DeepSeek V3革新AI路径:低成本模型能否挑战GPT-4?
2024年末,DeepSeek V3模型横空出世,迅速引爆AI领域。作为一款开源模型,DeepSeek V3拥有高达6710亿参数,却能在性能上与GPT-4和Claude 2等闭源顶级模型相媲美。更令人惊叹的是,据深度求索报道,它仅用278.8万GPU小时就完成了训练,将训练成本降至令人难以置信的”白菜价”。这一突破性成果引发了业界的广泛关注,人们开始思考:DeepSeek V3是否为全球,尤其是算力资源匮乏的中国AI界,开辟了一条更具经济性的发展道路?


然而,质疑声也随之而来。有观点认为,DeepSeek V3的宣传存在夸大成分。例如,有人指出该模型在训练过程中使用了幻方科技自家的R1模型(对标OpenAI的O1模型)生成数据,这部分消耗是否应该计入总成本?此外,仅从训练成本降低的角度来看,并不代表推理需求会减少,大厂可能只是用更经济的方式探索模型极限能力。而推理需求实质上远大于训练需求,尤其是当用户基数扩大时。DeepSeek V3使用大量合成数据,其数据配比需要大量预实验,合成和清洗数据同样消耗算力。此外,DeepSeek V3的MoE架构虽然每个专家可单独训练,但相比密集架构仍需优化。当前消费者和企业界最常用的仍是GPT-4和LLaMA3等模型,这些宣传成绩的可信度值得商榷。

尽管存在争议,DeepSeek V3的技术创新仍值得关注。其采用的多头潜在注意力(MLA)机制通过低秩联合压缩注意力键和值,大幅减少推理过程中的键值缓存需求,显著降低显存占用。具体而言,MLA仅需缓存压缩后的潜在向量和解耦的旋转位置编码键,相比传统多头注意力机制节省了大量资源。而混合专家架构(MoE)则是DeepSeek V3的最大亮点——尽管模型参数高达6710亿,但每次仅激活约370亿参数。动态路由机制配合细粒度专家划分和共享专家隔离,更创新地采用无辅助损失负载均衡策略,通过为每个专家引入偏置项动态调整选择概率,在保持性能的同时实现专家负载均衡。
