大模型隐私危机:7款主流产品数据安全形同虚设
在人工智能蓬勃发展的时代,用户输入的信息不再仅仅是个人隐私的范畴,更成为了推动大模型进步的重要资源。无论是“帮我制作一份PPT”、“帮我设计一版新春海报”,还是“帮我总结一下文档内容”,这些日常任务借助AI工具得以高效完成,让AI提效成为职场人士的标配。然而,这种便捷的背后隐藏着巨大的隐私风险。数字化时代,我们使用各种工具时往往忽略了透明度缺失的问题,不清楚自己的数据如何被收集、处理和存储,更无法确定数据是否会被滥用或泄露。


今年3月,OpenAI承认ChatGPT存在漏洞,导致部分用户的历史聊天记录被泄露,这一事件引发了公众对大模型数据安全和个人隐私保护的广泛关注。除了ChatGPT的数据泄露事件,Meta的AI模型也因侵犯版权而备受争议。今年4月,美国作家、艺术家等组织指控Meta的AI模型盗用他们的作品进行训练,侵犯了其版权。在国内,类似的事件也时有发生。最近,爱奇艺与“大模型六小虎”之一的稀宇科技(MiniMax)因著作权纠纷引发社会关注。爱奇艺指控海螺AI未经许可使用其版权素材训练模型,此案成为国内首例视频平台对AI视频大模型的侵权诉讼。这些事件不仅暴露了大模型训练数据来源和版权问题的严重性,也凸显了AI技术发展必须建立在用户隐私保护的基础之上。

为了深入了解当前国产大模型的信息披露透明度,我们选取了豆包、文心一言、kimi、腾讯混元、星火大模型、通义千文、快手可灵这7款市面主流大模型产品作为样本,通过隐私政策和用户协议测评、产品功能设计体验等方式进行了实测。结果显示,不少产品在信息披露透明度方面存在不足,也让我们更加清晰地看到了用户数据与AI产品之间的复杂关系。
### 撤回权形同虚设

从登录页面可以看出,7款国产大模型产品均沿袭了互联网APP的“标配”使用协议和隐私政策,并在隐私政策文本中设有不同章节,向用户说明如何收集和使用个人信息。这些产品的说法基本一致:为了优化和改进服务体验,可能会结合用户对输出内容的反馈以及使用过程中遇到的问题来改进服务。在经过安全加密技术处理、严格去标识化的前提下,可能会将用户向AI输入的数据、发出的指令以及AI相应生成的回复、用户对产品的访问和使用情况进行分析并用于模型训练。

