国产开源模型DeepSeek-V3发布 代码能力媲美Claude性能超越顶尖模型
DeepSeek-V3 全新系列模型现已正式上线并全面开源,用户可通过官网 chat.deepseek.com 体验最新版 V3 模型的强大功能。API 服务同步更新,接口配置无需任何调整,确保无缝衔接。值得注意的是,当前版本暂不支持多模态输入输出,但已展现出卓越的性能表现。


性能对齐海外顶尖闭源模型
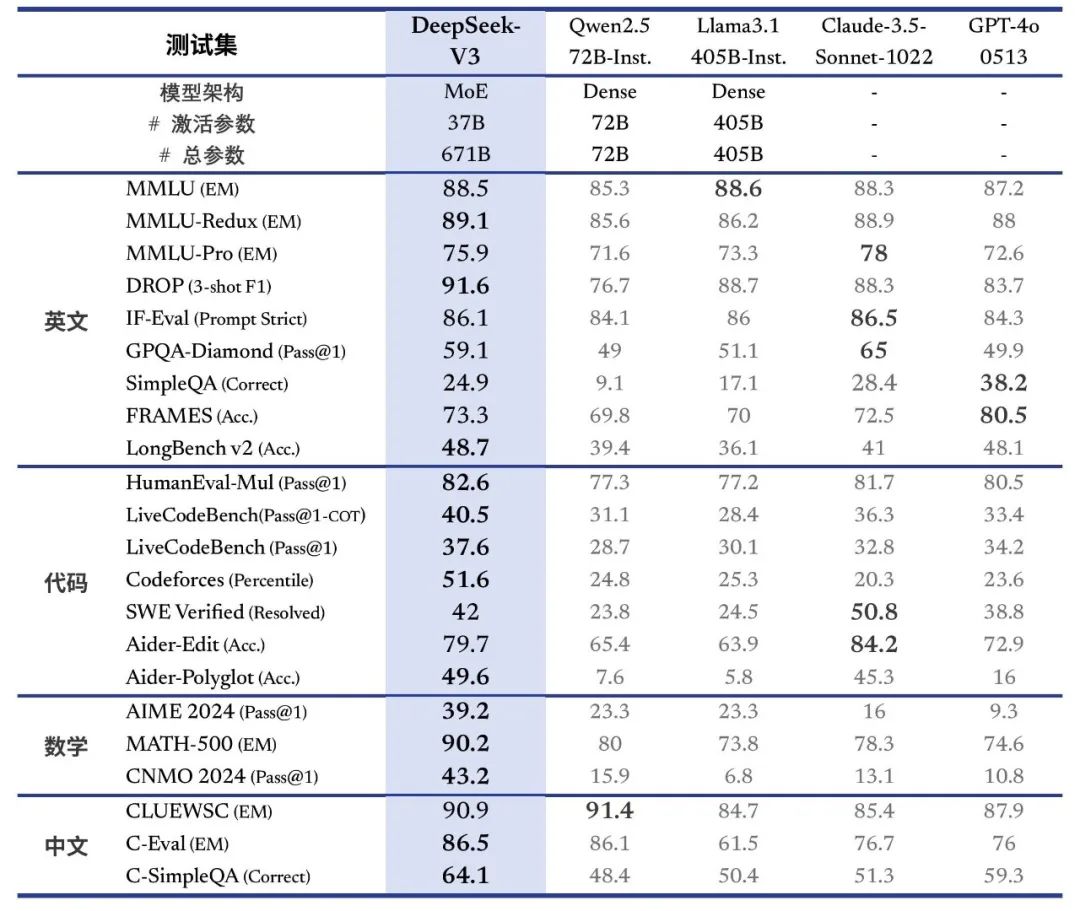
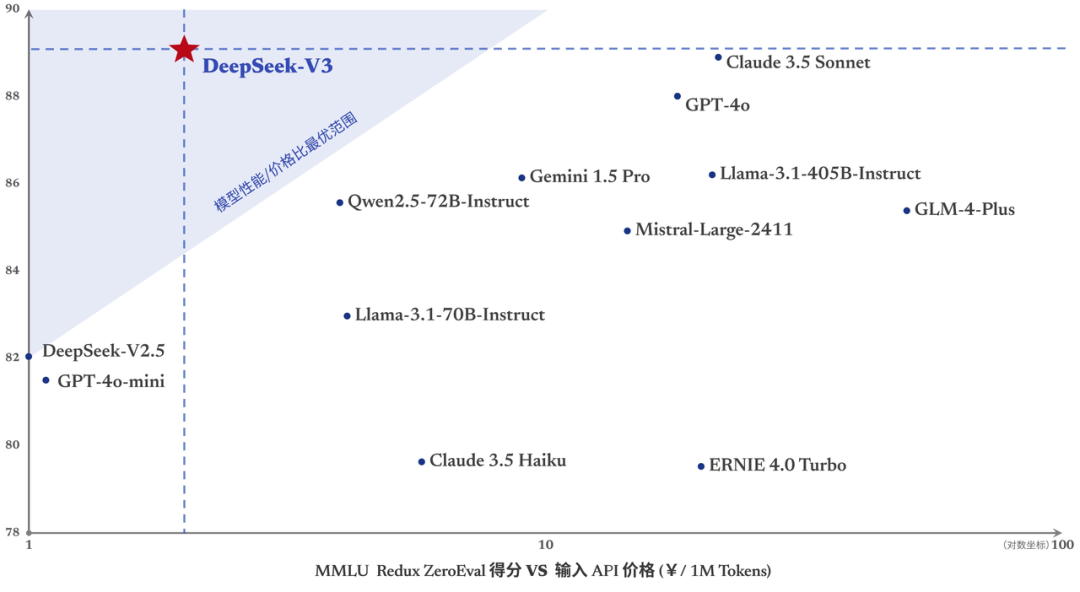
DeepSeek-V3 是我们自主研发的 MoE 模型,拥有 671B 参数规模,激活参数达 37B,在 14.8T token 上完成预训练。其性能表现已达到国际领先水平,与 GPT-4o 及 Claude-3.5-Sonnet 等闭源模型不相上下。详细技术论文请参考:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
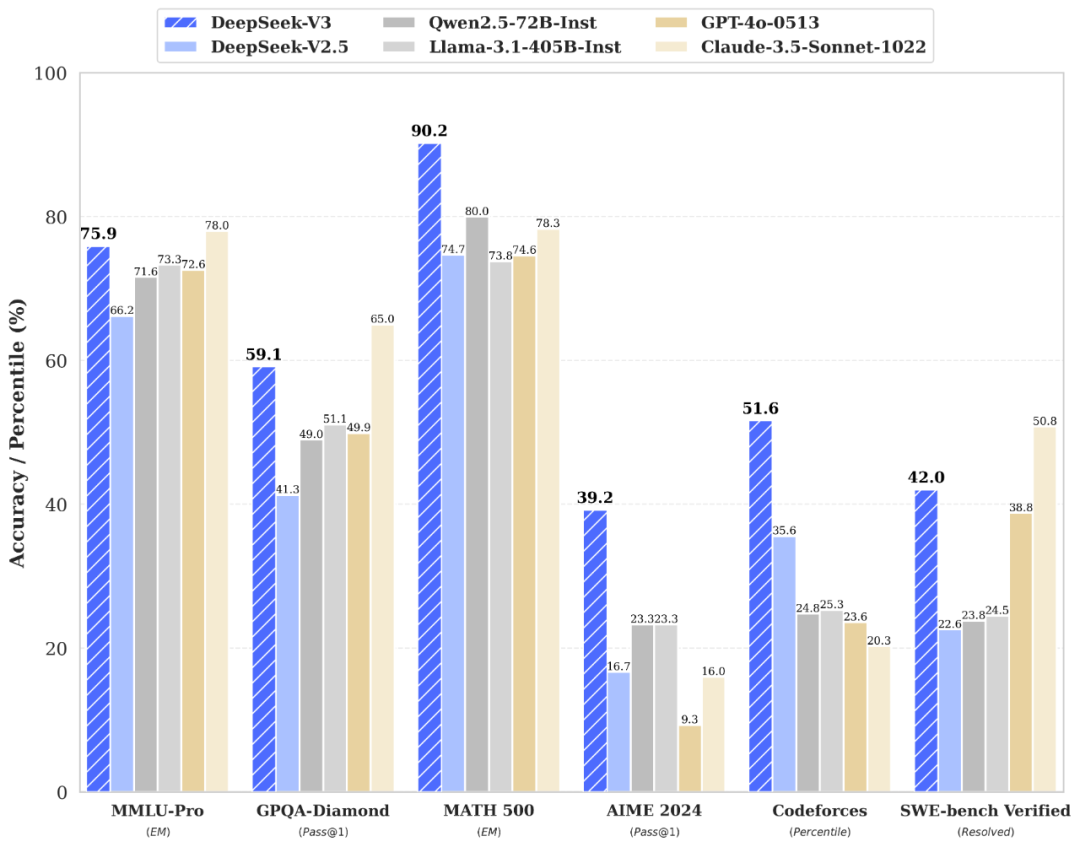
多项评测成绩超越主流开源模型
在各类权威评测中,DeepSeek-V3 多项指标超越 Qwen2.5-72B 和 Llama-3.1-405B 等开源模型,尤其在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上表现突出,显著优于前代 DeepSeek-V2.5,接近 Claude-3.5-Sonnet-1022 的顶尖水平。
长文本处理能力突出
在 DROP、FRAMES 和 LongBench v2 等长文本测评中,DeepSeek-V3 均展现出超越其他模型的平均表现,为长文本理解与生成提供强大支持。
代码能力全面领先
在算法类代码场景(Codeforces)中,DeepSeek-V3 远超市面上所有非 o1 类模型;在工程类代码场景(SWE-Bench Verified)中,其表现已逼近 Claude-3.5-Sonnet-1022。
数学能力大幅提升
在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)等数学测评中,DeepSeek-V3 大幅领先于所有开源闭源模型,展现出卓越的逻辑推理能力。

