大模型色盲测试:AI视觉能力大比拼
先来说明一个关键点:大多数人工智能模型获取外界信息的主要途径是视觉输入。我们通过眼睛欣赏朝阳的绚烂、皎月的清辉、大漠孤烟的苍茫以及碧海雄关的壮阔。那么,当我们用相机捕捉这些美景,再与大模型进行交流时,它们所”看见”的世界,是否与我们感知的完全一致呢?或许,答案是否定的。基于此,我们设计了一个有趣的测试:人工智能模型是否具有色盲现象?


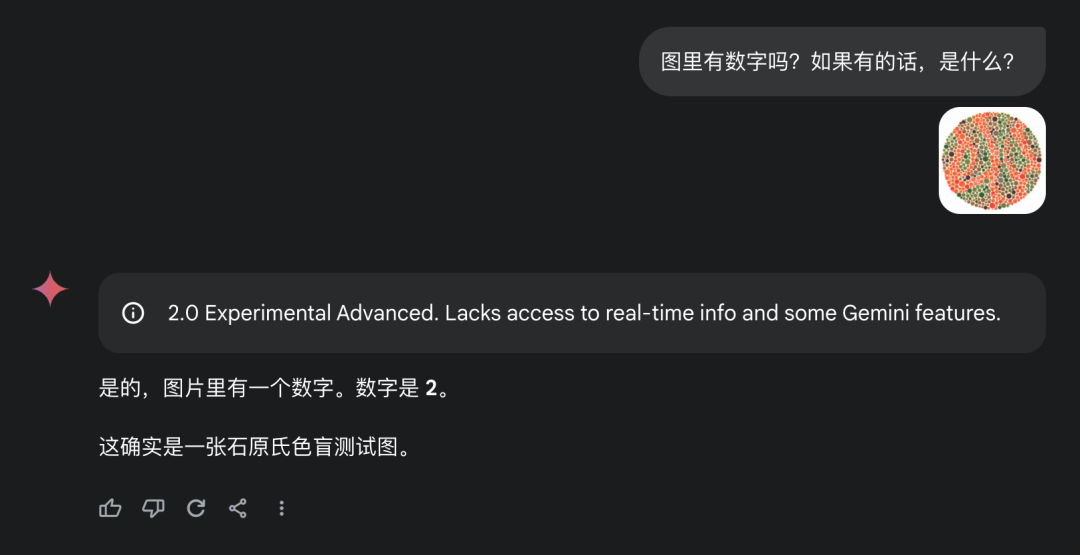
在医学检查中,医生通常会展示一些石原氏色盲检测图,这些由多种颜色圆点组成的图案中隐藏着数字。正常视力的人能够准确识别,而色盲者则容易读错。我们将这些测试图交给人工智能模型进行识别,看看它们的表现如何。这里选取了两种最具代表性的测试图:一种是正常视力者能够识别,而红绿色盲者无法辨认的数字;另一种则是只有红绿色盲者才能识别的数字。

我们选取了四家知名的人工智能公司作为测试对象:OpenAI的GPT-4o、Claude(Anthropic)的3.5 Sonnet、Sonnet通过Claude以及Gemini(Google)的2.0(exp-1206)。在测试中,我们统一使用相同的提示语:图中有数字吗?如果有的话,是什么?

在第一题的测试中,正常视力者能够识别出数字74,而红绿色盲者则读成了21。结果显示,ChatGPT的GPT-4o回答正确,Claude的3.5 Sonnet部分正确,Gemini的2.0(exp-1206)实锤红绿色盲,而智谱的GLM-4同样回答正确。小结一下,OpenAI和智谱的模型在这项测试中表现出了正常的色觉。

