Kimi深夜发布k1.5多模态模型性能超GPT-4o和Claude 3.5 Sonnet
编辑 | 伊风 出品 | 51CTO技术栈(微信号:blog51cto)
昨晚十点,Kimi推送了一条令人瞩目的消息。他们以平静的姿态发布了一款SOTA模型——k1.5多模态思考模型,其性能表现堪称逆天。


k1.5在short-CoT模式下,多项能力大幅超越了全球短思考SOTA模型GPT-4o和Claude 3.5 Sonnet,领先幅度高达550%。在long-CoT模式下,其数学、代码、多模态推理能力也达到了长思考SOTA模型OpenAI o1满血版的水平。更令人惊喜的是,这是Kimi首次发布训练报告《Kimi k1.5:借助大语言模型实现强化学习的Scaling》,报告长达25页。
k1.5在强化训练方面做了大量创新,尤其是Long2short技术,让许多技术者眼前一亮。这份报告堪称“压箱底”的干货,高效思维链也被许多人视为即将引领新潮流的技术。github链接:https://github.com/MoonshotAI/Kimi-k1.5。
作为专注产品侧的闭源模型,Kimi能主动分享技术细节,实属可贵。在越来越封闭的AI领域,这一点尤为难得。
与此同时,开源顶流DeepSeek也推出了推理模型——DeepSeek-R1,硅谷AI圈再次掀起技术研究的浪潮。
Kimi此次发布k1.5也延续了惯例,测试报告一经发布,C端产品便陆续上线,用户可通过切换模型体验k1.5。
遗憾的是,目前k1.5尚未大规模灰度开放,小编也未找到网友的实测案例。只能满怀期待,静候更多用户体验。
### 1. k1.5到底有多强
作为SOTA模型,Kimi k1.5的性能表现令人瞩目。

