阿里通义发布国内首个通用推理模型Qwen3系列 超越DeepSeek R1
Qwen 3模型即将发布的消息,已经引发了长达一个月的广泛关注;尤其是最近一周,关于这款模型的猜测在”震撼发布”与”难以落地”之间不断摇摆。直到4月29日凌晨,备受瞩目的Qwen 3终于揭开面纱,官方宣称其性能全面超越DeepSeek R1。杭州某中型数智化企业的算法工程师向《电厂》透露:”近三个月来网络上流传着大量DeepSeek R2的所谓信息,甚至有人预测会在5月推出。Qwen 3选择此时发布,显然是意图抢占市场先机。”在一家国产大模型开放平台任职的刘露则分享道,其团队距离正式获知Qwen3发布消息不到12小时,成员们连夜完成了该系列模型在平台上的部署工作。无论外界如何解读,Qwen 3的问世都标志着开源AI大模型的技术边界再次被突破;对产业链下游应用者而言,这意味着全新的生态选择已然展开。《电厂》注意到,Qwen 3发布仅10小时后,已有开发者基于此推出套壳ChatBot类产品。这些基于Qwen 3的第三方ChatBot产品,图源/网络

国内首个混合推理模型,成本与性能双线超越DeepSeek R1
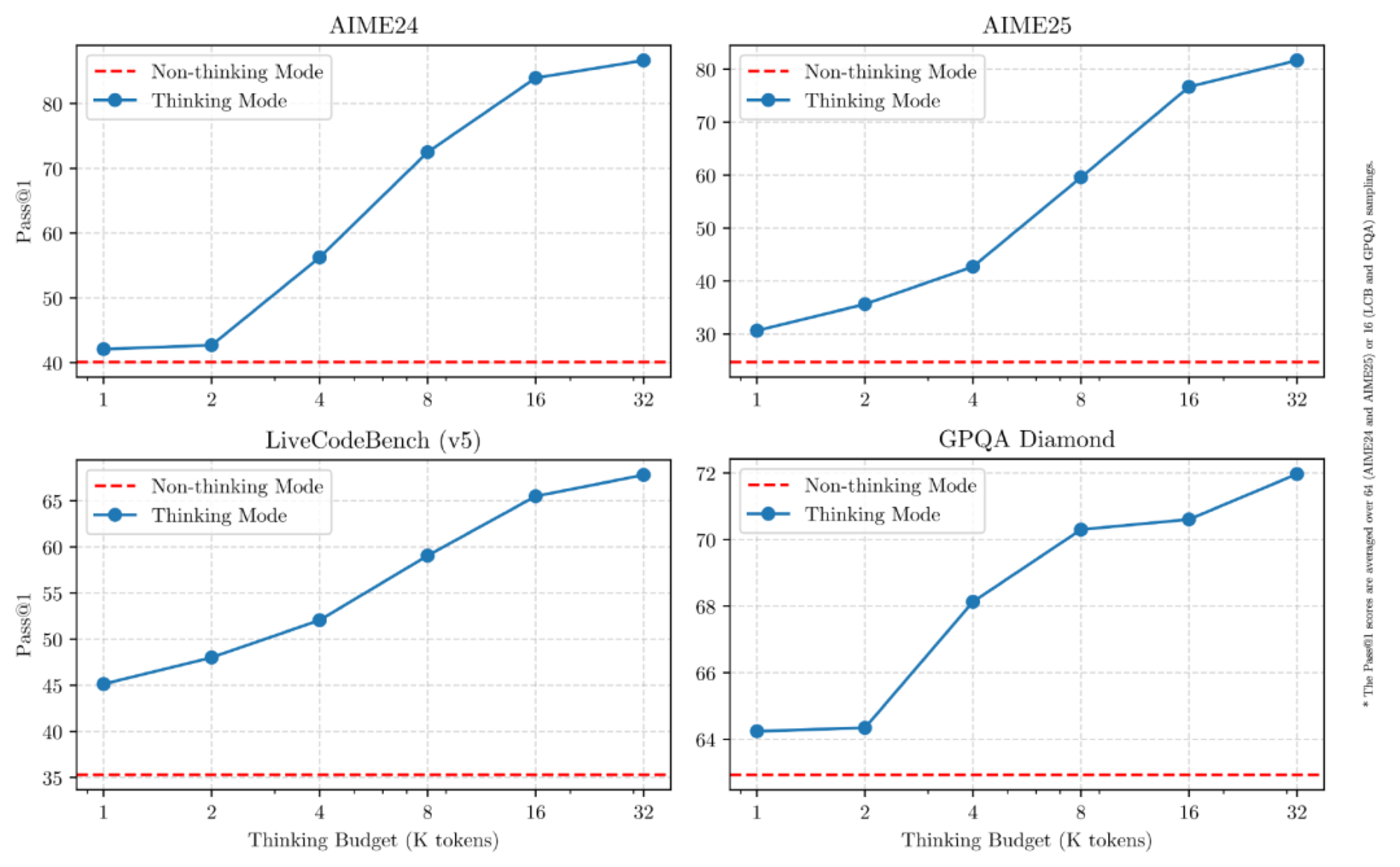
根据阿里云通义千问团队正式公布的信息,Qwen3系列共开源8个模型,其中包含2个MoE(混合专家)架构大模型和6个Dense(稠密)架构大模型。本次发布中最值得关注的技术创新,在于该系列模型同时支持”思考模式”与”非思考模式”两种运行机制。在思考模式下,模型会进行逐步推理,经过深度思考后给出最终答案;这种机制特别适用于需要复杂分析的议题;而在非思考模式中,模型则能提供近乎即时的响应,适合对速度要求高于深度分析的简单任务。换言之,Qwen3打破了DeepSeek R1等思维链模型”慢思考”的单一局限,赋予用户根据需求灵活选择的权利——这正是当前全球大模型市场的重要发展趋势之一。不同基准测试下Qwen3两种思考模式对比,图源/阿里云通义
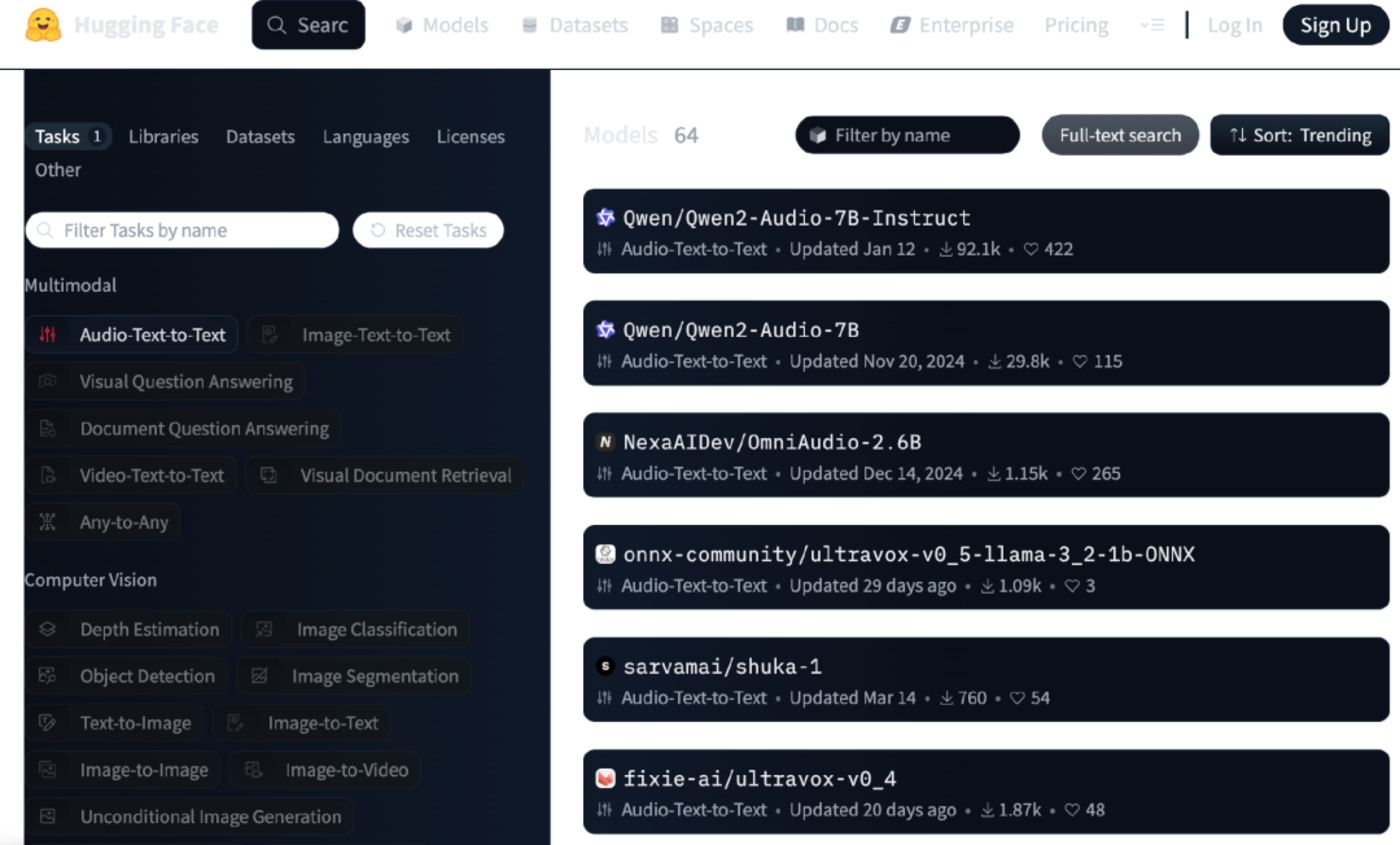
