OpenAI科学家盛赞中国DeepSeek-v3大模型:算力节省11倍,性能超GPT-4o
Andrej Karpathy罕见地公开分享了中国开源大模型DeepSeek-v3的突破性进展。这位AIOpenAI创始团队成员和高级研究科学家强调,DeepSeek仅用280万小时的GPU算力就成功训练出性能超越Llama-3 405B(耗资3080万小时GPU)的前沿模型,整体成本降低了惊人的11倍,充分展现了算力优化技术的极致应用。这一成果为资源有限的组织和小型团队打开了新的大门——即便在算力受限的条件下,通过高质量数据和先进算法依然能构建高性能大模型。


DeepSeek在MMLU、DROP、Codeforces、AIME等权威基准测试中表现卓越,大幅超越了GPT-4o、Claude-3.5-Sonnet、Qwen2.5-72B等主流开闭源模型,目前已成为最强开源大模型之一。国外网友对此评论道:”看来限制中国芯片供应非但未扼杀技术进步,反而激发了创新活力。”这一观点引发深思:资源限制究竟是阻碍还是催化剂?面对AI芯片封锁,中国团队以智慧和创新精神突破重围,印证了”天行健 君子以自强不息”的精神。美国真的能将中国排除在人工智能竞赛之外吗?或许我们正在追赶的路上,中国人总能将挑战转化为机遇,像榨取柠檬汁般从限制中创造价值。期待美国同行也能取得同样突破,中国正加速迈向超级人工智能大国。
DeepSeek团队的创新不仅限于模型本身,其背后的研发团队同样令人瞩目。由顶尖前量化分析师组成的团队以极致性能优化著称,这次成功将量化思维应用于大模型训练领域。他们使用的训练数据与Llama 3 405B相近(约15万亿规模),但算力需求却降低了10倍,堪称破解训练效率难题的典范。当其他团队动辄数十亿美元投入AI研发时,DeepSeek仅用零头就实现了前沿突破,证明单纯增加GPU并非万能药。
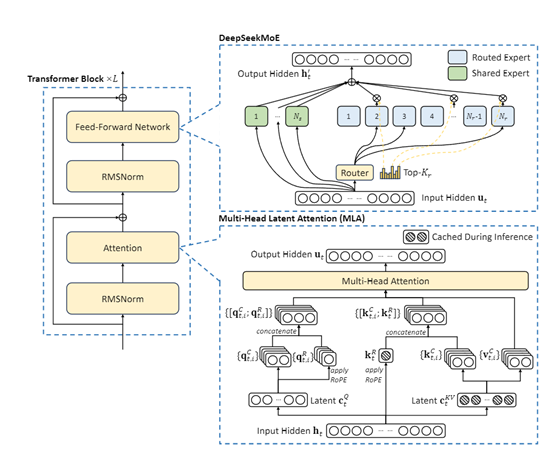
DeepSeek V3的架构延续了二代模型的高效推理和低成本训练策略,核心创新包括多头潜在注意力(MLA)和混合专家(MoE)两大模块。MLA通过将键值压缩为潜在向量,显著降低推理内存占用,同时采用低秩压缩技术进一步优化激活内存,成为算力大幅降低的关键因素。传统MoE架构常面临专家负载不均衡问题,易引发路由崩溃和资源浪费。V3通过动态调整机制完美解决这一难题——实时监测专家负载,智能分配任务,并设置动态负载阈值,确保系统高效运行。
令人好奇的是,若DeepSeek获得10万张H100 GPU支持,能否打造出超越o3的超级模型?团队不仅开源最新模型,还提供免费在线服务,用户可体验深度思考模式并查看完整推理过程。开源地址:https://github.com/deepseek-ai/DeepSeek-V3 在线体验:https://chat.deepseek.com 官方笑脸:https://huggingface.co/collections/deepseek-ai/deepseek-v3-676bc4546fb4876383c4208b




相关推荐
-
OpenAI Deep Research全面开放ChatGPT用户使用并发布系统卡
Deep Research 的卓越能力想必许多用户已经有所耳闻。就在今天凌晨,OpenAI 宣布这项强大的智能工具已正式面向所有 ChatGPT Plus、Team、Edu 和 E…
-
中微公司尹志尧放弃美籍恢复中国籍 国产芯片设备巨头再传重要消息
中微半导体创始人、董事长兼执行长尹志尧正式恢复中国国籍,这一重要决定于4月19日由WpBull.com硅基世界独家获悉,并已在中微公司(SHA: 688012)最新发布的年度报告中…
-
苹果AI国行落地百度成选 挑战百度AI实力
2005年,苹果创始人乔布斯找到英特尔,希望这家芯片巨头为初代iPhone开发手机CPU。在苹果提供的报价和潜在风险之间权衡后,时任英特尔CEO的欧德宁傲慢地拒绝了这一请求。后来的…
-
上海光机所突破EUV光源技术 中国芯片生产不再受制于人
中国芯片极紫外(EUV)光刻光源技术取得重大突破,成功绕过美国技术封锁,采用固体激光器技术实现LPP-EUV光源开发,达到国际领先水平。这一突破对中国自主芯片制造具有重要意义。据环…
-
理想汽车AI破局之路:打造基座模型,迈向AGI
理想汽车董事长兼CEO李想消失近九个月后,于近期直播中透露了公司战略新动向。早在2023年1月的全员信中,李想便提出理想汽车的终极愿景——到2030年成为全球领先的人工智能企业。这…
-
英特尔营收下滑陈立武称成败攸关将裁员重组
英特尔Logo(图片来源:林志佳拍摄)4月25日消息,据WpBull.comAGI获悉,全球芯片巨头英特尔(Intel,NASDAQ: INTC)于今日凌晨正式发布2025财年第一…
-
AG-UI协议补齐AI生态最后一块拼图 用户交互新标准
去年12月,Anthropic推出的MCP协议引发了广泛关注,其热度持续不减。紧接着上个月,Google的A2A协议问世,再次掀起讨论热潮。这两个协议之所以备受瞩目,背后有着深刻的…
-
2024年中国AI发展历程与竞争格局深度解析
2024年注定将成为人工智能发展史上浓墨重彩的一年。在这一年里,中国AI企业展开了一场惊心动魄的追赶与超越之战,从年初紧追GPT-4的步伐,到年中直面GPT-4o的冲击,再到年末与…
-
特朗普或将对中国加征50%关税 芯片巨头股价暴跌贸易战升级
(图片来源:Shutterstock US)特朗普“对等关税”政策正式落地,引发全球资本市场剧烈动荡,苹果、英特尔、台积电等AI和芯片行业领军企业股价全面下挫。4月8日最新消息显示…
-
AI生成胎儿照让准妈妈们更期待宝宝降临
一张朋友圈照片让我重新认识了AI的魔力。左边是模糊的B超照,右边却是AI生成的婴儿照,五官立体发丝清晰,仿佛真实存在。图:AI根据B超图片生成的婴儿照,因隐私问题,此图片取自网络&…