DeepSeek与颜文字:大模型圈新格局解析
这两天的大模型领域可谓是风起云涌,一边是DeepSeek凭借其低成本高性能的表现惊艳四座,引得无数技术大牛点赞;另一边社交媒体和技术论坛上却掀起了一股奇特的”颜文字”热潮,”QwQ”、”QVQ”等符号频频出现,虽然初看令人费解,但圈内人一眼就能明白,这指的是阿里通义千问开源的系列模型。今年9月,阿里云正式发布通义千问新一代开源模型Qwen2.5系列,一口气推出从0.5B到72B参数的多个版本,全面覆盖各类应用场景,不仅成功跻身全球顶尖开源模型行列,更在多模态、多语言能力上表现卓越,成为众多企业和开发者的首选。不仅如此,Qwen团队近期动作频频,接连开源数款创新模型,持续引发行业关注。


Qwen团队的命名风格颇具特色:QVQ被称为”两眼瞪”,QwQ则像键盘误触产生的表情,这些”代码世界的颜文字”似乎在严肃科研之余,还藏着几分技术大牛的幽默感。或许Qwen的命名哲学就是:名字随意,实力才是硬道理?

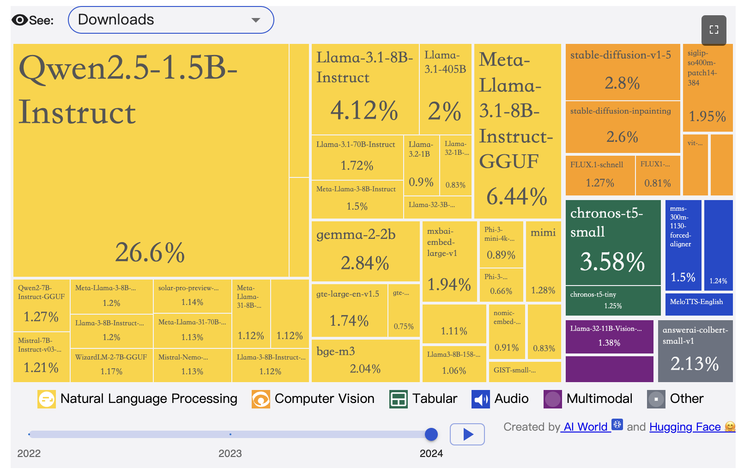