今年2月,由部分OpenAI前员工创立的Anthropic在全球范围内率先推出Claude 3.7 Sonnet混合推理模型,该产品被视为融合了DeepSeek V3(擅长通用任务)与R1(专精推理任务)各自优势的典范。这种混合模式迅速引起行业震动。OpenAI创始人Sam Altman曾公开表示,公司正在研发”能够判断何时需要深度思考且适用于广泛任务的模型”。而Qwen3作为中国首个混合推理模型,正引领着这一重要技术方向。在性能与成本优化方面,Qwen3系列同样表现卓越。例如本次开源的两个MoE模型中,Qwen3-235B-A22B拥有超过2350亿总参数和220多亿激活参数,堪称大型MoE架构;而Qwen3-30B-A3B则是一个约300亿总参数、30亿激活参数的小型MoE模型。MoE(混合专家模型)通过整合多个专家网络,每个专家通常是一个子模型或神经网络模块,各自具备不同能力,可处理不同类型输入。运行时,系统会根据任务类型将数据分配至相应专家处理。DeepSeek V3与R1均采用MoE架构,这种设计优势在于能根据实际需求调用相应模块,显著降低计算成本,这也是”AI界拼多多”DeepSeek提升性价比的核心策略。作为对比,DeepSeek V3与R1的总参数规模达6710亿,激活参数为370亿。性能测试显示,Qwen旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中,全面超越DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等顶级模型。小型MoE模型Qwen3-30B-A3B同样在DeepSeek V3、GPT 4o、谷歌Gemma3-27B-1T等模型中表现突出。六个开源的Dense模型(Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B)均适用于通用任务处理,特别值得一提的是参数量极低的Qwen3-4B模型,在多项任务中展现出超越GPT 4o的优异表现。上述所有模型均在Apache 2.0许可证下开源,该宽松许可协议允许代码修改与再发布(无论作为开源或商业软件)。Qwen3模型还支持119种语言和方言,并针对Agent与代码能力进行了优化,显著增强了MCP支持。开源大模型”王权更迭”Qwen3的发布,距离DeepSeek R1问世已过去3个多月。1月20日,凭借性能媲美OpenAI o1、成本优势显著以及对大模型研发范式的革新,R1迅速成为开源大模型领域的”无冕之王”。在此期间,科大讯飞(星火X1)、百度(文心X1)、OpenAI(o3 mini)、阿里(Qwen-QwQ-32B)、字节(豆包1.5深度思考)等玩家纷纷推出推理模型,但性能仅接近或部分超越R1,未能撼动其王者地位。