AI手机agent应用与挑战深度解析
自去年以来,智能体(agent)领域迎来了前所未有的发展浪潮。以大语言模型(LLM)为核心,结合其他关键组件,这些智能体不仅具备自主性、响应性,更展现出主动性和社交能力,有望在各个行业实现广泛落地。尤其是在手机端,作为人们日常生活和工作中不可或缺的工具,一旦赋予AI agent能力,其应用场景将充满无限可能。那么,当前的手机agent究竟能为我们做什么?又面临着哪些亟待解决的问题?未来的手机agent又将呈现何种形态?近日,来自浙江大学、vivo和香港中文大学的研究团队在预印本网站arXiv上发布了一篇关于手机GUI agent的综述,深入探讨了上述问题。论文链接:https://arxiv.org/abs/2504.19838
研究团队从手机自动化的发展历程、手机GUI agent的框架与组成部分、手机自动化的LLM应用、面临的挑战以及未来方向等多个维度,全面解析了基于LLM的手机自动化技术。他们在论文中强调,基于LLM的agent开创了一种全新模式,通过整合自然语言处理、多模态感知和行动执行能力,使移动界面操作更加智能化,能够理解、规划和执行移动设备上的任务。这些agent可以精准识别界面元素,深刻理解用户指令,实时感知环境变化并做出动态响应。LLM的问世标志着手机自动化领域迎来了重大变革,它让人们能够与移动设备进行更加动态、上下文感知和复杂的交互。
在LLM驱动的手机GUI agent发展历程中,模型在解释多模态数据、推理用户意图以及自主执行复杂任务方面取得了显著进步。基于LLM的手机自动化遵循着scaling law规律,随着数据集规模的扩大,涵盖的应用程序、使用场景和用户行为也日益多样化,在点击按钮、输入文本等分步自动化任务上持续取得突破。这种数据扩展不仅能够捕捉更广泛的界面布局和设备上下文,还能揭示潜在的“涌现”能力,使LLM能够处理更抽象的多步骤指令。来自不同领域场景的经验证据进一步证明,扩大手机应用和用户模式的覆盖范围可以系统性地提升自动化的准确性。本质上,随着模型规模和数据复杂性的增长,手机GUI agent利用这些scaling law,在用户意图与现实世界GUI交互之间架起了桥梁,实现了效率和复杂性的双重提升。


LLM通过从海量文本语料库中学习,彻底改变了手机自动化的自然语言处理方式。这种训练能够捕捉复杂的语言结构和领域知识,使agent能够理解多步骤命令并生成基于上下文的响应。手机GUI agent凭借强大的自然语言基础,有效弥补了传统基于脚本系统中普遍存在的用户意图差距。GUI屏幕具备多模态感知功能。UGround、Ferret-UI和UI-Hawkexcel等系统将自然语言描述与屏幕元素相结合,并根据界面变化进行动态调整。此外,SeeClick和ScreenAI的研究证明,直接从屏幕截图而非纯文本元数据中学习,可以进一步增强适应性。通过融合视觉感知与用户语言,基于LLM的agent能够更加灵活地应对各种用户界面设计和交互场景。