提起生成式AI,人们往往首先想到OpenAI、谷歌、Meta等国际巨头,但近年来,来自东方的AI力量正逐渐崭露头角。DeepSeek和阿里的通义千问Qwen,正在各大AI模型性能榜单上表现抢眼,成为行业焦点。要知道,过去提及国产大模型,总带着”追赶者”的标签,但现在中国开源力量正用实力证明,他们不再是旁观者,而是能与OpenAI、Meta等巨头正面交锋的强劲对手。Hugging Face 2024年度盘点数据显示,Qwen2.5-1.5B-Instruct下载量占比高达26.6%,大幅超越Llama 3和Gemma等明星开源模型。虽然下载量不能完全代表实力,但无疑是人气的重要指标。Qwen2.5-1.5B-Instruct的超高下载量,不仅反映了其在当前的应用价值和受欢迎程度,更彰显了中国公司开发的开源大模型在国际舞台上的影响力。实际上,Hugging Face平台上2023年下载量最高的开源模型,同样来自中国社区——智源研究院的BGE-base。

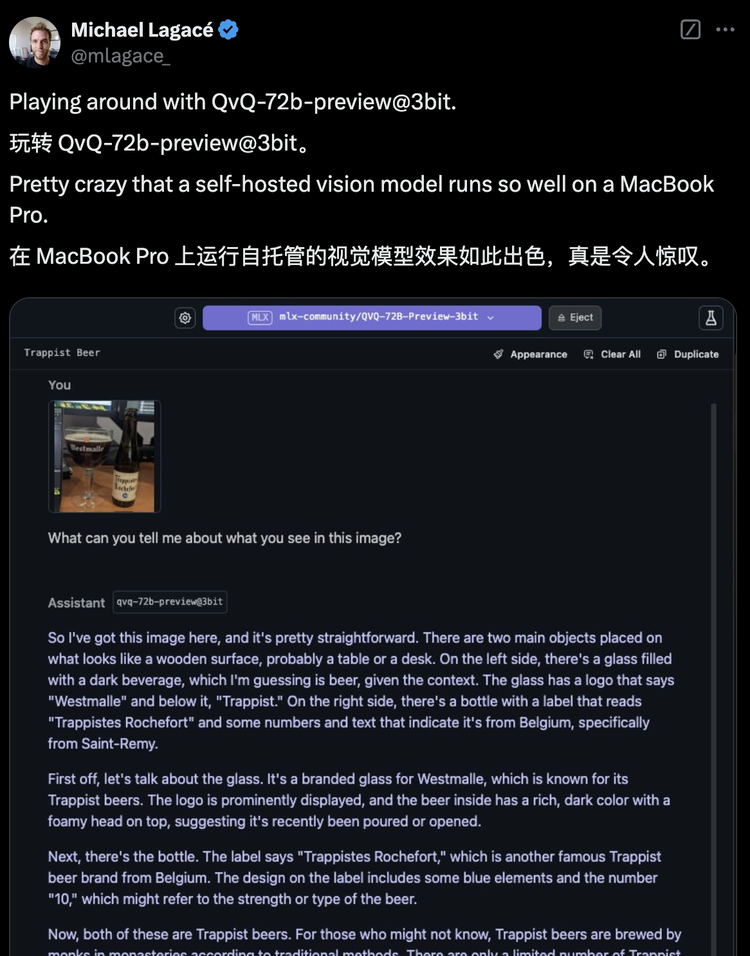
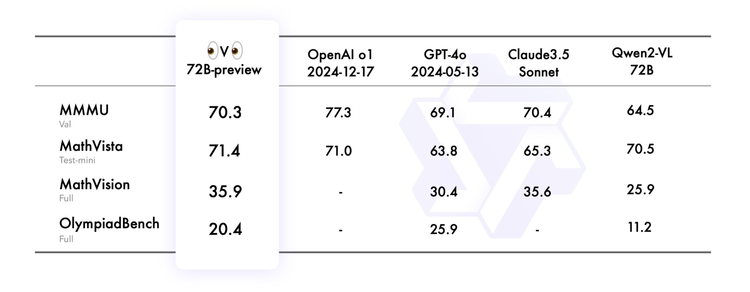
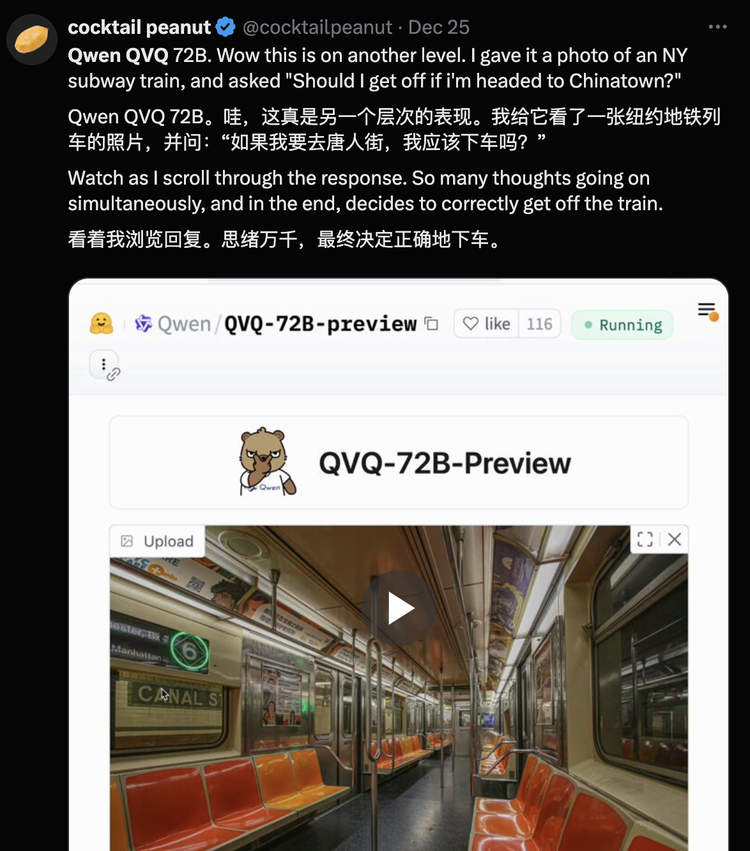