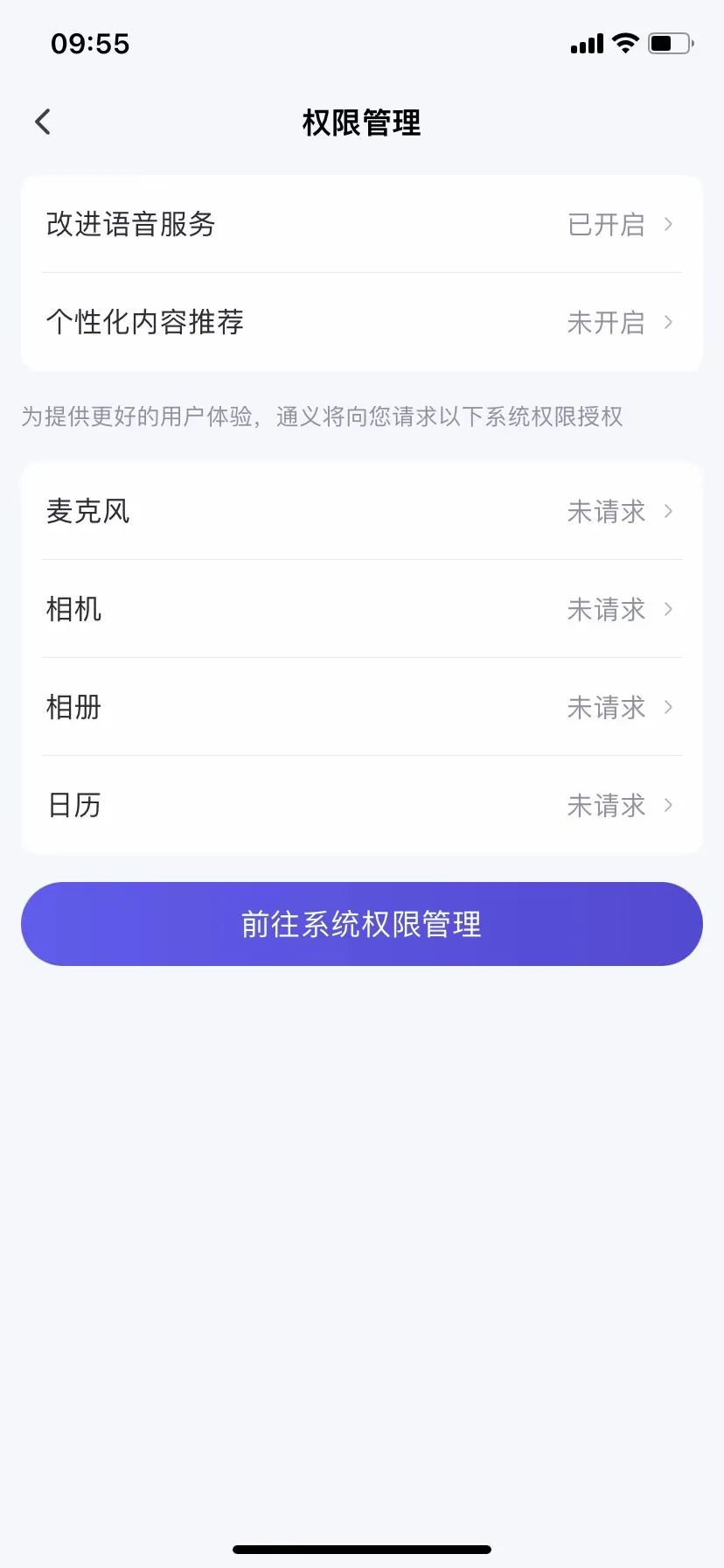
然而,用户真正关心的是是否有权拒绝或撤回相关数据“投喂”AI训练。在翻阅和实测这7款AI产品后,我们发现只有豆包、讯飞、通义千问、可灵四家在隐私条款中提及了可以“改变授权产品继续收集个人信息的范围或撤回授权”。其中,豆包主要集中在语音信息的撤回授权。政策显示,“如果您不希望您输入或提供的语音信息用于模型训练和优化,可以通过关闭‘设置’-‘账号设置’-‘改进语音服务’来撤回您的授权”;但对于其他信息,则需要通过公示的联系方式与官方联系,才能要求撤回使用数据用于模型训练和优化。

