2024大模型六小虎逐梦AI:竞争加剧商业化挑战重重
2024年,随着“百模大战”的喧嚣逐渐沉淀,中国大模型创业公司的第一梯队呈现出一个“6+2”的格局。其中,“6”指的是智谱AI、MiniMax、百川智能、月之暗面、阶跃星辰和零一万物,业内常称它们为“大模型六小虎”;而“2”则代表着规模相对较小但各具特色的两家公司——深度求索(DeepSeek)和面壁智能。在ChatGPT问世初期,大模型六小虎无疑是创业赛道中最耀眼的明星。然而,进入2024年下半年,市场格局正悄然发生变化。近期多位投资人向“甲子光年”透露,有两家小虎已显现出落后的迹象,且多位投资人指出的名字惊人地一致。尽管如此,目前尚无公司表现出特别突出的表现,未来还需继续观察。据估算,按当前估值计算,这些公司的发展均未达到预期。一位投资人指出,六家公司的综合实力大致处于同一水平,但融资规模存在差异。此外,幻方量化旗下的深度求索在今年表现亮眼,其发布的DeepSeek V3在多项评测中超越阿里Qwen-2.5与Meta Llama 3.1,成为开源模型的新领导者。有观点认为,DeepSeek已实质跻身“六小虎”之列。随着竞争的加剧,大模型创业公司的赛道也在不断扩展。2023年才后知后觉进入战局的科技巨头,在2024年纷纷后来居上。海外方面,谷歌已立下军令状,计划在2025年发起反击。国内,字节跳动也在AI战略上全面发力。面对2025年的挑战,大模型创业公司将如何应对?


### AGI梦的起点

要洞察当前的暗流涌动,不妨将时间尺度拉长,回顾大模型六小虎的起源。智谱AI与MiniMax是仅有的两家成立时间早于ChatGPT的公司,它们比许多人更早预见到技术的拐点。智谱AI成立于2019年6月,是国内首批探索大模型技术的公司之一。成立之初,智谱AI便立下“让机器像人一样思考”的愿景。其周年庆恰逢OpenAI发布GPT-3,当时创始人张鹏与受邀的张钹院士深入探讨了GPT-3的技术前景。张鹏敏锐地意识到,这项被称为“大模型”的技术将成为未来的方向。他表示:“OpenAI所做的一切,也是我们一直期待、追寻、必须去做的。”智谱AI成立两年后,MiniMax应运而生。2021年,闫俊杰在一个不足100平米的房间里勾勒出MiniMax的初心与路径——实现“Intelligence with Everyone”。他当时提出的三个判断至今仍准确无误:做下一代AI、接近图灵测试的智能体、创造极致的智能体验。在钉钉生态大会上,闫俊杰分享了MiniMax的Day1理念,其核心思想始终未变。