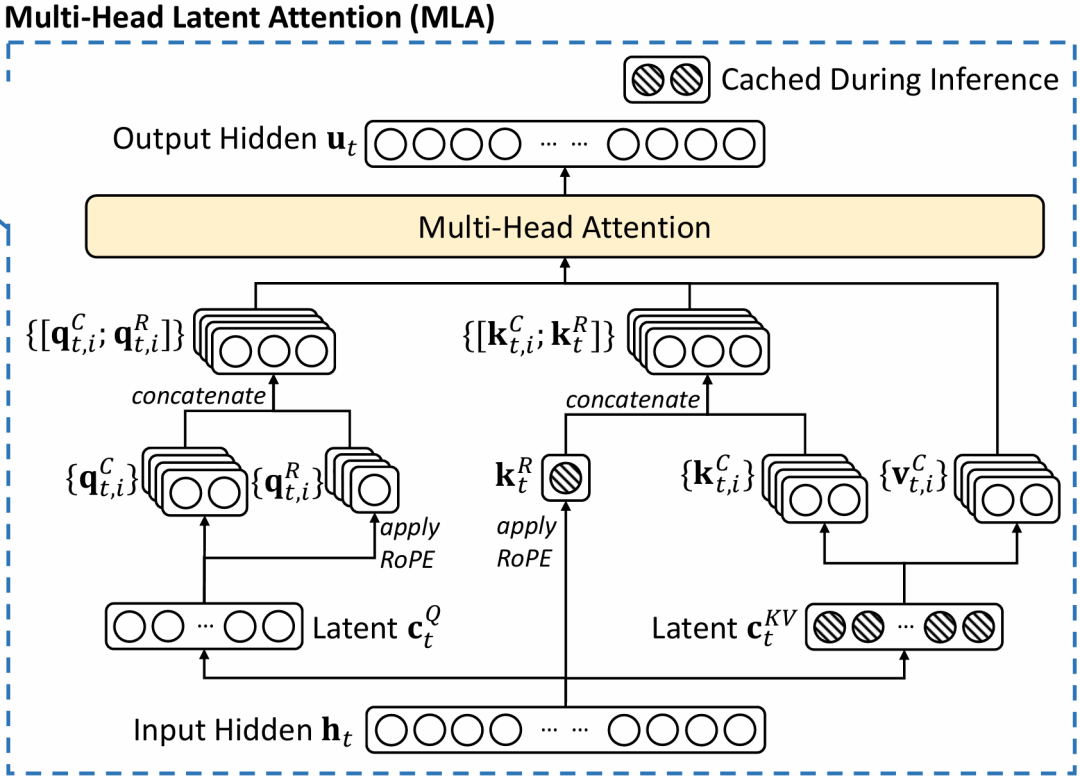
无论最终事实如何,DeepSeek V3的最大价值在于为当前高能耗、拼钱拼卡拼能源的大模型军备竞赛提供了全新思路。类似地,人工智能专家朱松纯提出的”鹦鹉学舌”向”乌鸦喝水”的大模型范式演进,也引发深入思考。传统”鹦鹉范式”依赖大数据和深度学习,模型虽能模仿重复但缺乏真正理解和推理能力;而”乌鸦范式”则强调”小数据、大任务”,注重自主推理和长期洞察,具有低功耗特点,对数据与算力要求更低,或将成为AI未来发展方向。
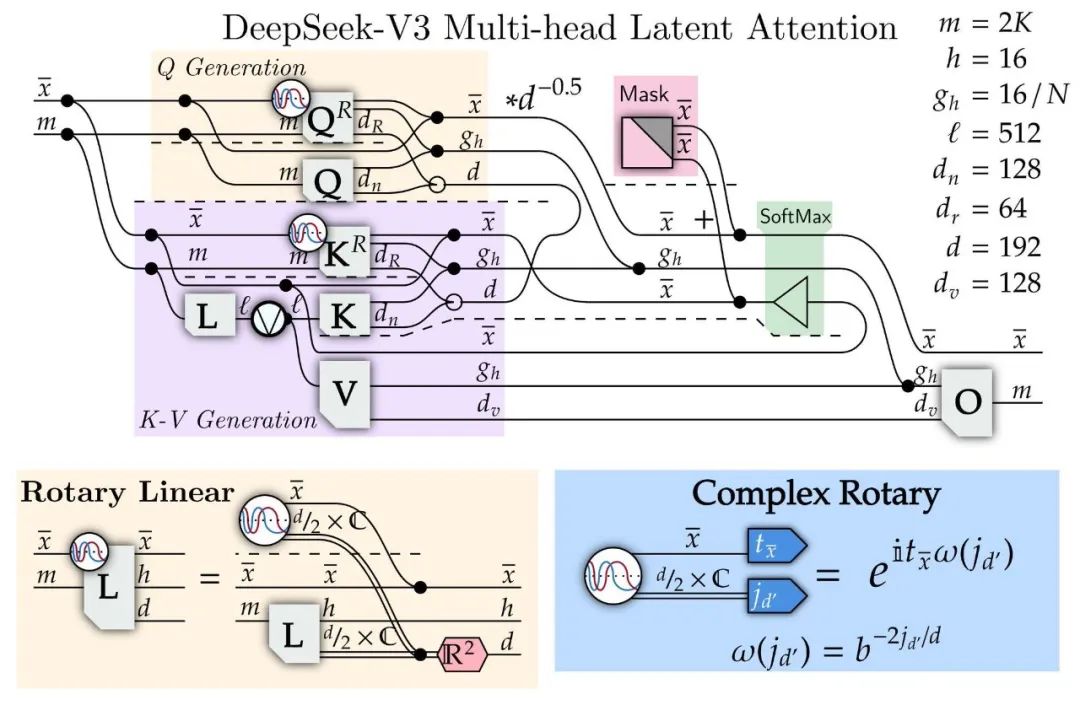
从乐观角度看,DeepSeek V3通过蒸馏和优化在推理能力上实现突破,证明AI已超越简单语言模仿阶段,逐渐具备自主判断能力。从MLA到MoE,从推理效率到成本控制,DeepSeek V3为开源AI模型树立了新标杆,更让我们看到了”乌鸦范式”的可能性。这一创新不仅为中国AI发展提供了宝贵参考,也为全球AI领域注入了新的活力和思考维度。
相关推荐
-
OpenAI员工在推特上,像极了上班的你
Image source: Generated by AI OpenAI发布旗舰推理模型o3和o3-mini,成为他们2024年的收官之作,制造了一波小热潮。和往常一样,Twitt…
-
腾讯AI战略聚焦游戏广告 跳出AGI概念务实布局
如果你期待在腾讯的业绩发布会上听到关于AI的最新战略愿景或AGI的雄心壮志,那么你可能会感到些许失望。2024年3月19日晚间,腾讯公布的2024年第四季度及全年业绩会中,几乎所有…
-
超700亿国资基金密集布局人形机器人 打脸朱啸虎退出论
小鹏AI人形机器人IRON在全球率先开展”人机共跑”马拉松活动,引发广泛关注后,北京亦庄新区迅速响应,积极布局人形机器人产业。4月28日,北京亦庄投资有限公…