通过整合语言、视觉上下文和历史用户交互,LLM还能进行高级推理和决策。在广泛的语料库预训练下,这些模型具备了进行复杂推理、多步骤规划和上下文感知适应的能力。LLM的集成使众多创新应用成为可能,包括苹果的Apple Intelligence、智谱的AutoGLM、Anthropic的Computer Use、荣耀的YOYO Agent以及vivo的PhoneGPT等,它们利用手机自动化技术实现了更加自然、高效和个性化的人机交互,为现实世界的挑战提供了创新解决方案。
由多模态大语言模型(MLLM)驱动的手机GUI agent可以采用不同的架构范例和组件进行设计,从简单的单agent系统到复杂的多agent或多阶段方法等。最基本的方案是单个agent逐步运行,而非预先计算整个动作序列。相反,agent会持续观察动态变化的移动环境,其中用户界面元素、设备状态和上下文因素可能以不可预测的方式变化,因此无法事先进行详尽计算。这种情况下,agent必须逐步调整策略,根据当前情况做出决策,而非遵循固定计划。这种迭代决策过程可以使用部分可观测马尔可夫决策过程(POMDP)进行有效建模,POMDP是处理不确定性条件下连续决策的成熟框架。通过将任务建模为POMDP,我们可以捕捉到任务的动态性质、预先计划所有行动的不可能性以及在每个决策点调整agent方法的必要性。
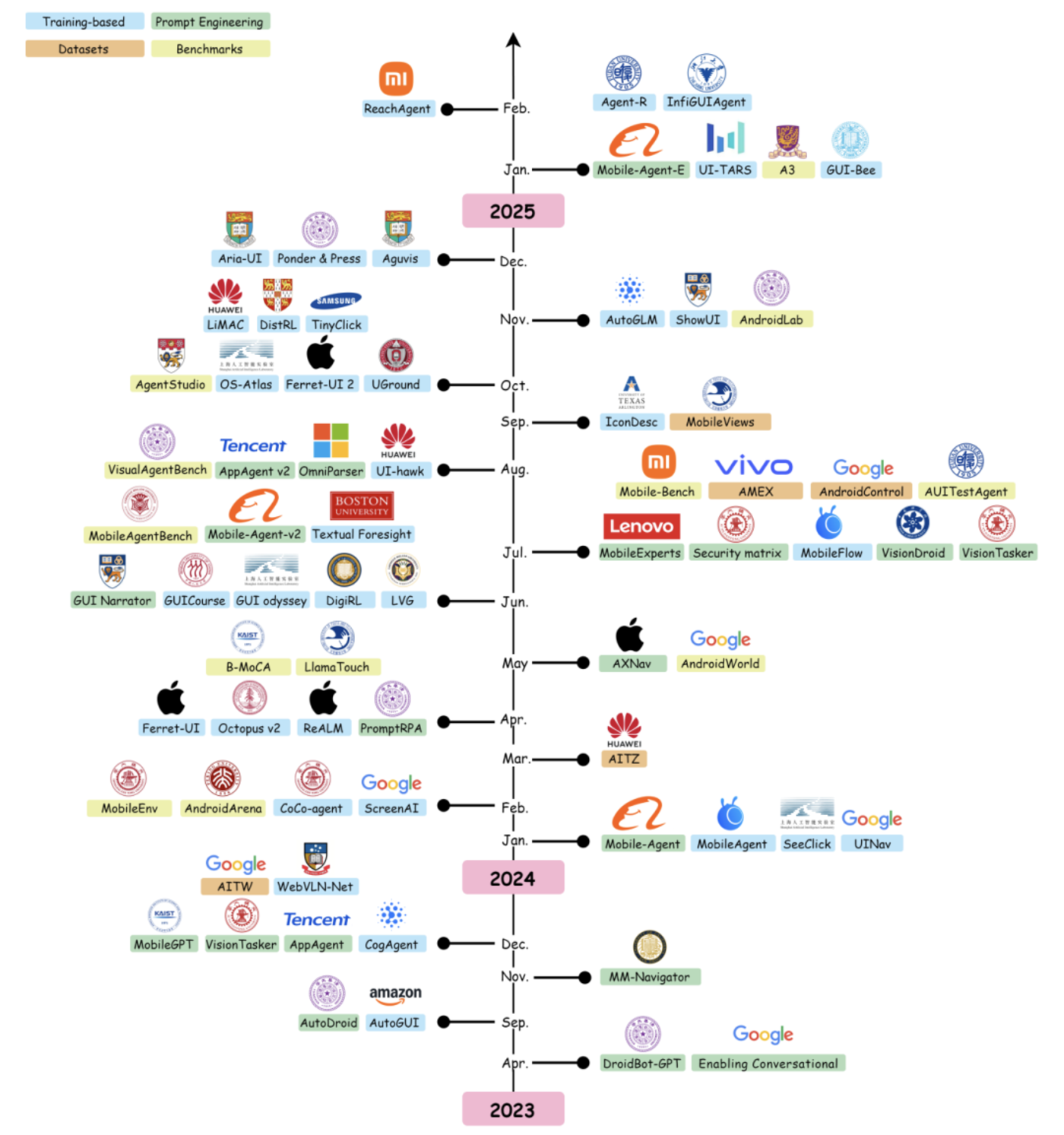
感知是MLLM驱动的手机GUI agent基本框架的核心组件。它负责捕捉和解释移动环境的状态,使agent能够理解当前环境并做出明智的决策。在整个流程中,感知是POMDP的初始步骤,为推理和行动模块的有效运行提供必要的输入。基于LLM的手机自动化agent的认知核心主要由LLM构成。LLM作为agent的推理和决策中心,使其能够在移动环境中解释输入、生成适当的响应并执行操作。利用LLM中蕴含的大量知识,agent可以从高级语言理解、上下文感知以及在不同任务和场景中的泛化能力中获益。行动组件是MLLM驱动的手机GUI agent的重要组成部分,负责执行大脑在移动环境中做出的决策。通过将LLM生成的高级命令与低级设备操作连接起来,agent可以有效地与手机的用户界面和系统功能进行交互。操作包括从点击按钮这样的简单交互,到启动应用程序或修改设备设置这样的复杂任务等。执行机制利用Android的UI Automator、iOS的XCTest或Appium和Selenium等流行的自动化框架等工具,向手机发送精确的命令。通过这些机制,agent可确保将决策转化为设备上切实可靠的操作。