ChatGPT发布后,大模型迅速从一个冷门术语成为投融资市场的焦点。尽管许多人难以清晰定义大模型,但它已成为技术发展的共识。承载着成为“中国版OpenAI”的期待,大模型六小虎应运而生。百川智能的公开信中,王小川激动地写道:“生活在二十一世纪初是如此幸运,互联网革命尚未落幕,通用人工智能时代已呼啸而来。我曾断言,机器掌握语言,通用人工智能时代便到来;也曾畅想,搜索的未来是问答。ChatGPT的横空出世,地动山摇,这一切正成为现实。131天,每天都有新的突破,恍如隔世!”同样感到震撼的还有杨植麟。他认为,ChatGPT展现出的高级推理能力在三五年前是不可想象的,这将催生资本与人才的流动,为搭建AGI(通用人工智能)组织带来可能。杨植麟以自己喜爱的摇滚乐队Pink Floyd的专辑《月之暗面》命名公司,象征对未知与神秘的探索精神。

2022年12月,姜大昕向ChatGPT提出了第一个问题:“你多大了?”这个对人类而言再简单不过的问题,机器曾无法回答。ChatGPT的回答是:“我在2019年被训练完成,今年是2022年,所以是3岁。”姜大昕进一步提问:“你明年多大?”这个问题涉及数字推理,ChatGPT再次给出了正确答案。这一回答让姜大昕意识到,一场划时代的技术变革已经到来。作为AGI创业者中年龄最大的李开复,40年前曾提交CMU博士申请信探索AI。他本可以以投资人的身份旁观,但40年后终于看到AGI梦想有机会实现,终究按捺不住热情,于2023年3月20日发起英雄帖,筹备零一万物。
短短3个月内,大模型六小虎陆续成立:百川智能(2023年3月)、月之暗面与阶跃星辰(2023年4月)、零一万物(2023年5月)。杨植麟曾解释,ChatGPT的扩散需要时间,不同人从认知到接受的过程各异,而融资窗口期极为短暂。他回忆道:“2023年2月,我们集中进行第一轮融资。如果延迟到4月,基本没有机会;但若在2022年12月或2023年1月,又有疫情等因素影响,大家反应迟缓——真正的时间窗口只有一个月。”杨植麟的判断被证明极为精准。2023年下半年后成立的公司,要么难以获得大额融资,难以跻身第一梯队;要么深耕端侧大模型的垂直领域,或像DeepSeek一样,依托“不差钱”的母公司幻方量化,对AGI展开理想主义探索。
### “六小虎”战略分化

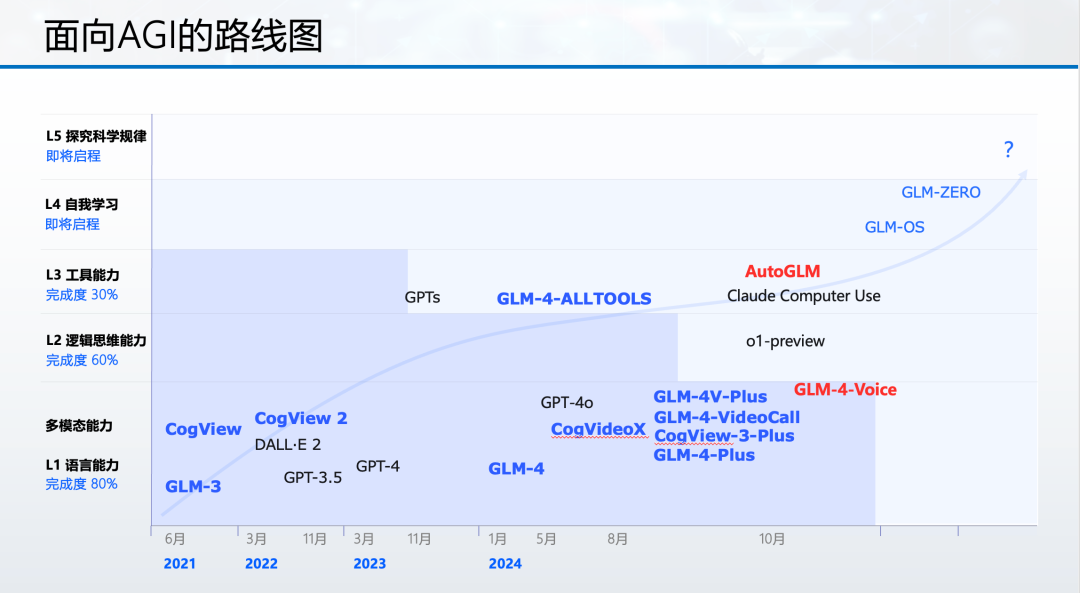
2024年6月14日,智源大会上,杨植麟、王小川、张鹏、李大海四位“清华系”大模型独角兽创始人罕见同台,分享对“通往AGI之路”的看法。在智源研究院院长王仲远的主持下,尽管没有直接交锋,但这次同台已是难得的交流机会。AGI是共同目标,但实现路径却逐渐分化。智谱AI、OpenAI和智谱AI都曾定义过AGI的等级:L1代表AI学会使用语言,L2具备逻辑思维与多模态理解能力,L3学会使用工具(Agent),L4实现自我学习(超级对齐),L5全面超越人类、探究科学规律,趋近AGI。智谱AI还制定了当前AGI的进度条:L1达80%,L2为60%,L3仅40%,L4、L5刚起步。
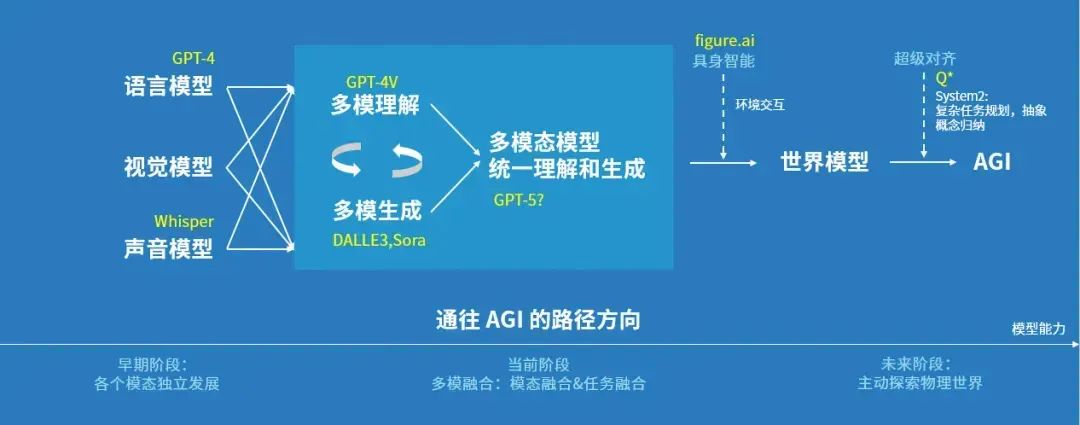