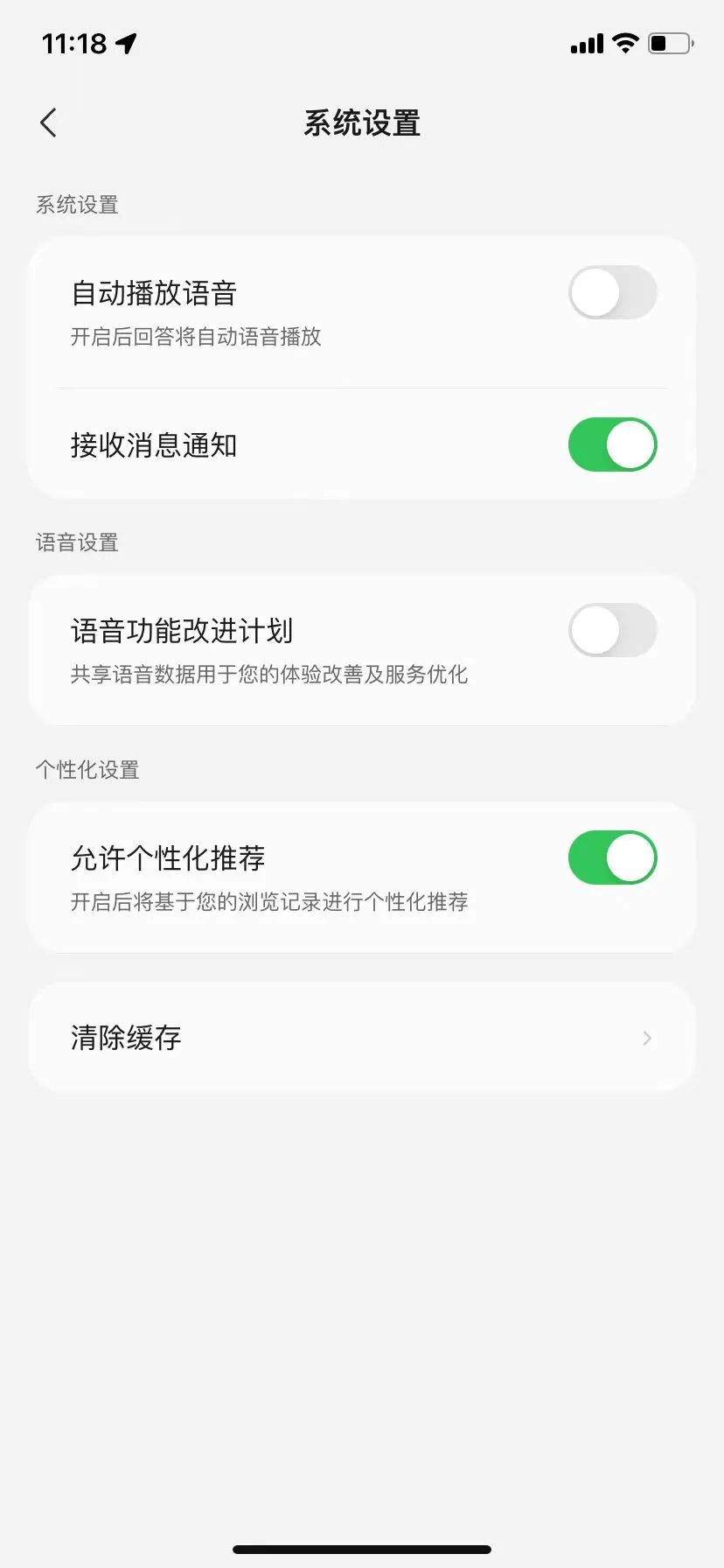
在实际操作过程中,对于语音服务的授权关闭并不算难,但对于其他信息的撤回使用,我们在联系豆包官方后一直未能得到回复。通义千问与豆包类似,个人能操作的仅有对语音服务的授权撤回,而对于其他信息,也是需要联系通过披露的联系方式与官方联系,才能改变或者收回授权收集和处理个人信息的范围。可灵作为视频及图像生成平台,在人脸使用方面有着重表示,称不会将您的面部像素信息用于其他任何用途或共享给第三方。但如果想要取消授权,则需要发送邮件联系官方进行取消。相比豆包、通义千文以及可灵,讯飞星火的要求更为苛刻,按照条款,用户如果需要改变或撤回收集个人信息的范围,需要通过注销账号的方式才能实现。腾讯元宝虽然没有在条款中提到如何改变信息授权,但在APP中我们可以看到“语音功能改进计划”的开关。Kimi虽然在隐私条款中提到了可以撤销向第三方分享声纹信息,并且可以在APP中进行相应操作,但我们在摸索良久后并没有发现更改入口。至于其他文字类信息,也未找到相应条款。
从这些大模型产品的条款我们不难看出,收集用户输入信息似乎已经成了共识,不过对于更为隐私的声纹、人脸等生物信息,仅有一些多模态平台略有表现。但这并非经验不足,尤其是对于互联网大厂来说。比如,微信的隐私条款中就详尽地列举了每一项数据收集的具体场景、目的和范围,甚至明确承诺“不会收集用户的聊天记录”。抖音也是如此,用户在抖音上上传的信息几乎都会在隐私条款中标准使用方式、使用目的等详细说明。