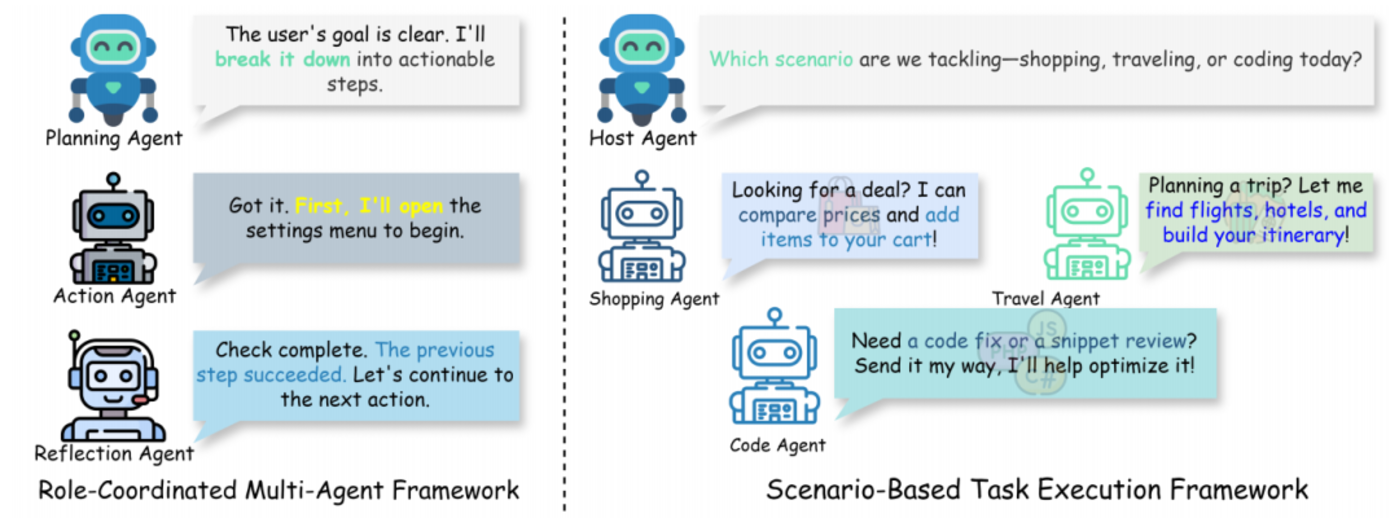
尽管基于LLM的单agent框架在屏幕理解和推理方面取得了重大进展,但它们作为孤立实体运行,这种孤立性限制了它们在复杂任务中的灵活性和可扩展性。复杂任务可能需要多种协调技能和适应能力,而单agent系统难以胜任需要实时反馈、多阶段决策或不同领域专业知识进行持续调整的任务。此外,它们缺乏利用共享知识或与其他agent协作的能力,从而降低了在动态环境中的有效性。多agent框架通过促进多agent之间的协作来解决这些局限性,每个agent都具备专门的功能或专业知识。这种协作方式提高了任务效率、适应性和可扩展性,因为agent可以并行执行任务,或根据各自的特定能力协调行动。手机自动化中的多agent框架可分为两种主要类型:角色协调多agent框架和基于场景的任务执行框架。这些框架通过根据一般功能角色组织agent或根据特定任务场景动态组装专用agent,为手机自动化提供了更加灵活、高效和鲁棒的解决方案。
虽然单agent和多agent框架增强了适应性和可扩展性,但某些任务仍可从明确分离高层规划和低层执行中获益。这就是“计划-执行”框架,在这一范式中,agent首先制定概念计划,通常以人类可读指令的形式表达,然后在设备的用户界面上执行这些指令。
将LLM集成到手机自动化中推动了重大进步,但也带来了诸多挑战。要充分释放智能手机GUI agent的潜力,还需克服以下关键挑战。数据集开发和可扩展性微调。LLM在手机自动化中的性能在很大程度上取决于能够捕捉真实世界中各种场景的数据集。现有的数据集往往缺乏全面覆盖所需的广度。未来的工作重点应该是开发大规模、有注释的数据集,涵盖更广泛的应用、用户行为、语言和设备类型。纳入多模态输入(如屏幕截图、用户界面树和自然语言指令)可以帮助模型更好地理解复杂的用户界面。视频数据集有望发展成为未来GUI数据集的一种新形式。如何进行扩展微调以实现鲁棒的域外性能仍然是一个挑战。未来的发展方向应该是探索混合训练方法、无监督学习、迁移学习和辅助任务,以提高泛化能力,而不需要过于庞大的数据集。
轻量级、高效的设备上部署。在移动设备上部署LLM面临大量计算和内存限制。当前的硬件往往难以支持大型模型,同时将延迟和功耗降至最低。模型剪枝、量化和高效transformer架构等方法可以解决这些限制。专用硬件加速器和边缘计算解决方案可以进一步降低对云的依赖性,增强隐私保护,提高响应速度。考虑利用小语言模型(SLM)的代码生成能力,将GUI任务自动化转化为代码生成问题。这种方法充分利用了SLM的优势,大大提高了移动设备上GUI agent的效率和性能。