智谱AI的战略可概括为“稳重求胜”。过去两年,它紧盯行业标杆OpenAI,从底层预训练框架到模型,再到上层应用,全面对标。但追随者最好的结果也仅是亚军。2023年下半年,随着OpenAI步伐放缓,智谱AI开始加大对L3——Agent的投入。2023年11月,张鹏现场演示了用AutoGLM在微信建群并发出价值2万元的红包,展示Agent作为智能调度层的潜力,可视为大模型通用操作系统(LM-OS)的雏形。另一家对标OpenAI的阶跃星辰则相对低调,但其业务主线与OpenAI相似,从单模态模型到世界模型。姜大昕曾表示,OpenAI的模型矩阵看似复杂,实则逻辑清晰:GPT-4系列(语言生成)、DALL-E与Sora(多模态生成)、GPT-4v(多模态理解)、GPT-4o(端到端语音)、o系列(推理),以及具身智能(世界模型核心)。他认为,大模型演进将经历模态独立发展、逐步融合,最终彻底融合的过程,而Scaling Law、多模态统一是实现AGI的核心认知。

MiniMax虽然成立较早,但长期保持低调。2023年2月,其核心创始人杨斌向媒体介绍了自研的三款基础模型:文本到视觉、文本到语音、文本到文本,成为国内首家多模态大模型创业公司。其应用Glow曾获近500万用户,后更名为星野(海外版Talkie)。2023年夏天,MiniMax研发MoE混合专家架构,投入80%算力,历经两次失败后于2024年1月推出国内首个MoE大模型。2024年4月,MiniMax又推出基于MoE+Linear Attention的新模型,性能可达GPT-4o水平。闫俊杰在“MiniMax Link伙伴日”上强调,“快”是MiniMax的核心技术研发目标,并分享了AI应用提升渗透率和使用深度的三个关键因素:持续降低错误率、无限长输入输出、多模态。

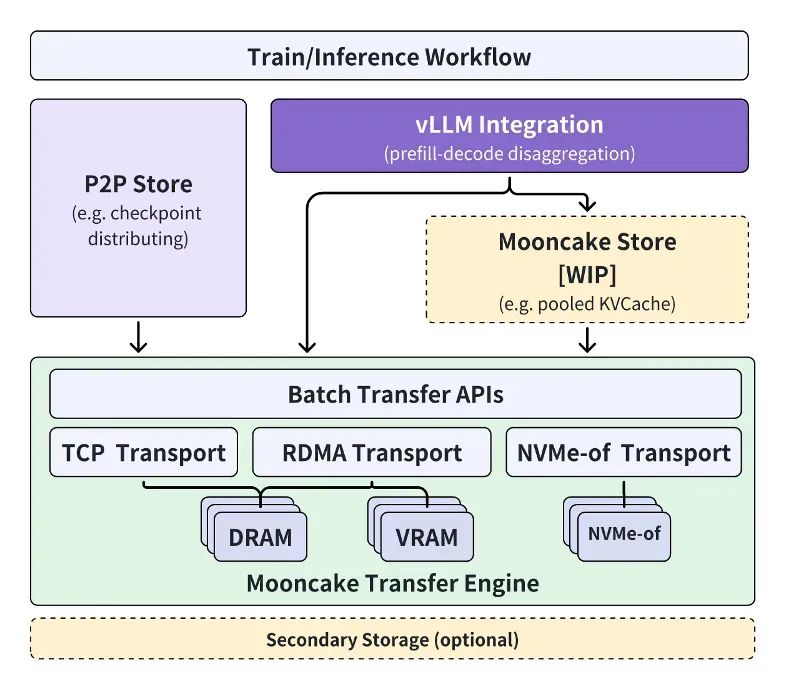
月之暗面则未公开技术路线图,甚至未透露底层模型信息。2023年10月,其首款AI助手Kimi凭借20万字长上下文输入一鸣惊人,远超Ahthropic的Claude-100k(约8万字)和OpenAI的GPT-4-32k(约2.5万字)。独特的长上下文功能让Kimi迅速积累大量用户,成为国内最受关注的AI助手。但用户量越大,推理成本越高,Kimi如何应对“泼天的流量”?2024年7月,月之暗面联合清华大学发布以KVCache为核心的分离式推理架构Mooncake,承载了Kimi线上80%的流量。工程副总裁许欣然甚至“放豪言”,称这套系统能显著降低成本。Kimi之后,月之暗面还探索视频生成、数学模型k0-math、视觉思考模型K1等技术路线。