互联网社交时代被严格管控的数据获取行为,如今在AI时代中却成了一种常态。用户输入的信息已经被大模型厂商们打着“训练语料”的口号随意获取,用户数据不再被认为是需要严格对待的个人隐私,而是模型进步的“垫脚石”。
### 训练语料“投喂”隐患大

大模型的训练除了算力外,高质量的语料更为重要,然而这些语料往往包含一些受版权保护的文本、图片、视频等多样化作品,未经授权便使用显然会构成侵权。实测后发现,7款大模型产品在协议中都未提及大模型训练数据的具体来源,更没有公开版权数据。至于大家都非常默契不公开训练语料的原因也很简单,一方面可能是因为数据使用不当很容易出现版权争端,而AI公司将版权产品用作训练语料是否合规合法,目前还未有相关规定;另一方面或与企业之间的竞争有关,企业公开训练语料就相当于食品公司将原材料告诉了同行,同行可以很快进行复刻,提高产品水平。

值得一提的是,大多数模型的政策协议中都提到,会将用户和大模型的交互后所得到的信息用于模型和服务优化、相关研究、品牌推广与宣传、市场营销、用户调研等。坦白讲,因为用户数据的质量参差不齐,场景深度不够,边际效应存在等多方面原因,用户数据很难提高模型能力,甚至还可能带来额外的数据清洗成本。但即便如此,用户数据的价值仍然存在。只是它们不再是提升模型能力的关键,而是企业获取商业利益的新途径。通过分析用户对话,企业可以洞察用户行为、发掘变现场景、定制商业功能,甚至和广告商共享信息。而这些也恰巧都符合大模型产品的使用规则。

不过,也需要注意的是,实时处理过程中产生的数据会上传到云端进行处理,也同样会被存储至云端,虽然大多数大模型在隐私协议中提到使用不低于行业同行的加密技术、匿名化处理及相关可行的手段保护个人信息,但这些措施的实际效果仍有担忧。例如,如果将用户输入的内容作为数据集,可能过段时间后当其他人向模型提问相关的内容,会带来信息泄露的风险;另外,如果云端或产品遭到攻击,是否仍可能通过关联或分析技术恢复原始信息,这一点也是隐患。

欧洲数据保护委员会(EDPB)前不久发布了对人工智能模型处理个人数据的数据保护指导意见。该意见明确指出,AI模型的匿名性并非一纸声明即可确立,而是必须经过严谨的技术验证和不懈的监控措施来确保。此外,意见还着重强调,企业不仅要证实数据处理活动的必要性,还必须展示其在处理过程中采用了对个人隐私侵入性最小的方法。所以,当大模型公司以“为了提升模型性能”而收集数据时,我们需要更警惕去思考,这是模型进步的必要条件,还是企业基于商业目的而对用户的数据滥用。