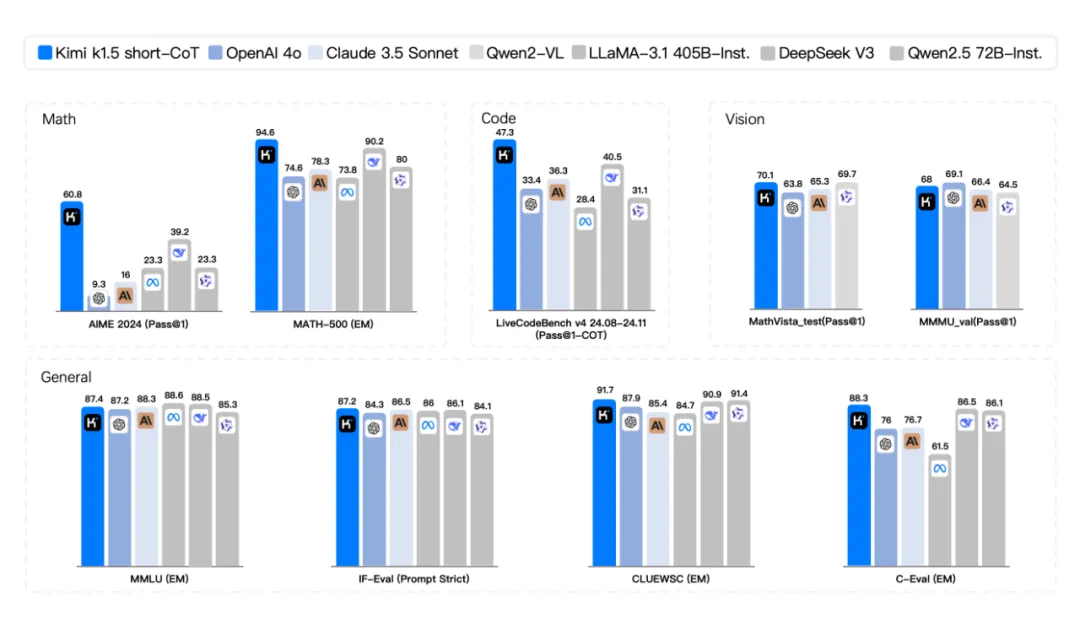
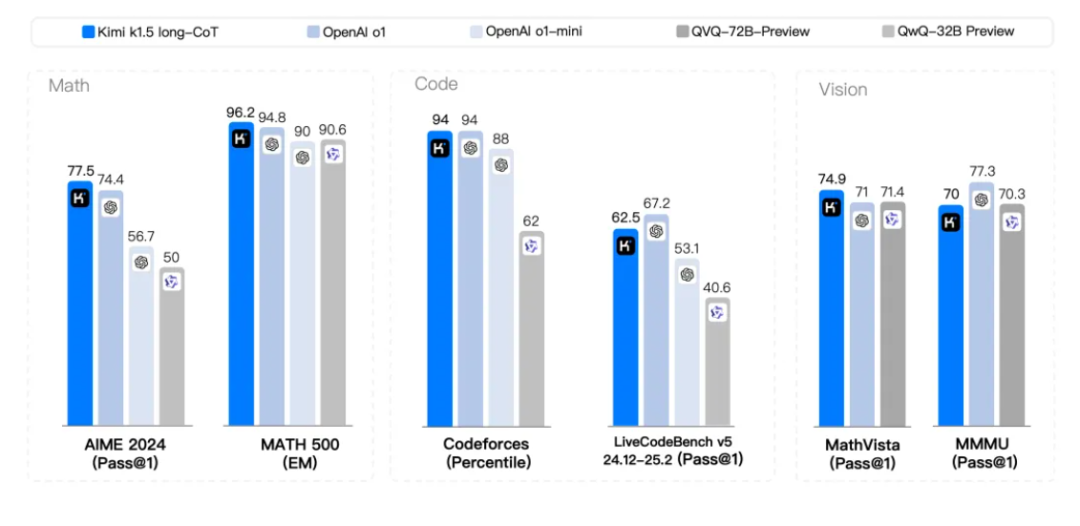
首先,短链思维链是k1.5的最大亮点。短链思维链的核心在于简单高效,通过生成一个概括性的中间推理步骤来帮助回答问题。k1.5的数学、代码、视觉多模态和通用能力,大幅超越了GPT-4o和Claude 3.5 Sonnet,领先550%。除了视觉能力稍显不足,其他方面堪称超前。
在长链思维链模式下,k1.5的数学、代码、多模态推理能力依然与OpenAI o1正式版看齐。长链思维链专注于复杂问题,如数学证明、复杂因果关系、推理等,需要模型多思考几步,生成更丰富的逻辑推理链条。从报告来看,k1.5与OpenAI的较量可谓旗鼓相当。
更有含金量的是,这可能是OpenAI之外公司首次实现o1正式版的多模态推理性能。
### 2. SOTA之路:Kimi模型是如何训练出来的
Kimi在强化学习方面展现出强大的实力,越战越勇。去年11月发布k0-math数学模型,次年1月推出k1视觉思考模型,如今k1.5多模态思考模型的横空出世,让人不禁感叹Kimi下了一盘大棋。
我们先来看Kimi官方给出的k1.5的几个关键词,再深入探讨其最大的创新技术Long2short。
#### 2.1 k1.5的关键词
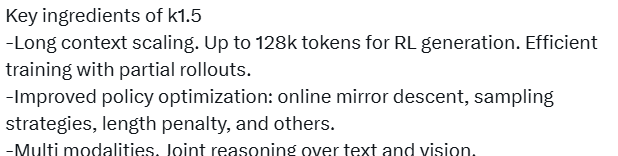
k1.5的三个关键词:长上下文扩展、改进的策略优化、多模态能力。

**长上下文扩展**。Kimi将RL的上下文窗口扩展到128k,并观察到随着上下文长度的增加,性能持续提升。这一关键思想是使用部分展开(partial rollouts)来提高训练效率,即通过重用大量先前的轨迹来采样新的轨迹,避免从头开始生成新轨迹的成本。这一突破意味着强化学习,让大模型向更复杂和长时记忆任务迈进了一步。
**改进的策略优化**。Kimi推导出了long-CoT的RL公式,并采用在线镜像下降的变体进行稳健的策略优化。该算法通过有效采样策略、长度惩罚和数据配方的优化进一步改进。

**多模态能力**。模型在文本和视觉数据上联合训练,具备联合推理两种模态的能力。数学能力出众,但由于主要支持LaTeX等格式的文本输入,对依赖图形理解能力的几何图形题应对不足。
#### 2.2 long2short方法

k1.5的Long2short方法值得技术者深入学习。这一创新证明,Long-CoT模型的推理先验知识可以顺利转移到Short-CoT模型中。Short-CoT模型不仅效果显著提升,还避免了Long-CoT的高token消耗。
在AIME上达到60.8分,MATH500上达到94.6分,LiveCodeBench上达到47.3分,k1.5在短链思维推理方面大幅超越了GPT-4和Claude Sonnet 3.5(提升550%)。报告还披露了Long-CoT改进Short-CoT的具体实现方法,包括模型合并、最短拒绝采样、DPO、long2short强化学习等多种方法。
### 3. 同天之内两家国产o1绝不是巧合
前脚DeepSeek-R1发布,作为高性能AI推理模型,对标OpenAI o1正式版。开源模型R1已开源,模型权重可在Hugging Face上获取。加上之前V3的惊艳表现,声量极高。