王小川对AGI的愿景最为独特,但也合乎逻辑。百川智能今年组建了通用人工智能团队,并吸纳大量医疗领域专家,战略聚焦医疗领域。聚焦医疗看似窄化赛道,但王小川认为,能否制造出人工医生,才是判断AGI的关键标志。他强调:“AGI的首要变化是具备思考、学习、沟通、共情能力,以及多模态图像处理能力。评价AGI应像评价人类一样,学习范式需向人类学习,数据源于人类社会。医生是智力密度最高的职业之一,若连医生都制造不出,就别谈AGI了。”中国科学院院士张钹也看好百川智能,认为其在解决中国医疗问题上具有潜力,国内大模型应从应用角度出发。王小川是唯一一位明确表示不做视频模型(如Sora)的创始人,他认为Sora既非AGI,也非场景,只是阶段性产物。

### 预训练的进与退

2024年,海外科技大厂出现一种新收购模式:不直接收购公司,而是收购CEO及小部分团队,如亚马逊收购Adept、微软收购Inflection.ai、谷歌收购Character.ai。这被视为硅谷大模型创业格局洗牌的信号。谷歌收购Character.ai预训练团队后,硅基流动创始人袁进辉评价:“产模一体,略受打击。”产即产品,模即模型。OpenAI、Anthropic、xAI等产模一体的路线并非问题,而是非头部创业公司是否具备足够资金支持。预训练成本高昂,Meta训练Llama 3.1需1.6万张H100,马斯克搭建的Colossus集群含10万张H100,仅GPU购买成本就达4.8亿美元(H100单价3万美元)和30亿美元(xAI)。国内创业公司难以负担。

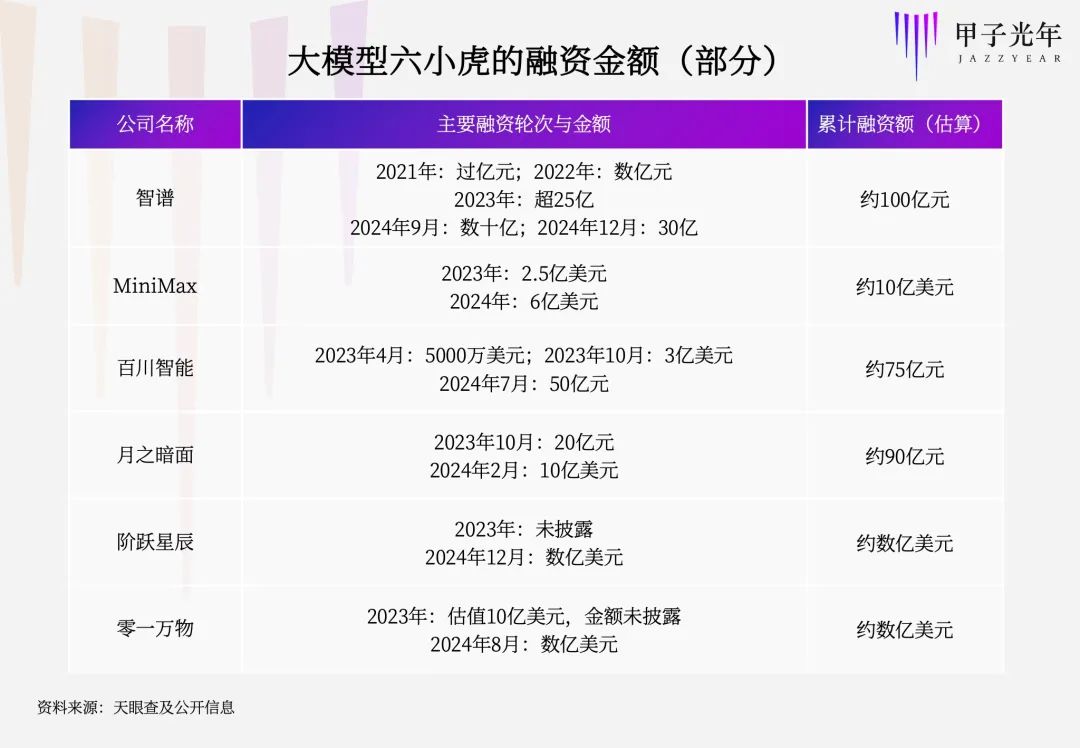
根据公开信息,大模型六小虎估值约200亿元,融资额约百亿人民币。这些资金是否足以支撑继续预训练?今年10月,36kr报道称至少两家小虎放弃预训练,但尚未有公司承认。李开复发文辟谣,零一万物10月16日发布新模型Yi-Lightning,在LLM Arena榜单一度排名全球第六,仅次于OpenAI与谷歌,追平xAI。张鹏在2024甲子引力年终盛典上表示,智谱持续预训练,8月刚发布GLM-4-Plus,每4-6个月迭代新模型。王小川在极客公园IF2025创新大会上肯定中国必须掌握预训练,但受限于算力,超级平台预训练不现实,百川选择“由场景带动预训练”,通过超级应用引领模型进展。阶跃星辰完成数亿美元B轮融资后表示,将投入基础模型研发,强化多模态与复杂推理能力,并通过产品生态覆盖C端。

六小虎不放弃预训练,或与预训练Scaling Law放缓有关。OpenAI推迟发布下一代预训练模型,转向推理模型,引发对Scaling Law是否撞墙的质疑。OpenAI前首席科学家Ilya在NeurIPS 2024大会上直言:“我们所了解的预训练即将结束。”若预训练Scaling Law放缓,对AGI实现不利,但对国内公司或许是好事。堆卡带来的规模效应递减,工程化价值凸显。零一万物Yi-Lightning仅用2000张GPU、300万美元训练,成本仅为OpenAI的3%。李开复认为,中国大模型公司若人才足够优秀、决心足够坚定,资金和芯片都不是问题。DeepSeek V3的训练成本不到600万美元,GPU使用小时仅为Meta的十分之一,印证了这一观点。
