DeepSeek服务器繁忙背后的原因解析
DeepSeek的“服务器繁忙,请稍后再试”正成为全球用户的心头痛。2024年12月26日,DeepSeek凭借对标GPT 4o的语言模型V3一炮而红,1月20日又推出对标OpenAI o1的R1模型,凭借“深度思考”模式的高质量回答和创新技术,迅速出圈。然而,R1上线后便持续遭遇拥堵,联网搜索功能时断时续,深度思考模式频繁提示“服务器繁忙”,让用户苦不堪言。


短短十几天内,DeepSeek服务器中断频发,1月27日中午官网多次显示“deepseek网页/api不可用”。当日,DeepSeek成为周末iPhone下载榜冠军,美区超越ChatGPT。2月5日,DeepSeek移动端上线26天,日活突破4000万,虽不及ChatGPT的5495万,但已占其74.3%。用户增长迅猛,但服务器繁忙的抱怨也随之而来,全球用户遭遇频繁宕机,各类替代访问方式应运而生,但问题并未解决。
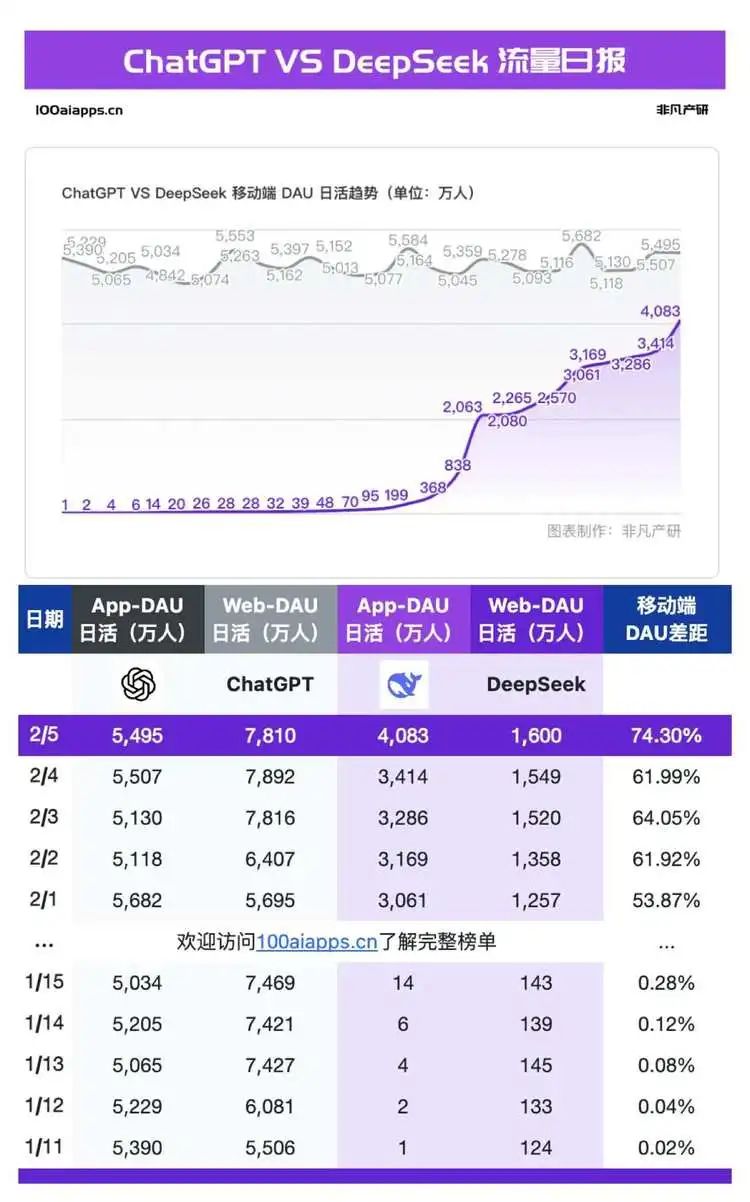
为何全球厂商纷纷支持DeepSeek,用户却依然饱受困扰?这背后原因复杂。习惯了ChatGPT稳定体验的用户,对DeepSeek的频繁卡顿难以忍受。ChatGPT虽经历数次严重宕机,但总体可靠,已找到创新与稳定的平衡点。其推理过程包括编码(将文本转为向量)和解码(生成文本)两个步骤,每次提问都启动一次推理流程。ChatGPT的解码阶段采用Decoder架构,通过token(最小文本单位)逐步生成完整语句。Kubernetes作为其“幕后指挥官”,负责调度服务器资源。当用户量超出承载能力时,系统便会瘫痪。ChatGPT的稳定性源于强大的算力支撑,而DeepSeek的算力储备明显不足。

DeepSeek与OpenAI的处境截然不同。ChatGPT有微软Azure云服务强力支持,形成云+AI经典范式;DeepSeek则主要依赖自建数据中心,与谷歌类似,缺乏第三方云计算合作。面对史无前例的用户增长,DeepSeek的应激准备不足。其母公司幻方量化打造的萤火一号超算集群,存储万张A100显卡,自研HAI LLM训练框架,支撑R1等模型训练,性能接近GPT-4。外界认为,萤火集群通过创新技术降低训练成本,用几分之一算力训练出顶级AI模型。SemiAnalysis推算DeepSeek拥有6万张英伟达GPU卡,包括1万张A100、1万张H100等,看似算力充足,实则推理模型R1需要更多算力,而DeepSeek在训练侧节约的算力,是否足以应对推理侧的骤增需求,尚不明确。
DeepSeek-V3与R1运作方式不同。V3是指令模型,类似ChatGPT;R1是推理模型,会先进行大量推理过程,再生成答案。R1生成的token中包含大量思维链过程,解释和分解问题。耀途资本副总裁温廷灿指出,训练阶段算力可规划,但推理算力取决于用户规模,DeepSeek用户规模爆炸性增长,导致推理算力需求激增。独立开发者歸藏认为,DS作为全球下载量最高的移动应用,现有卡量无论如何都撑不住,即便使用新卡也需要时间。英伟达A100、H100等芯片运行成本高昂,DeepSeek推理成本虽低于OpenAI同类模型,但GPU数量决定其服务上限。
黑客攻击也是R1卡顿的驱动因素。1月30日,奇安信观察到针对DeepSeek的攻击指令暴增上百倍,至少有2个僵尸网络参与。但第三方服务并未解决根本问题。春节期间,英伟达、亚马逊云、微软等纷纷部署DeepSeek模型,华为云、阿里云等提供全系模型部署服务,壁仞科技、瀚博半导体等适配AI芯片,用友、金蝶等接入模型增强产品力。尽管DeepSeek吸引了庞大朋友圈,但服务商和DS自身仍受困于用户洪流,未能解决稳定使用问题。