以用户为中心的适应性:交互与个性化。当前的agent通常依赖大量的人工干预来纠正错误或指导任务执行,从而破坏了用户的无缝体验。提高agent理解用户意图的能力并减少人工调整至关重要。未来的研究应提高自然语言理解能力,结合语音命令和手势,并使agent能够从用户反馈中不断学习。个性化同样重要,agent应快速适应新任务和用户的特定环境,而无需进行昂贵的再培训。将人工教学、零镜头学习和少镜头学习结合起来,可以帮助agent从最小的用户输入中进行泛化,使其更加灵活和普遍适用。
提升模型能力:接地(grounding)、推理及其他。准确地将语言指令与特定的用户界面元素相结合是一个主要障碍。虽然LLM擅长语言理解,但将指令映射到精确的用户界面交互需要改进的多模态基础。未来的工作应整合先进的视觉模型、大规模注释和更有效的融合技术。agent必须处理错综复杂的工作流程,解释模棱两可的指令,并随着环境的变化动态调整策略。要实现这些目标,可能需要采用新的架构、记忆机制和推理算法。
评估基准标准化。客观且可重复的基准对于比较模型性能至关重要。现有的基准通常针对狭窄的任务或有限的领域,使综合评估变得复杂。涵盖不同任务、应用类型和交互模式的统一基准将促进公平的比较,并鼓励采用更通用、更强大的解决方案。这些基准应提供标准化的指标、场景和评估协议,使研究人员能够更清晰地识别优势、劣势和改进路径。
确保可靠性和安全性。由于agent可以访问敏感数据并执行关键任务,因此可靠性和安全性至关重要。当前的系统可能会受到恶意攻击、数据泄露和意外操作的影响,LLM agent 也容易受到后门攻击。业内需要强大的安全协议、错误处理技术和隐私保护方法来保护用户信息和维护用户信任。采用数据本地化、加密通信和匿名化等技术可以在收集数据的同时有效保护用户隐私。持续监控和验证流程可以实时检测漏洞并降低风险。确保agent的行为具有可预测性、尊重用户隐私并在具有挑战性的条件下保持稳定的性能,对于广泛应用和长期可持续发展至关重要。
研究团队表示,要应对上述挑战,业内需要在数据收集、模型训练策略、硬件优化、以用户为中心的适应性、改进基础和推理、标准化基准和强大的安全措施等方面共同努力。他们认为,下一代由LLM驱动的手机GUI agent,将变得更加高效、可信和有能力,最终在动态移动环境中为用户提供无缝、个性化和安全的体验。此外,更广泛的人工智能范式(如具身AI和AGI)将会融合到手机自动化中,从而使agent能够在最少的人工监督下处理日益复杂的任务。
相关推荐
-
马斯克xAI发布Grok 3大模型 自称超越o1R1
