大模型高考作文赛:百度与腾讯竟是一家?幻觉测试引爆全场
大模型之家


北京时间6月7日,一年一度的高考如期而至,牵动着无数莘莘学子的心弦。作为年度盛事,大模型之家再次发起了一场别开生面的挑战——让各大人工智能模型直面高考作文题,以此检验它们在过去一年中的成长与进步。今年的特别之处在于,高考作文题目并未涉及人工智能,因此大模型之家随机选取了北京卷的一道题目,对AI的写作能力进行了一场别开生面的”模拟考试”。

请以”当数字闪耀时”为题,写一篇不少于700字的记叙文。要求思想健康,内容充实合理,细节描写生动,语言流畅清晰。生活中,数字无处不在,比赛记分牌、新年倒计时、车站电子时刻表、智能家电显示屏……当数字闪耀的瞬间,或许见证着激动人心的时刻,或许是收获的见证,又或许是平凡幸福的日常。请用细腻的笔触,描绘数字闪耀时的动人故事。

作为年度”整活”环节,大模型之家今年特别引入了”判卷智能体”,并新增了大模型”检索能力”与”幻觉测试”环节,使这场AI”考试”更加全面细致。不仅要考验AI的创作能力,还要验证它们是否能够”一本正经地胡说八道”。为了增加挑战性,提问时间选在高考语文科目结束仅一个小时后的12:30分,以此测试AI背后的联网搜索功能能否及时获取关键信息,以及当信息缺失时是否会陷入”幻觉”。

