以及训练模型以抵御搜索互联网时可能遇到的恶意指令。
OpenAI 指出,对 Deep Research 的测试也揭示了进一步优化测试方法的机会。在扩大发布范围前,他们将投入更多时间对选定的风险进行深入的人工检测和自动化测试。本系统卡全面展示了 OpenAI 如何构建 Deep Research、评估其能力与风险,以及在发布前提升其安全性的过程。
在模型数据和训练方面,Deep Research 的训练数据是专为研究用例打造的新浏览数据集。该模型掌握了核心浏览功能(搜索、点击、滚动、解读文件),学会了在沙盒环境中使用 Python 工具(用于计算、数据分析和绘图),并通过强化学习训练,能够推理和整合大量网站信息,以查找特定数据或撰写综合报告。训练数据集包含多样化任务:既有带 ground truth 答案的客观自动评分任务,也有更开放的、带有评分标准的任务。训练期间,评分过程采用思维链模型,根据 ground truth 答案或评分标准给出模型响应的分数。此外,该模型的训练还利用了 OpenAI o1 训练中使用的现有安全数据集,以及为 Deep Research 定制的浏览安全数据集。

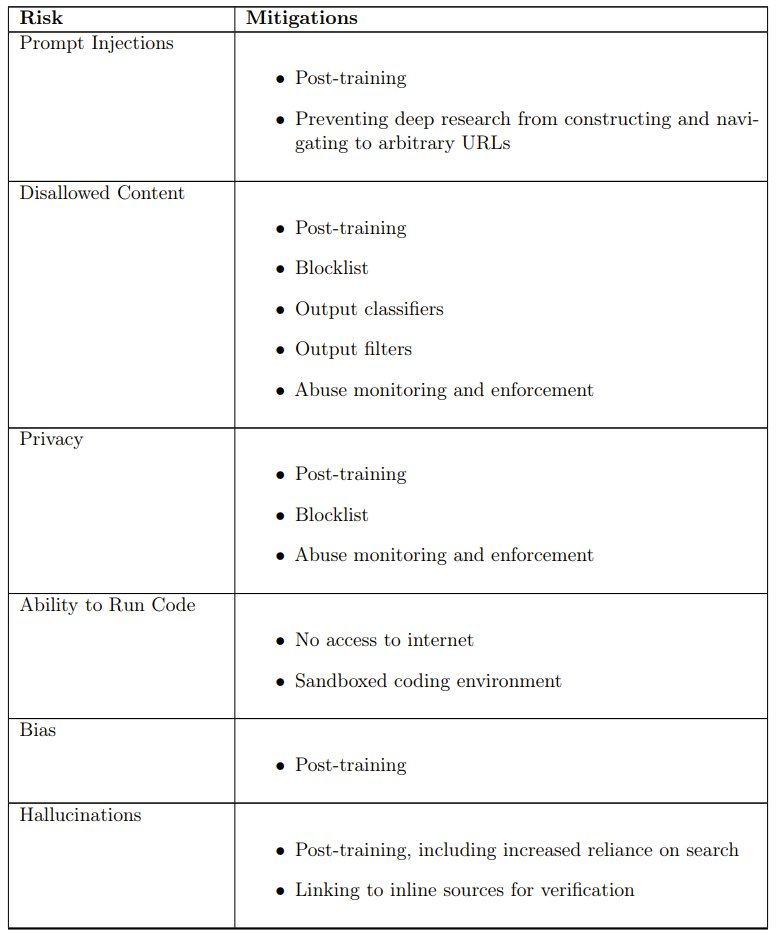
在风险识别、评估和缓解方面,OpenAI 与外部红队成员紧密合作,评估 Deep Research 能力相关的关键风险。红队重点关注领域包括个人信息和隐私、不当内容、受监管建议、危险建议及风险建议。OpenAI 还要求红队测试规避模型安全措施的方法,如提示词注入和越狱。红队成员通过针对性越狱和对抗策略(如角色扮演、委婉表达、使用黑客语言、莫尔斯电码和故意拼写错误等输入混淆)成功规避了部分拒绝行为,这些数据被用于构建评估,并与先前部署的模型性能进行比较。
评估方法上,Deep Research 扩展了推理模型的能力,使其能收集和推理来自不同来源的信息,综合知识并提出新见解。为评估这些能力,OpenAI 调整了现有评估方法,以适应更长、更细腻的答案——这类答案往往更难大规模评判。OpenAI 使用标准的不当内容和安全评估方法对 Deep Research 模型进行评估,并针对个人信息和隐私、不当内容等领域开发了新评估方法。在准备度评估中,他们采用自定义支架来引出模型的相关能力。ChatGPT 中的 Deep Research 还使用了自定义提示的 OpenAI o3-mini 模型来总结思维链,并同样接受了标准的不当内容和安全评估。
观察到的安全挑战、评估和缓解措施已汇总在下表中;具体评估结果请参阅原报告。
准备度框架评估方面,准备度框架是一个动态文档,描述了 OpenAI 跟踪、评估、预测和防范前沿模型灾难性风险的方法。当前涵盖四个风险类别:网络安全、CBRN(化学、生物、放射、核)、说服和模型自主性。只有缓解后(post-mitigation)得分为「中」或以下的模型才能部署,而缓解后得分为「高」或以下的模型才能进一步开发。OpenAI 依据准备度框架对 Deep Research 进行评估,详情请访问:https://cdn.openai.com/openai-preparedness-framework-beta.pdf