2月18日,科技界迎来重磅消息——马斯克旗下xAI公司正式发布了新一代大模型Grok 3,并宣称这是”地球上最聪明的人工智能”。这一声明迅速引发全球关注,G…
-
最后的疯狂?拜登离任前最强AI禁令引众怒!
Image source: Generated by AI 如无意外,现任美国总统拜登将于当地时间2025年1月20日中午正式卸任美国总统,并将权力移交给当选总统特朗普。 然后就在…
-
OpenAI发布Sora Turbo视频模型 会员免费体验服务器挤爆
OpenAI于12月10日凌晨震撼发布视频模型Sora的高端加速版本——Sora Turbo,以惊人的速度重新定义视频生成领域。相较于初代Sora,Sora Turbo在效率上实现…
-
科大讯飞2024年营收233亿 星火X1升级版性能对标DeepSeek模型
4月21日,AI行业传来重磅消息。上市公司科大讯飞(SZ:002230)正式发布2024财年及2025年第一季度业绩报告,全面展现其在新一代人工智能领域的战略布局与市场表现。财报数…
-
DeepSeek爆火100天:创业者盛赞梁文锋技术革新
DeepSeek R1自1月20日爆火以来,过去100天里,它已稳居大模型领域的顶流位置。作为中国AI力量的代表,DeepSeek不仅展现了本土技术的实力,更在一定程度上影响了全球…
-
六个核桃16亿投资长江存储母公司 总估值破千亿
国内存储芯片龙头企业长江存储的母公司迎来新一轮巨额融资,引发行业高度关注。WpBull.com硅基世界独家获悉,4月25日晚间,知名核桃饮品品牌“六个核桃”母公司——A股上市企业河…
-
AI图片AppSelfyzAI3个月DAU暴涨2.8倍,如何避免“一波流魔咒”持续增长
在11月的AI产品榜全球AI App MAU增速榜中,一款名为“AI图片舞蹈”的产品SelfyzAI凭借161万的MAU和50%以上的高速增长,位列增速榜第七名。这一创新应用让静态…
-
不是,你们大模型全开源了,那到底咋挣钱啊?
文章来源:差评X.PIN Image source: Generated by AI 在今天正式开唠之前,差评君想问一个小问题:在你看来,开源是一种怎么样的存在? 纯慈善?活菩萨…
-
OpenAI直播12天,马斯克融资437亿
文章来源:字母榜 Image source: Generated by AI OpenAI的12天马拉松直播活动结束了,但是这个“马拉松”有点名不副实。 人们最期待的GPT-5仍然…
-
独家对话Manus肖弘:世界不是线性外推,做博弈中的重要变量
Image source: Generated by AI 和DeepSeek等从大模型开始构建底层能力的AI公司不同,Manus AI是一家从day 1就只做AI应用的创业公司。…