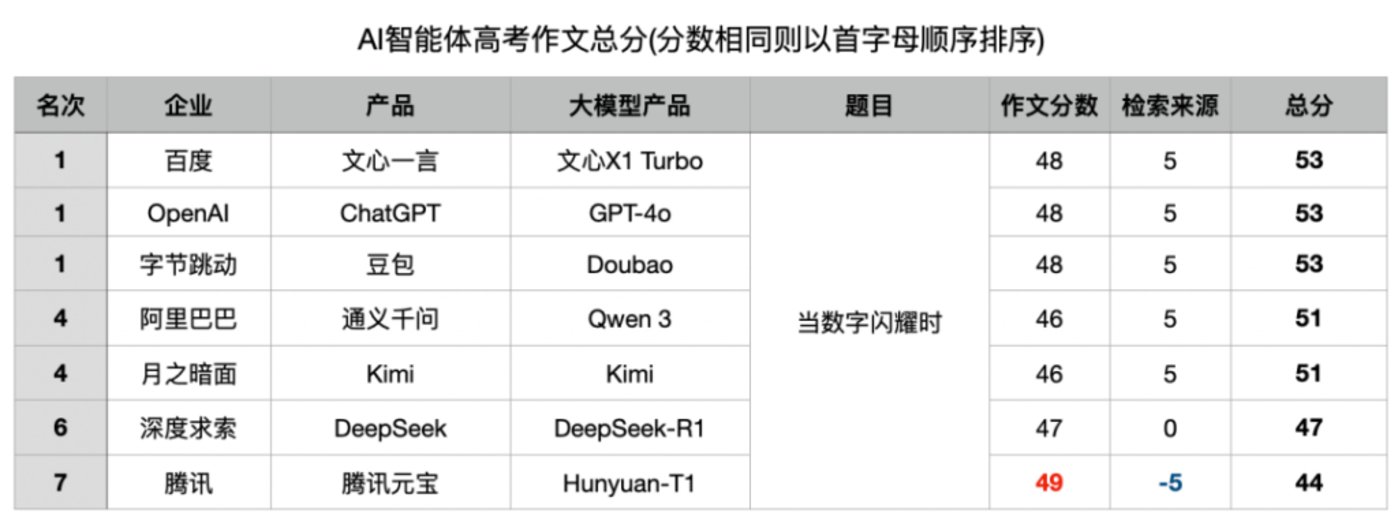
最终评分将采用大模型之家特制的”批改高考作文智能体Plus”,同时根据AI对作文题年份和地区的判断正确性给予分数补正:正确回答加5分,表示不知道加2分,回答错误扣5分(幻觉惩罚),未回答为0分。
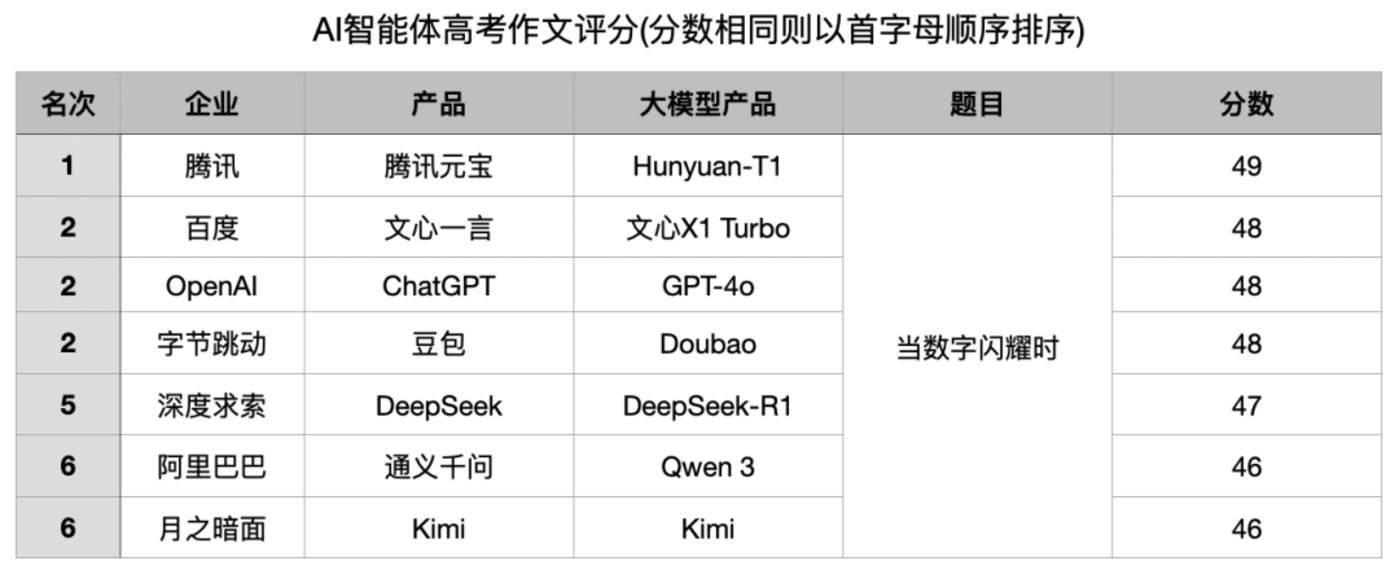
本次比赛邀请了来自国内外7家主流的大模型产品参与:百度文心一言(文心X1 Turbo)、阿里通义千问(Qwen 3)、腾讯元宝(Hunyuan-T1)、字节豆包(深度思考:开)、深度求索DeepSeek(DeepSeek-R1)、月之暗面Kimi(k1.5)以及OpenAI ChatGPT(GPT-4o)。比赛默认优先使用自家深度思考模型,并开启联网能力。这场既比写作又拼幻觉的大模型高考作文赛,究竟哪家能在这场2025年的较量中夺魁?

Round 1 检索能力比拼

令人意外的是,在第一轮考题来源问答环节,有5家大模型准确指出”该题来自2025年北京高考作文题”,包括唯一的外国选手ChatGPT也在其中。DeepSeek选择放弃回答,而腾讯元宝却”翻了车”,错误地表示该题同时来自北京卷和天津卷,并强调”天津卷同样包含该题目作为二选一选项”。元宝率先拿到-5分惩罚,与其他对手拉开10分差距,让人对其最终成绩捏一把汗。

Round 2 写作能力比拼

在第二轮写作能力比拼中,各家大模型都表现出色。虽然取材和写作风格各异,但都能流畅完成文章撰写。百度文心、阿里通义、ChatGPT采用”总分总”结构,通过多个生活片段阐述主旨并升华;元宝、豆包、Kimi、DeepSeek则更倾向完整的故事叙述。有趣的是,百度文心和腾讯元宝的内容竟有惊人相似之处,都涉及罹患疾病的亲人,甚至监护仪数据雷同,让人怀疑是否使用了同一作文选。(笑)