### 数据安全模糊地带

除了常规大模型应用外,智能体、端侧AI的应用带来的隐私泄漏风险更为复杂。相比聊天机器人等AI工具,智能体、端侧AI在使用时需要获取的个人信息会更详细且更具有价值。以往手机获取的信息主要包括用户设备及应用信息、日志信息、底层权限信息等;在端侧AI场景以及当前主要基于读屏录屏的技术方式,除上述全面的信息权限外,终端智能体往往还可以获取录屏的文件本身,并进一步通过模型分析,获取其所展现的身份、位置、支付等各类敏感信息。例如荣耀此前在发布会上演示的叫外卖场景,这样位置、支付、偏好等信息都会被AI应用悄无声息地读取与记录,增加了个人隐私泄露的风险。
如“腾讯研究院”此前分析,在移动互联网生态中,直接面向消费者提供服务的APP一般均会被视为数据控制者,在如电商、社交、出行等服务场景中承担着相应的隐私保护与数据安全责任。然而,当端侧AI智能体基于APP的服务能力完成特定任务时,终端厂商与APP服务提供者在数据安全上的责任边界变得模糊。往往厂商会以提供更好服务来当作说辞,当放到整个行业量来看,这也并非“正当理由”,Apple Intelligence就明确表示其云端不会存储用户数据,并采用多种技术手段防止包括Apple自身在内的任何机构获取用户数据,赢得用户信任。
毋庸置疑,当前主流大模型在透明度方面存在诸多亟待解决的问题。无论是用户数据撤回的艰难,还是训练语料来源的不透明,亦或是智能体、端侧AI带来的复杂隐私风险,都在不断侵蚀着用户对大模型的信任基石。大模型作为推动数字化进程的关键力量,其透明度的提升已刻不容缓。这不仅关乎用户个人信息安全与隐私保护,更是决定整个大模型行业能否健康、可持续发展的核心要素。未来,期待各大模型厂商能积极响应,主动优化产品设计与隐私政策,以更加开放、透明的姿态,向用户清晰阐释数据的来龙去脉,让用户能够放心地使用大模型技术。同时,监管部门也应加快完善相关法律法规,明确数据使用规范与责任边界,为大模型行业营造一个既充满创新活力又安全有序的发展环境,使大模型真正成为造福人类的强大工具。
相关推荐
-
AI社交大战爆发 朋友圈成新战场
短短两个月,国内AI原生应用的排行榜经历了数次颠覆性变化。春节过后,DeepSeek凭借其”低成本、高性能”的优势迅速在全球崭露头角,成为AI领域的黑马。而…
-
阿里Qwen3系列开源:性价比多模态大模型矩阵抢市场
阿里云Qwen3系列重磅发布:重塑大模型开源标准 凌晨时分,阿里云正式揭晓了备受瞩目的Qwen3系列模型,一口气开源了从0.6B到235B共8款模型,包括2个MoE大模型和6个De…
-
中国科学院全新AI大模型JigonGPT成功上天 运行140天打破全球纪录
中国自主研发的AI大模型成功进入太空运行,标志着全球AI与航天技术结合的全新突破。5月12日,据WpBull.comAGI独家消息,中国科学院计算技术研究所(简称“计算所”)宣布,…
-
o3模型智商157,比肩爱因斯坦!AI只用7个月,超过人类100年
Image source: Generated by AI 根据OpenAI公布的数据显示,新模型o3在Codeforces上的评级为2727,比全球99.8%程序员都要好。 如果…
-
AI家务神器π0.5实现跨环境泛化操作
近年来,机器人技术取得了令人瞩目的进步,它们不仅能表演杂技、跳舞,还能听从指令完成叠衣服、擦桌子等复杂任务。然而,机器人面临的最大挑战并非灵活性,而是泛化能力——即在新环境中正确完…
-
Zoom全平台AI Agent发布 引领智能体自动化新时代
今天凌晨,全球视频会议领域的领军企业Zoom在其官方网站上发布了一项重大公告,正式宣布推出一系列AI Agent产品,旨在全面提升其全平台功能,并标志着Zoom正式迈入智能体自动化…
-
AI猫说唱爆火TikTok 萌宠AI对口型神器走红
让每只小猫都唱上中文Rap!来自东方的神秘力量,最近又给了老外亿点点震撼。”老天保佑金山银山前路有,老天教唆别管江湖龙虎斗。”这段出自国内男Rapper&#…
-
腾讯AI战略调整 元宝能否扛起大旗
经过数月的过山车式开局,腾讯元宝终于回归现实。持续数月的大模型榜单争夺战已落下帷幕。截至5月20日,苹果应用商店免费App下载榜榜首为豆包,DeepSeek位列第六,而元宝则跌至4…
-
宇树机器人春晚爆红后商业价值飙升成顶流广告主角
当宇树机器人在春晚身着大花棉袄扭秧歌时,或许无人预料到这个看似抽象的表演嘉宾,会在接下来的两个月里成为社交媒体的顶流。在各大社交平台上,宇树机器人G1时而模仿邓超的舞蹈动作,时而展…
-
官宣!OpenAI加入机器人赛道,要打造实体AGI
Image source: Generated by AI OpenAI联合创始人兼总裁Greg Brockman,转发了一条正在招聘硬件工程师的消息,正式官宣OpenAI加入实体…