中文能力表现优异
在教育类测评 C-Eval 和代词消歧等评测集上,DeepSeek-V3 与 Qwen2.5-72B 表现相近;在事实知识 C-SimpleQA 上则更为领先,充分彰显中文理解与生成优势。

生成速度提升至 3 倍
通过算法与工程创新,DeepSeek-V3 的生成吞吐量从 20 TPS 大幅提升至 60 TPS,较 V2.5 模型实现 3 倍性能飞跃,为用户带来更流畅高效的使用体验。
API 服务价格调整
为匹配 V3 模型的卓越性能,API 服务定价将调整为:每百万输入 tokens 0.5 元(缓存命中)/ 2 元(缓存未命中),每百万输出 tokens 8 元。同时推出 45 天优惠体验期:即日起至 2025 年 2 月 8 日,DeepSeek-V3 API 服务价格将维持在每百万输入 tokens 0.1 元(缓存命中)/ 1 元(缓存未命中),每百万输出 tokens 2 元,新老用户均可享受。
开源权重与本地部署支持
DeepSeek-V3 采用 FP8 训练并开源原生 FP8 权重,SGLang、LMDeploy 等框架第一时间支持原生 FP8 推理,TensorRT-LLM、MindIE 实现 BF16 推理。我们还提供 FP8 到 BF16 的转换脚本,方便社区适配与拓展。模型权重下载及本地部署详情:https://huggingface.co/deepseek-ai/DeepSeek-V3-Base
秉持开源精神与长期主义
“以开源精神和长期主义追求普惠 AGI”是 DeepSeek 的核心理念。我们欣喜地与社区分享模型预训练的阶段性成果,见证开源模型与闭源模型能力差距的持续缩小。未来,我们将基于 DeepSeek-V3 打造深度思考、多模态等更丰富功能,并持续与社区分享最新探索成果,共同推动 AI 技术进步。
相关推荐
-
Meta官宣2025大会:AI眼镜成焦点 Meta押注未来科技
作为全球XR领域的领军企业,Meta的每一步动态都备受业界瞩目。近日,Meta正式宣布2025年Meta Connect大会将于9月17日盛大召开,这一消息再次点燃了全球科技界的期…
-
美国商务部撤销拜登AI扩散规则 加强全球芯片出口管制