具体来看 Deep Research 的准备度评估,该模型基于针对网页浏览优化的 OpenAI o3 早期版本。为更好衡量和引出 Deep Research 能力,OpenAI 评估了以下模型:Deep Research(缓解前),一种仅用于研究目的的 Deep Research 模型(未公开发布),其训练程序与已发布模型不同,且不含公开发布模型中的额外安全训练。Deep Research(缓解后),即最终发布的 Deep Research 模型,包含发布所需的安全训练。OpenAI 测试了多种设置以评估最大能力引出(如,有浏览与无浏览)。根据需要,他们还调整了支架,以最佳方式衡量多项选择题、长答案和智能体能力。为评估每个跟踪风险类别中的风险级别(低、中、高、严重),准备团队使用「indicator」将实验评估结果映射到潜在风险级别。这些 indicator 评估和隐含风险水平经安全咨询小组审查,该小组确定了每个类别的风险水平。当达到或接近 indicator 阈值时,安全咨询小组会进一步分析数据,并确定是否达到风险水平。OpenAI 表示,模型训练和开发的整个过程中都进行了评估,包括模型启动前的最后一次扫描。为最好引出给定类别中的能力,他们测试了多种方法,包括在相关情况下的自定义支架和提示词。OpenAI 也指出,生产中使用的模型的确切性能可能因最终参数、系统提示词等因素而异。
OpenAI 使用标准 bootstrap 程序计算 pass@1 的 95% 置信区间,该程序会对每个问题的模型尝试进行重新采样以近似其指标的分布。默认情况下,将数据集视为固定,仅重新采样尝试。虽然这种方法被广泛使用,但它可能低估非常小的数据集的不确定性,因为它只捕获抽样方差而非所有问题级方差。换句话说,该方法考虑模型在多次尝试中对同一问题的表现的随机性(抽样方差),但不考虑问题难度或通过率的变化(问题级方差)。这可能导致置信区间过紧,尤其当问题的通过率在几次尝试中接近 0% 或 100% 时。OpenAI 也报告了这些置信区间以反映评估结果的内在变化。
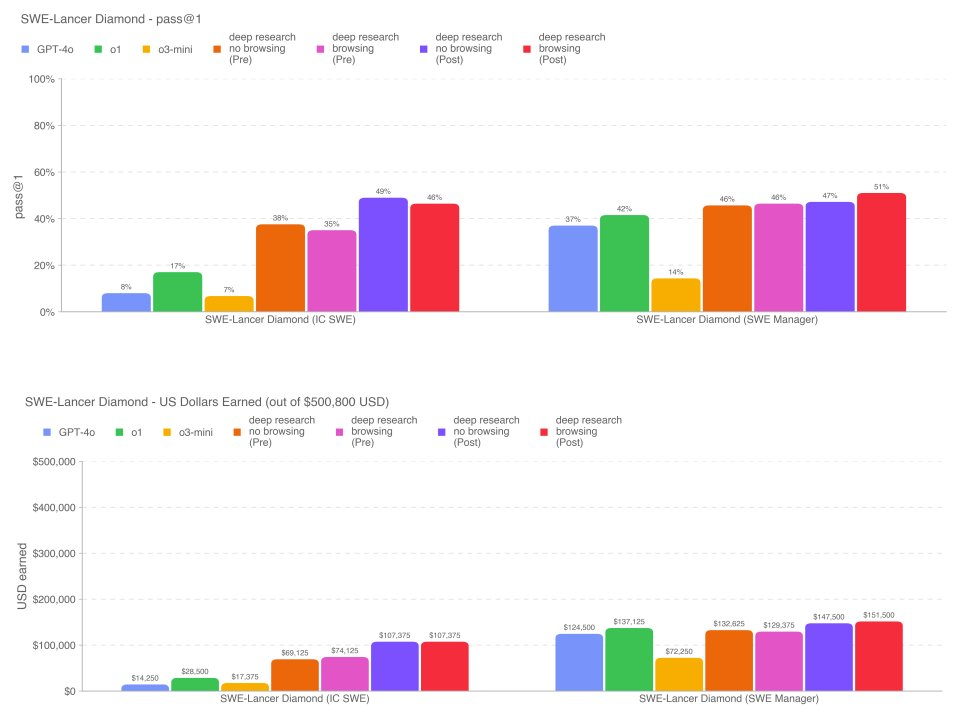
在审查准备度情况评估结果后,安全咨询小组将 Deep Research 模型评级为总体中等风险(overall medium risk)—— 包括网络安全、说服、CBRN、模型自主性均为中等风险。这是模型首次在网络安全方面被评为中等风险。下表展示了 Deep Research 与其他对比模型在 SWE-Lancer Diamond 上的结果。请注意,上图是 pass@1 结果,即测试时每个模型在每个问题上只有一次尝试机会。整体来看,各阶段 Deep Research 的表现均十分出色。其中,缓解后的 Deep Research 模型在 SWE-Lancer 上表现最佳,解决了约 46-49% 的 IC SWE 任务和 47-51% 的 SWE Manager 任务。更多评估细节和结果请参阅原报告。