在第二题的测试中,正常视力者无法识别出任何数字,而红绿色盲者则识别出了数字5。ChatGPT的GPT-4o识别出了一个5,并鉴定为半色盲;Claude的3.5 Sonnet同样识别出了一个5,并鉴定为半色盲;Gemini的2.0(exp-1206)则完全没有识别出数字;而智谱的GLM-4再次回答正确。在这个测试中,只有GLM-4的表现是完美的。
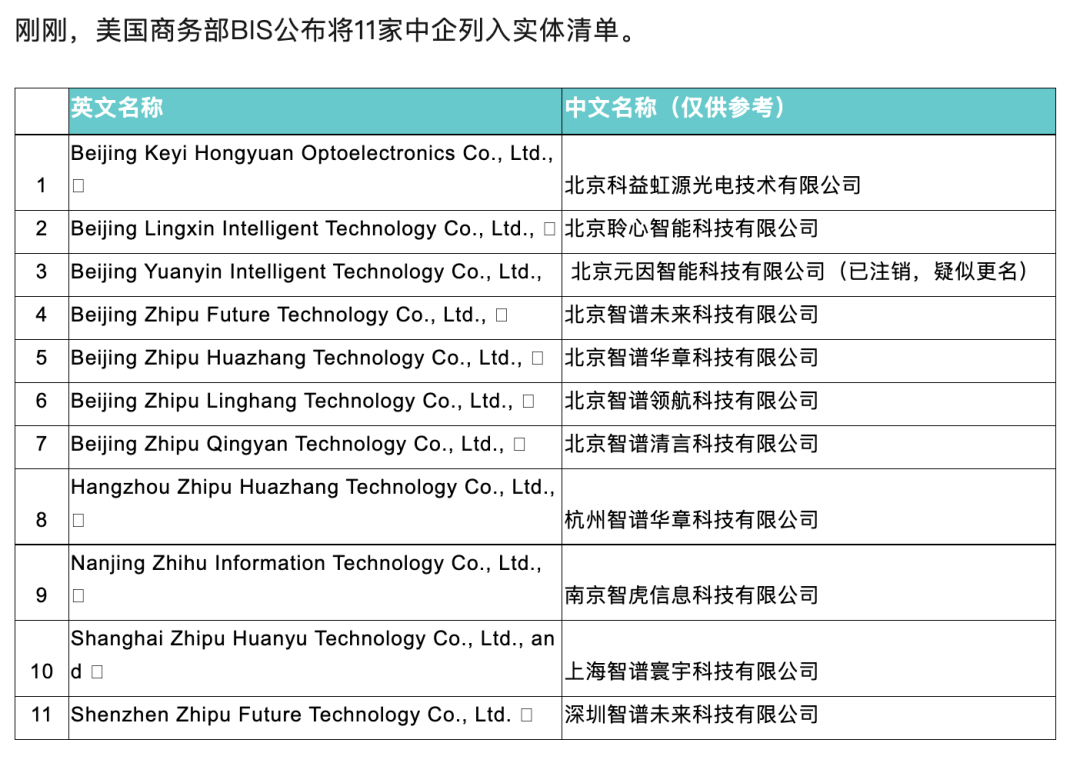
基于上述色盲样本测试的结果,我们可以得出结论:智谱在视觉理解方面优于大多数人工智能模型。OpenAI、Claude和Gemini在测试中均存在色盲现象,而智谱的GLM-4则表现出了正常的色觉。难怪智谱获得了白宫的恐慌认证,《智谱:关于被美国商务部列入实体清单的声明》中对此有所提及。

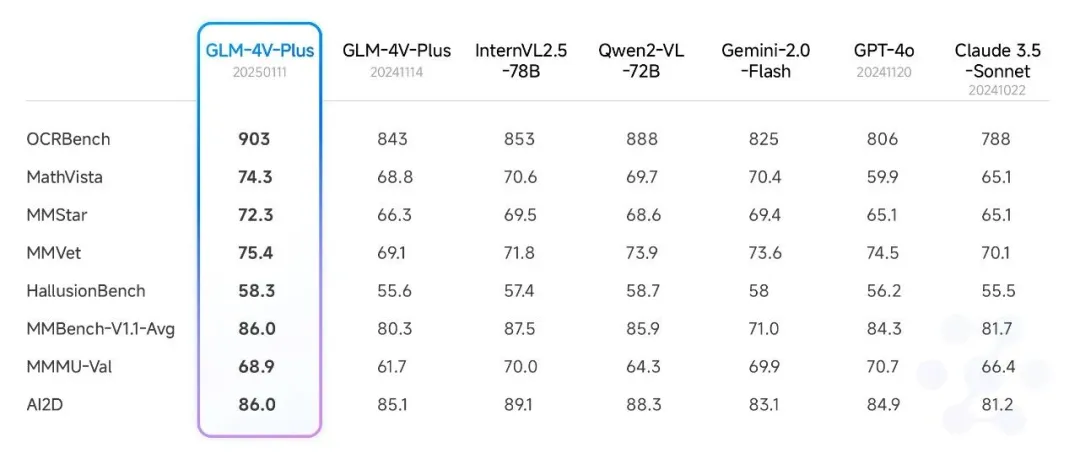
值得一提的是,在智谱被列入实体清单的当天,它们还推出了一款对标GPT-4o的实时API模型,这款模型能够赋能硬件的嘴巴和眼睛,并具备两分钟的记忆能力以及唱歌功能,可以说是当下国内最强的人工智能模型之一。此外,智谱的GLM-4V-Plus也进行了全面升级(网页上的GLM-4在读图时也是基于这个模型),支持了变分辨率功能,更省token!例如,在224 * 224的分辨率下,输入的图像token数仅为原来的3%,同时支持4K超清图像和极致长宽比图像的无损识别。此外,其视频理解模型也进行了更新,支持长达两个小时的视频内容。