在大模型领域,数月时间足以完成一代更迭。正是在这样的背景下,市场将目光聚焦于Qwen3。与许多国内参与者不同,早在2024年8月,阿里就已公开宣布加入开源自研模型阵营。在这条由DeepSeek验证可行的市场道路上,Qwen可以说已获得先发优势。至今Qwen系列产品在多个开源榜单中名列前茅。如据全球最大AI开源社区Huggingface 4月29日数据,在audio-text-to-text任务类目下,Qwen的两款模型热度位居前列。Huggingface于2月10日发布的开源大模型榜单”Open LLM Leaderboard”也显示,前十名全部基于Qwen开源模型二次训练的衍生模型。图源/Huggingface
在生态活跃度方面,Qwen同样处于全球领先地位。官方数据显示,从2024年下半年至2025年1月底,基于Qwen系列的衍生模型数量已超过美国Llama系列,累计超过9万个,成为全球规模最大的AI模型家族,超越了Meta旗下的Llama家族。不过与Llama系列相比,Qwen系列开源模型在下载量方面仍存在差距。据Meta首席执行官Zuck Burg今年3月宣布,Llama的下载量已突破10亿次;而Qwen系列的下载量尚在千万级别。在Qwen3发布当天,周靖人接受”晚点”采访时表示,判断”开源生态成熟度”主要有两个指标:”一是开发者选择多样性,二是性能指标表现”。随着Qwen3的发布,这款新模型通过性能指标和成本优势超越DeepSeek R1,以及创新的混合推理模式,登顶全球最强大的开源模型,为Qwen增添了一张重要筹码。但挑战依然存在。接下来DeepSeek R2的发布,将为整个市场注入新的变数。在遵循”赢者通吃”定律的开源市场,竞争远未结束,无论是DeepSeek、Qwen还是Llama,都需持续发力以保持竞争力。值得欣慰的是,尽管战局未定,当前开源大模型的”桂冠”仍属于国产玩家。(注:文中刘露为化名)
相关推荐
-
通义APP崛起背后 阿里AI战略布局深度解析
DataEye研究院观察到,随着腾讯元宝加大营销投入并登顶App Store应用榜首,阿里旗下通义APP也迅速响应,投放素材量呈现爆发式增长。这一现象不仅反映了市场竞争的激烈程度,…
-
OpenAI发布任务功能 ChatGPT变AI管家自动执行任务