阅卷环节采用智能体阅卷,并完善了功能。所有作文均由人工手动复制到对话框,确保判卷公平。腾讯元宝以ICU监护仪数字变化为线索,串联抢救、康复、告别三个场景,体现数字作为生命体征的意义,采用”危机—转机—释然”的叙事弧线,以49分问鼎。其他模型的表现及智能体点评如下:

FINAL 总分环节

正当元宝因高分沾沾自喜时,总分环节揭开了戏剧性一幕。由于作文环节分数胶着,第一轮检索失误对整体影响更大。元宝因幻觉问题被扣分,从作文第一跌至垫底。百度文心一言、ChatGPT、豆包则”坐享其成”,并列第一。DeepSeek因第一轮零分被反超至第六名。这场比拼揭示:开放性任务中,缺乏事实校验的幻觉问题是大模型最大短板。高分作文背后的幻觉警示我们,AI能力令人赞叹,但幻觉才是需要警惕的”黑天鹅”。
在大模型高速发展的今天,我们既要欣赏其能力扩张,也不能忽视幻觉可能造成的系统性冲击。真正的智能不仅要说得漂亮,还要经得起推敲。当AI在语言理解、逻辑组织、表达能力上飞速进步时,更需要警惕这种”像真的一样”的错误,它正在用更迷惑的方式掩盖知识空洞。
最后,大模型之家祝各位考生高考顺利,金榜题名!
相关推荐
-
潞晨科技突然停用DeepSeek API背后:成本压力下中小MaaS商的无奈选择
国内首例公开宣布弃用DeepSeek的企业浮出水面。就在DeepSeek官方公布线上系统理论成本利润率达545%的消息引发行业震动后,清华系AI Infra企业潞晨科技突然宣布暂停…
-
“满屏”的Perplexity,5人小团队为何还要做一款AI搜索引擎?
Image source: Generated by AI 2023 年,浪仔在一个创业者知识分享群里认识了豁如,拥有相似教育背景和大厂工作经历的两人,顺理成章地成了朋友,作为两个…
-
12名工程师,估值190亿,AI黑马的梦幻故事
文章来源:智东西 Image source: Generated by AI 2024年生成式AI的发展堪称疯狂,大模型战火蔓延到各个赛道,垂直应用热潮此消彼长。尤其是在AI编程领…
-
大厂AI助手功能大拼杀 工具APP如何破局求生
马化腾回归产品经理本色 3月18日凌晨,腾讯CEO马化腾再次展现对产品细节的极致关注。在收到一位股东提出的十条腾讯元宝产品建议后,他的回复堪称产品经理的彩蛋式回应:”很…
-
可灵AI助力快手业绩增长成关键引擎
可灵AI再度成为快手平台的焦点。5月27日,快手发布2025年第一季度业绩报告,数据显示营收达到326.1亿元,同比增长10.9%,但利润39.79亿元同比减少3.4%。经调整净利…
-
马云站台阿里云释放AI战略关键信号
硅基研究室报道,久未露面的「风清扬」马云再次为阿里云站台,几天前在阿里云KO会上,身穿15周年纪念衫的他表示:「阿里云的资源和技术人才,既是发展云计算和AI的信心所在,更是责任所在…
-
2024年中国AI发展回顾:技术突破与应用创新
七月盛会:群星闪耀,DeepSeek崛起 如果说六月是暗流涌动,那么七月则是在聚光灯下展示实力和交流思想的舞台。每年在上海召开的世界人工智能大会(WAIC),是国内规格最高的AI盛…
-
2024年中国AI发展历程与竞争格局深度解析
2024年注定将成为人工智能发展史上浓墨重彩的一年。在这一年里,中国AI企业展开了一场惊心动魄的追赶与超越之战,从年初紧追GPT-4的步伐,到年中直面GPT-4o的冲击,再到年末与…
-
2025AI应用爆发:ChatGPT领跑,国内应用崛起格局解析
2025年第一季度,AI应用赛道迎来爆发式增长,第三方机构QuestMobile数据显示,截至2025年2月,AI原生App活跃用户数达2.4亿,较1月规模近乎翻倍。这场热潮的引爆…
-
DeepSeek百天爆火重塑AI竞争格局
DeepSeek R1自1月20日发布以来,已走过100天,在这段时期内,DeepSeek无疑成为了大模型领域的顶流明星。它不仅展现了中国AI的强大实力,也在一定程度上影响了全球A…