从开发者的角度来看,智谱最值得骄傲的莫过于以下四种全免费的模型:语言模型GLM-4-Flash、图像理解模型GLM-4V-Flash、图像生成模型CogView-3-Flash以及视频生成模型CogVideoX-Flash。

最后,需要说明的是,这个测试并不十分严谨,而且我们也应该知道,人工智能模型和人类看图的原理是不同的。但这个测试仍然很有意义:只有当人工智能模型对世界的观察方式与我们相似时,它们才能更好地服务于我们。至于国内其他几家人工智能公司的表现,我们也在进行测试,结果并不理想。如果你也想了解这些模型的色觉表现,可以尝试使用文章中的测试图进行测试,并将结果发到评论区。




相关推荐
-
可灵AI导演共创计划:9部AI电影短片惊艳亮相
这次,名导们以全新的方式参与创作,一部5分钟短片开场便震撼全场。钟馗手持斩鬼剑,在乌漆麻黑的密林中穿行,急促的锣鼓声中,野兔精、蛤蟆精和骷髅树妖接连现身,营造出紧张恐怖的氛围。随着…
-
一天裁员近2000人,在华营收仅占1.5%,50岁的微软为何要持续收缩中国市场?
微软北京办公区(来源:WpBull.comAGI编辑林志佳拍摄) 成立50年之际,老牌AI软件公司微软却在中国难掩衰颓之势,引发市场关注。 4月7日早间,微软全球科技的外包业务供应…
-
芯明智能完成数亿A+轮融资 开远实业领投加速空间智能布局
合肥芯明智能科技有限公司(简称:芯明)近日宣布成功完成数亿元人民币的A+轮融资,这一重要里程碑不仅彰显了资本市场对芯明创新实力的高度认可,更标志着其在空间智能领域的加速布局。本轮融…
-
给大模型一张真实的“脸”,四位AI+硬件创业者展望2025
文章来源:智能涌现 Image source: Generated by AI 如果说2024年的CES上,AI更多是作为独立亮点被少数企业展示;今年的CES 2025,AI与消费…
-
OpenAI谷歌AI激战正酣AGI时代加速到来
2024年,人工智能领域见证了Google与OpenAI的激烈交锋。每当Google高调宣布即将推出重要AI产品时,OpenAI总能以更具竞争力的产品抢先一步,让Google的发布…
-
英特尔出售Altera51%股权给银湖资本 10年估值缩水47.6%
英特尔正式剥离Altera FPGA业务 估值暴跌47.6亿美元 (图片来源:WpBull.comAGI编辑林志佳拍摄) 芯片巨头英特尔近日宣布了一项重大战略调整,正式剥离其十年前…
-
李彦宏:AI应用价值远超模型芯片 文心大模型4.5 Turbo引领开发者未来
4月25日,WpBull.comAGI从百度Create开发者大会获悉,百度创始人、董事长兼CEO李彦宏在武汉现场正式发布了文心大模型4.5 Turbo和文心大模型X1 Turbo…
-
美国芯片EDA巨头断供中国市场 将如何冲击国内产业链
经历两天传闻发酵后,两家美国芯片EDA巨头Synopsys(新思科技)与Cadence(楷登电子)正式官宣确认,美国商务部工业和安全局(BIS)要求其对中国企业断供芯片设计EDA软…
-
Kimi深夜发布k1.5多模态模型性能超GPT-4o和Claude 3.5 Sonnet
编辑 | 伊风 出品 | 51CTO技术栈(微信号:blog51cto) 昨晚十点,Kimi推送了一条令人瞩目的消息。他们以平静的姿态发布了一款SOTA模型——k1.5多模态思考模…
-
AI重塑认知革命:从语言垄断到智能共享的变革
七万年前,人类凭借虚构故事的能力完成了第一次认知革命。一万年前,农业革命让我们从狩猎采集者变成了农民。三百年前,科学革命让我们成为了地球的主宰。而今天,我们正站在第三次认知革命的门…