-
车企人形机器人热潮背后:战略布局与未来趋势
在今年4月底的北京车展上,人形机器人以一种全新的姿态”站”在了汽车的一边,取代了传统的身材火辣的车模,成为车企展示未来技术的核心符号。小鹏汽车的人形机器人I…
-
AIGC短剧收益超30万 创作者分享实战经验与商业模式
丁宽和龙新远作为国内AIGC影视创作的先驱者,在国内用AIGC创作短剧的领域属于最早一批的探索者。毕业于北京电影学院动画系的丁宽,历时三个多月打造了国内首部纯AIGC制作的付费短剧…
-
马斯克AI游戏画饼 腾讯等布局赛道
近期,AI游戏在互联网领域掀起热潮,成为备受瞩目的焦点。马斯克再次确认将成立AI游戏工作室,并陆续转发多款基于xAI旗下大模型Grok 3制作的游戏产品。然而,自去年以来,尽管马斯…
-
Zoom全平台AI Agent发布 引领智能体自动化新时代
今天凌晨,全球视频会议领域的领军企业Zoom在其官方网站上发布了一项重大公告,正式宣布推出一系列AI Agent产品,旨在全面提升其全平台功能,并标志着Zoom正式迈入智能体自动化…
-
国产推理大模型决战2025考研数学,看看谁第一个上岸?
Image source: Generated by AI 随着上个月 2025 研究生考试的结束,最新的考研数学真题成为大语言模型尤其是推理模型的「试炼场」,将考验它们的深度思考…
-
SEO衰退GEO兴起谁在重塑流量分配规则
谷歌的核心业务——搜索引擎正面临AI技术带来的重大挑战。埃隆·马斯克提出的”AI将取代搜索”的观点正获得越来越多行业认同。这一转变正在深刻影响整个数字营销生…
-
黄晓庆回应风波达闼国华联手成立人形机器人新公司
达闼机器人深圳公司“迁址运营”的传闻近日甚嚣尘上,在人形机器人赛道引发了广泛关注和讨论。外界纷纷猜测,这家备受瞩目的企业是否遭遇了资金困境,其发展之路是否会因此受阻。面对舆论压力,…