服务商部署的R1体验问题未获解决。外界认为服务商算力充足,但开发者反馈频度与R1相当。歸藏解释称,服务商需兼顾其他模型,分配给R1的卡量有限。模型部署优化涉及多环节,但DeepSeek卡顿可能源于模型过大和优化不足。热门大模型上线前需重视推理优化,避免计算耗时和内存问题。温廷灿指出,服务商提供R1服务遇到挑战,本质是DS模型结构特殊,优化需要时间,市场热度窗口有限,故先上再优化。
R1稳定运行的关键在于推理侧的储备和优化。DeepSeek需降低推理成本,减少单次输出token数量。算力储备也可能未SemiAnalysis所述庞大,需平衡幻方基金公司和DeepSeek训练团队的需求。短期内DeepSeek未必租用服务改善体验,可能待商业模式清晰后再考虑,这意味着卡顿将持续较长时间。开发者陈云飞建议分两步解决:1)做付费机制限制免费用户模型用量;2)与云服务厂商合作,使用GPU资源。目前看来,DeepSeek对“服务器繁忙”问题并不急于解决,追逐AGI的公司似乎更关注用户流量,用户可能需习惯面对这一界面。
相关推荐
-
媒体再爆:OpenAI的GPT-5训练遇阻,时间延迟且成本高昂
文章来源:硬AI Image source: Generated by AI AI的下一个飞跃似乎没法准时报道了。 当地时间20日,据《华尔街日报》报道,OpenAI的新一代人工智…
-
AI编码崛起:2025年中级程序员或被取代
程序员创造的AI,最先替代的可能是程序员自身。阿里云云原生应用平台负责人、通义灵码负责人丁宇向光锥智能表示:“大模型的编码能力,现在已经具备高阶程序员(月薪几万元)的水平了。”实际…
-
DeepSeek揭秘:清北应届生打造AI奇迹团队
DeepSeek大模型横空出世,以1/11的算力训练出超越Llama 3的开源模型,震撼了整个AI圈。紧接着,“雷军开千万年薪挖DeepSeek研究员罗福莉”的传闻,更将人们的目光…
-
美国AI出口禁令升级 智谱AI首遭列入实体清单引发科技巨头反对
美国商务部于1月15日更新的出口管制实体清单中,智谱AI成为首例被列入该名单的大模型公司。当日发布的修订版《出口管理条例》(EAR)中,共列出了11家中国企业,其中9家为智谱关联企…
-
网文编辑痛诉AI泛滥:如何辨别AI稿件?
在网文圈浸淫三年,编辑花花第一次发现自己邮箱里每天会收到五六封AI投稿,她感慨道:”今年,AI稿已经泛滥了。”工作室编辑群里,大家最近热议的话题变成了…
-
抢占AI原生应用入口,百度上线首个无代码开发平台
图片由WpBull.comAPP拍摄 3月24日,百度AI Day上,WpBull.comAPP获悉,百度全量上线了首个无代码开发平台秒哒。 以对话式为交互方式,秒哒打出了三大核心…
-
阿里巴巴AI战略升级投入3800亿成中国AI巨头
2024财年第三季度财报电话会上,阿里巴巴集团CEO吴泳铭以12次提及”AI”的频率,向资本市场释放出强烈信号:这家中国互联网巨头正在经历其发展史上又一次深…
-
京东将推AI数字人“千人千面”具身智能技术引领未来
近日京东在”具身智能”领域的布局引发广泛关注,集团已正式成立相关业务部门并展开技术攻关。3月初京东探索研究院发布重要研究成果,其开发的高扩展性具身智能系统架…
-
一文回顾OpenAI系列发布会:从工具到AGI,OpenAI的12天进化论
Image source: Generated by AI OpenAI 年末的12天连续Devday更新终于落幕,每天蹲守观看发布会都像在开巧克力盲盒,不知道下一个是什么口味。 …
-
华人掌控全球芯片巨头 华裔主导科技产业新格局
作为全球科技领域的顶尖力量,如今的”全球芯片五巨头”均由华人掌舵。博通、英伟达、英特尔、AMD和台积电这五大巨擘分别由陈福阳、黄仁勋、陈立武、苏姿丰、魏哲家…