相关推荐
-
OpenAI开源策略动摇 DeepSeekGrok3夹击下GPT-4.5急推
OpenAI正面临前所未有的双重压力,来自Deepseek和Grok3的双重挑战让这家AI巨头阵脚略显凌乱。2月18日,OpenAICEO山姆·奥特曼在社交媒体X上发起了一项投票,…
-
黄仁勋AI战略解析:英伟达能否再创辉煌
硅基研究室 | 作者 | kiki谢浩 今年的英伟达GTC大会,似乎比去年少了些许狂热,但黄仁勋的AI叙事依旧引人瞩目。在美国加州圣何塞,英伟达的绿色身影依旧是科技圈最耀眼的符号。…
-
从 OpenAI 12 天发布会里,我们看到了行业的四个关键问题
Image source: Generated by AI 历史上第一次有公司会连续开 12 天的产品发布会——当 OpenAI 宣布这个决定之后,全球科技圈的期待值被拉满了。但直…
-
特朗普或将对中国加征50%关税 芯片巨头股价暴跌贸易战升级
(图片来源:Shutterstock US)特朗普“对等关税”政策正式落地,引发全球资本市场剧烈动荡,苹果、英特尔、台积电等AI和芯片行业领军企业股价全面下挫。4月8日最新消息显示…
-
美国芯片EDA巨头断供中国市场 将如何冲击国内产业链
经历两天传闻发酵后,两家美国芯片EDA巨头Synopsys(新思科技)与Cadence(楷登电子)正式官宣确认,美国商务部工业和安全局(BIS)要求其对中国企业断供芯片设计EDA软…
-
汤道生:腾讯打造实用AI,推动大模型产业化落地
腾讯的AI业务布局究竟有何独到之处?在近日举办的腾讯全球数字生态大会上海峰会上,腾讯集团高级执行副总裁、云与智慧产业事业群CEO汤道生围绕大模型的研发与应用,深入剖析了腾讯对AI的…
-
AIGC短剧收益超30万 创作者分享实战经验与商业模式
丁宽和龙新远作为国内AIGC影视创作的先驱者,在国内用AIGC创作短剧的领域属于最早一批的探索者。毕业于北京电影学院动画系的丁宽,历时三个多月打造了国内首部纯AIGC制作的付费短剧…
-
港投公司620亿投资PPIO等超百家公司 加速AI布局
手握超过620亿现金的港投公司正加速布局AI领域,积极寻找优质项目进行投资。5月27日,国内领先的AI算力公司派欧云计算(上海)有限公司(简称”PPIO”)…
-
杭州智算中心:钱塘江畔AI算力引擎助力产业腾飞
党的二十届三中全会对”健全因地制宜发展新质生产力体制机制”作出全面部署,全国各地纷纷响应,积极探索新兴产业与新兴科技带来的生产力革新。2024年,随着…
-
又融20亿,Anthropic估值/收入比超OpenAI,2025两者要打起来了
Image source: Generated by AI Anthropic即将迎来一个重要里程碑。据《华尔街日报》报道,这家成立仅三年的AI公司正在洽谈一轮20亿美元融资,估值…