美国政府在人工智能与加密货币领域的负责人戴维·萨克斯(David Sacks)宣布,由美国前总统拜登签署的《AI扩散规则》已被正式暂停执行。据WpBull.comAGI最新消息,美…
-
DeepSeek大模型一体机市场火爆 炒作还是真需求解析
大模型正颠覆传统一体机市场格局。过去一体机因需求低迷备受冷落,如今却迎来爆发式增长。据IDC统计,市场上已涌现近百家厂商推出AI一体机产品,涵盖新华三等服务器厂商、京东云等云服务商…
-
AI社交大战爆发 朋友圈成新战场
短短两个月,国内AI原生应用的排行榜经历了数次颠覆性变化。春节过后,DeepSeek凭借其”低成本、高性能”的优势迅速在全球崭露头角,成为AI领域的黑马。而…
-
阿里Qwen3系列开源:性价比多模态大模型矩阵抢市场
阿里云Qwen3系列重磅发布:重塑大模型开源标准 凌晨时分,阿里云正式揭晓了备受瞩目的Qwen3系列模型,一口气开源了从0.6B到235B共8款模型,包括2个MoE大模型和6个De…
-
马斯克AI游戏画饼 腾讯等布局赛道
近期,AI游戏在互联网领域掀起热潮,成为备受瞩目的焦点。马斯克再次确认将成立AI游戏工作室,并陆续转发多款基于xAI旗下大模型Grok 3制作的游戏产品。然而,自去年以来,尽管马斯…
-
马克·安德森访谈:DeepSeek开源AI重塑权力结构
美国知名播客Invest Like the Best近期再次访谈了Andreessen Horowitz的联合创始人Marc Andreessen,深入探讨了AI如何重塑技术和地缘…
-
人形机器人,OpenAI要亲自下场了!
文章来源:财联社AI daily Image source: Generated by AI 据媒体报道,在过去的一年里,OpenAI多次暗示自己对机器人项目重燃热情:投资于开发机…
-
英特尔出售Altera51%股权给银湖资本 10年估值缩水47.6%
英特尔正式剥离Altera FPGA业务 估值暴跌47.6亿美元 (图片来源:WpBull.comAGI编辑林志佳拍摄) 芯片巨头英特尔近日宣布了一项重大战略调整,正式剥离其十年前…
-
小红书新做的这个AI搜索,有Perplexity们都眼馋的能力
Image source: Generated by AI 翻开这本“小红书”,哪里不会“点”哪里。 这可不是学习机,而是小红书最近正在内测的一款AI搜索产品“点点”。打开小红书的…