开源地址:https://huggingface.co/deepseek-ai/DeepSeek-R1。英伟达大佬Jim Fan感叹,R1不仅开放了模型,技术的共享同样重要。
k1.5的横空出世,让硅谷AI圈再次掀起技术热潮。Jim Fan预言,2025年强化学习将王者归来。
Jim Fan总结了两个模型的不同之处:
**DeepSeek**:采用AlphaZero方法,纯粹通过RL引导,无需人工输入(冷启动)。权重采用MIT许可,思想领导力十足;Kimi尚未发布模型。
**Kimi**:在MathVista等基准测试中展现强大多模态性能,这些测试要求对几何、智商测试等有直观理解。论文中包含大量系统设计细节:RL基础设施、混合集群、代码沙箱、并行策略;以及学习细节:长上下文、CoT压缩、课程、抽样策略、测试用例生成等。
发布k1.5后,Kimi发布了K系列的未来计划。从k0-math数学模型,到k1视觉思考模型,再到k1.5多模态推理,Kimi仿佛在一路升级打怪。
期待2025年,更多模型厂带来惊艳的新成果。
相关推荐
-
博乐仁:中国创新引领全球增长 西门子助力AI转型
WpBull.comAGI 3月23日消息,由国务院发展研究中心主办、中国发展研究基金会承办的中国发展高层论坛2025年年会于今日上午在北京隆重开幕。本届论坛聚焦”全面…
-
Gemini 2.5弯道超车揭秘:AI强化学习如何引领大模型新突破
Gemini 2.5 Pro的崛起:谷歌大模型的底层逻辑与竞争优势 谷歌最新发布的Gemini 2.5 Pro在各项评测中表现卓越,成为当前大模型领域的佼佼者。硅谷101创始人泓君…
-
AI教父李开复的大模型创业路:争议与转型
如果要在大模型领域选出一位兼具行业影响力和行业争议度的人物,那李开复一定榜上有名。2023年中决定亲自下场担任零一万物CEO时,李开复一度被业内拿来跟王慧文做比较,讨论两者的创业项…
-
重大突破!微软发布“自我进化”,帮小模型超OpenAI-o1
Image source: Generated by AI 微软亚洲研究院发布了一种创新算法——rStar-Math。 rStar-Math通过代码增强CoT、蒙特卡洛树搜索等,可…
-
DeepSeek驱动MaaS变革:大厂加码中小厂离席
月初,潞晨科技创始人公开质疑MaaS(模型即服务)是”最差的商业模式”,并宣布停止DeepSeek API服务,同时透露满血版DeepSeek-R1月亏损超…
-
字节通用Agent表现平平 阿里百度竞相布局AI智能体市场
2025年伊始,人工智能领域最引人注目的焦点无疑是DeepSeek和Manus,后者更是被誉为首个”通用AI Agent”(智能体),其邀请码价格一度飙升至…
-
OpenAI密谋禁用DeepSeek AI,全球多国紧急响应
OpenAI又双叒叕对DeepSeek发起攻击了!就在3月13日,这家科技巨头向美国政府提交了一份长达15页的举报信,声称DeepSeek R1存在重大风险,要求当局采取行动。更令…
-
AI数字人告别印钞机时代 转向务实降本新阶段
2024年3月,数字人服务商阿杰清晰地记得公司举办的一场分享会。那天的会议室座无虚席,挤满了焦虑的老板们。他们的焦虑具体化为一个个问题——“无人直播是否等同于录播?”“创始人IP如…
-
世航智能获5000万融资 聚焦水下机器人产业化
金沙江创业投资基金主管合伙人朱啸虎近期宣布批量退出人形机器人项目后,却将目光投向了水下机器人领域。5月16日,据WpBull.comAGI独家获悉,水下机器人公司世航智能成功完成天…
-
AI视频赛道遇冷 海螺等创业公司寻求差异化突破
近期关于AI视频的几则新闻接连发生,引发出诸多值得深思的现象。Sora的推出并未带来预期的轰动,反而遭遇了诸多吐槽和不尽如人意的评价。这一局面让可灵、海螺等同类产品研发团队得以喘息…