大模型范式也在转移。OpenAI发布o1推理模型后,Noam Brown称其代表新推理范式,突破预训练瓶颈。推理侧也有Scaling Law,大模型六小虎的竞争维度被拉长。一个核心问题是预训练与推理算力如何分配?张鹏透露,智谱投入约一半算力用于预训练,另一半用于推理。智谱CEO张鹏在2024甲子引力年终盛典上表示,智谱持续迭代模型,8月发布GLM-4-Plus。姜大昕与杨植麟在云栖大会上对o1模型进行对谈,杨植麟认为算力占比将变化,预训练不会降低,但推理会升高。姜大昕则指出,强化学习的Self Play算力需求可能平方级增长。目前,月之暗面率先发布推理模型,上线数学模型k0-math、视觉思考模型K1,而阿里QwQ、DeepSeek R1、昆仑天工Skywork o1也快速跟进。2024年最后一天,智谱发布首个基于扩展强化学习训练的推理模型GLM-Zero-Preview。预训练胜负未分,推理模型战事正酣,大模型下半场已悄然开启,考验每家公司战略执行力。
### 商业化与技术路线分歧
相比技术路线,商业化更迫在眉睫、生死攸关。红杉资本提出“AI的6000亿美元问题”,直指AI商业化收入与巨额投资不匹配的困境。李开复曾定义中国大模型市场机会:开源/闭源、国内/国外、to B/to C,共8种可能,胜出者数量可能进一步收窄。开源与闭源既是技术选择,也是商业选择。海外大模型公司如OpenAI、Anthropic采用闭源战略,Meta坚定开源,谷歌两者兼有但以闭源为主。国内阿里Qwen、DeepSeek完全开源,其他开源公司多采用谷歌路线,即开源较小参数或非最新模型,核心模型闭源,如智谱、百川智能、零一万物。
智谱AI曾解释开源意义:第一,展示工作;第二,通过社区汇集热情推动发展。开源并非为市场或商业利益,否则不会选择开源。智谱AI是开源战略最成功的创业公司,其模型系列全球下载量超3000万,入选Hugging Face最受欢迎机构。百川智能开源模型下载量近500万次,零一万物开源模型下载量约20万次。
商业化策略上,to B与to C并非单选题,六小虎基本全面布局。多数投资人认为to B想象空间相对较低,但路径更明确;to C想象空间巨大,是继移动互联网后的最大机遇,但如何实现尚无定论。to C领域,月之暗面与MiniMax目前最强。Sensor Tower数据显示,截至2024年6月,Talkie月活达1100万,超半数用户来自美国,与Character.ai硬碰硬;2024年11月,Kimi全平台月活超3600万,与豆包正面交锋。阶跃星辰、智谱也在C端发力,阶跃星辰推出多模态智能视觉搜索功能“拍照问”,集成iPhone 16相机控制键;智谱引入前阿里达摩院资深技术专家胡云华担任智谱清言负责人,2024年用户超2500万,年化收入超千万元人民币。零一万物将C端重心放在海外,海外生产力工具应用用户近千万,营收预期过亿人民币。