OpenAI于北京时间1月15日正式发布了其备受期待的最新功能——”任务”(Tasks),这一创新功能旨在将AI的主动性推向新的高度。目前,该功能已以测试版…
-
医疗复杂推理开源大模型——华佗GPT-o1
Image source: Generated by AI 在医学领域涉及大量复杂的推理过程,从症状分析到疾病诊断,每一步都需要综合考虑众多因素。例如,在诊断一种罕见疾病时,医生不…
-
2024年中国AI发展历程与竞争格局深度解析
2024年注定将成为人工智能发展史上浓墨重彩的一年。在这一年里,中国AI企业展开了一场惊心动魄的追赶与超越之战,从年初紧追GPT-4的步伐,到年中直面GPT-4o的冲击,再到年末与…
-
2024年AI洋模型大突破多模态技术革新性能成本平衡
2024年,人工智能大模型领域迎来了一场颠覆性的变革,其发展速度之快、创新力度之强,堪称科技史上浓墨重彩的一笔。这场由全球科技巨头主导的AI进化大戏,不仅将AI的能力边界一次次推向…
-
抖音创始成员任利锋的GenAI创意社区,完成数千万美元Pre-A轮融资
文章来源:智能涌现 Image source: Generated by AI 《智能涌现》获悉,抖音早期产品负责人、原字节跳动PICO副总裁任利锋(字节花名:卷卷)的创业项目“数…
-
AI写进KPI,“逼疯”打工人
文章来源:定焦One Image source: Generated by AI AI的崛起引发了广泛关注和讨论。有人看到机遇,也有人陷入焦虑。 不少公司开始强制要求员工学习并使用…
-
Flowith Neo:无限智能体创新突破引领AI新潮流
Flowith Neo:重塑AI生成力的无限可能 在AI智能体领域,Manus的”上帝之手”称号正被Flowith旗下的Neo悄然取代。这款智能体背后的团队…
-
黄仁勋AI战略解析:英伟达能否再创辉煌
硅基研究室 | 作者 | kiki谢浩 今年的英伟达GTC大会,似乎比去年少了些许狂热,但黄仁勋的AI叙事依旧引人瞩目。在美国加州圣何塞,英伟达的绿色身影依旧是科技圈最耀眼的符号。…
-
英特尔加大中国汽车供应链投入 芯片巨头亮相2025上海车展
第二十一届上海国际汽车工业展览会(简称“2025上海车展”)正成为全球汽车行业关注的焦点。据WpBull.comAGI了解,本届车展期间,跨国汽车供应商正加速中国市场的本土化战略,…