to B领域,大模型绕不开定制化难题。定制化模型因服务非标准化,易变成按人/天计价的模式。六小虎普遍采用MaaS(Model as a Service)开放平台解决,每家公司都提供API接口,但多数结合行业深耕,提供个性化解决方案。智谱定位基座大模型,不做垂直模型;张鹏表示,不会扎入具体场景,希望合作伙伴深耕垂直行业。但部分小虎选择深入,如百川智能聚焦医疗,发布“全链路领域增强金融大模型Baichuan4-Finance”;零一万物下半年发布电商直播数字人解决方案、智算中心AI Infra解决方案。零一万物联合创始人祁瑞峰曾表示,解决to B赚钱问题的关键是让大模型进入客户核心业务场景,形成标准化、可规模复制的应用产品。
人们常将“大模型六小虎”与“AI四小龙”对比,后者未解决好to B定制化问题。若商业化难题能解决,四小龙是六小虎的下限;若解决不了,四小龙也可能是六小虎的上限。
### 更多不确定性
技术路线选择与商业化进展之外,还有诸多因素影响大模型公司进展。2024年,月之暗面成为最八卦、争议最大、最受关注的公司。2024年2月,月之暗面完成由阿里领投的10亿美元融资,创国内大模型领域单笔最大纪录。3月,发布200万字长文本功能后,二级市场炒作“Kimi概念股”,带来巨大曝光。但不久后,月之暗面卷入舆论漩涡:媒体报道“杨植麟套现数千万美金”,朱啸虎发起诉讼。尽管公司委托律师处理,核心团队仍保持稳定。其他小虎则遭遇核心人员流失,有的另起炉灶,有的加入大厂。人才流动正常,但去向反映了市场资源流动趋势。2024年,大厂对人才和业务的虹吸效应愈发明显。
最具代表性的是字节跳动。昆仑万维创始人周亚辉今年11月28日点评道:“年初说字节23年AI战略不及格,但这完全不影响字节24年AI战略满分表现。”字节跳动在基础大模型技术侧已全面开花,豆包大模型宣称综合能力对标GPT-4o,上下文窗口达300万字,处理延迟仅需15秒,业界极限。AI产品端,字节跳动推出十几款AI应用,投流竞争优势明显。抖音掌握中国最大聚合广告平台“穿山甲”,流量巨大,自2024年4月起不再接受其他AI产品投放。B端,大模型也逐渐被大厂主导。2024年5月,火山引擎掀起价格战,大模型API价格一降再降。大模型招投标中,中国电信、科大讯飞、智谱、百度云、中国移动分列前五,大厂正取代创业公司占据主导地位。
2024年,“AI一天、人间一年”的狂飙突进正逐渐放缓,备受期待的大模型公司也放慢了节奏。技术发展总规律是:人们常高估短期效应,低估长期影响力。以AGI为目标,目前仍处初级阶段。2025年,大模型将有更多故事与变化,那时我们也将更清晰看清AGI的模样。
相关推荐
-
国产AI视频Vidu 2.0秒出片4分钱震撼全球用户
新年伊始,Vidu就惊艳亮相,震撼发布了Vidu 2.0版本。这款视频生成工具以惊人的速度突破纪录,将视频生成时间压缩至10秒以内,真正实现了秒级创作。更令人惊喜的是,Vidu 2…
-
警惕七天AI速成骗局坑老人养老金
近期,AI“暴富”热潮在老年群体中悄然兴起,一系列精准推送的营销广告正吸引着众多老年人的目光。这些广告以“七天AI速成班月入过万”“我妈靠视频号不出镜月赚16万”等夸张话术包装,诱…
-
AI赋能无障碍科技,助力残障人士拥抱美好生活
《小小的我,拥抱大大的AI——科技无障碍事业的光辉篇章》 在电影《小小的我》中,刘春和的脑瘫形象引发了社会对残障人士真实处境的深刻反思。这部作品让我们欣慰地看到影视界开始正视障碍群…
-
AI手机agent应用与挑战深度解析
自去年以来,智能体(agent)领域迎来了前所未有的发展浪潮。以大语言模型(LLM)为核心,结合其他关键组件,这些智能体不仅具备自主性、响应性,更展现出主动性和社交能力,有望在各个…
-
飞书接入DeepSeek-R1后,批量处理顶一万次,告别服务器繁忙
如果你是 DeepSeek-R1 的忠实用户,那么这张熟悉的截图一定不会陌生。为了体验服务器繁忙失联的滋味,我们人类也使出了浑身解数。巨大的用户需求带来的海量访问量已经让 Deep…
-
谷歌要死磕 OpenAI 了
文章来源:AI燎原 Image source: Generated by AI 在2024年,谷歌以其耀眼的业绩和股价,成为了华尔街的宠儿。 尽管公司在2024年业绩出色、股价涨幅…
-
AI重塑认知革命:从语言垄断到智能共享的变革
七万年前,人类凭借虚构故事的能力完成了第一次认知革命。一万年前,农业革命让我们从狩猎采集者变成了农民。三百年前,科学革命让我们成为了地球的主宰。而今天,我们正站在第三次认知革命的门…
-
36氪接入DeepSeek AI 快速发布融资报道
在信息爆炸的数字时代,如何让优质项目与创意脱颖而出,成为资本关注的焦点?传统融资报道流程冗长、成本高昂,从策划到发布往往耗费数日,不仅需要支付高额的媒体费用,更涉及大量人力物力投入…
-
AI生成体操视频翻车原因深度解析
Sora全网上线后,用户们的测试热情高涨。尽管产品完成度令人瞩目,但模型质量却未达预期。然而,今天我们并非要探讨Sora模型的优劣,而是聚焦于一个令人印象深刻的发现——在测试Sor…
-
谷歌AI模式来袭Perplexity如何应对
又是一年谷歌I/O开发者大会,AI交响乐再次奏响。去年,”AI”一词在谷歌I/O大会上被提及120次,今年虽降至92次,但依然是绝对主角。其中最受瞩目的,莫…