对于Qwen的亮眼表现,国外网友也纷纷点赞,甚至开始玩梗:”扎克伯格可能正在偷偷比较,你用的是Qwen还是Llama?”1、圣诞大礼包QvQ,首个开源多模态推理模型Qwen团队送出的”圣诞礼物”QVQ-72B-Preview,是一款能够分析图像并进行推理的新兴开源模型。虽然仍处于实验阶段,但初步测试显示,它在视觉推理任务中表现优异。QVQ通过逐步思考解决问题,类似OpenAI的o1或Google的Flash Thinking等”逐步思考”模型。用户只需提供图像和指令,系统就会分析信息,在必要时进行深入思考,并以置信度分数呈现答案。在底层架构上,QVQ-72B-Preview基于Qwen现有的视觉语言模型Qwen2-VL-72B构建,并新增了思考与推理能力,成为首个此类开源模型。在Macbook Pro上的基准测试中,开源的QVQ全面超越前身Qwen2-VL-72B-Instruct,准确度已接近OpenAI的o1和Claude 3.5 Sonnet等闭源模型。一位网友用纽约地铁照片测试QVQ,提问”去唐人街应该在哪站下车?”模型最终给出正确判断,展现了有效的推理能力。

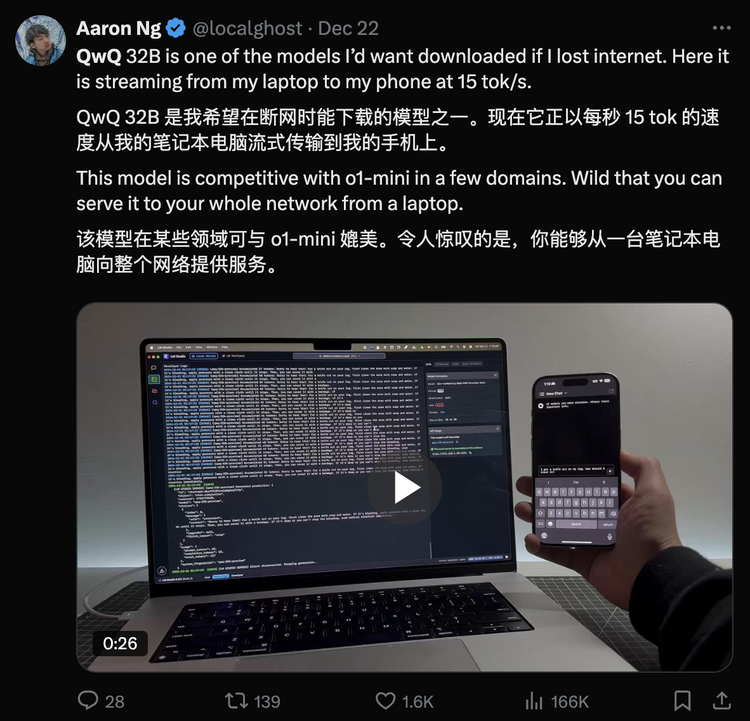
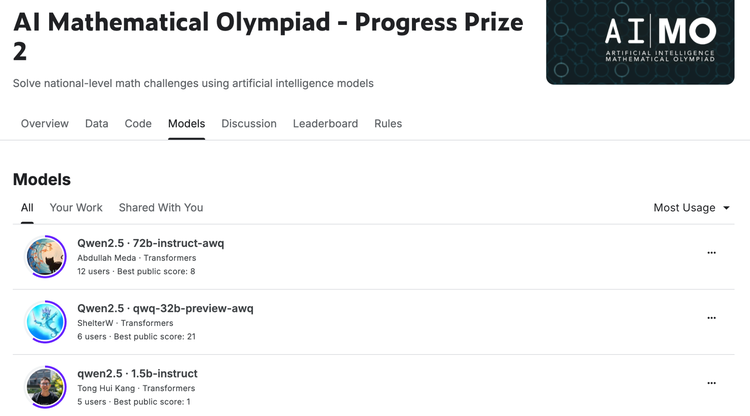
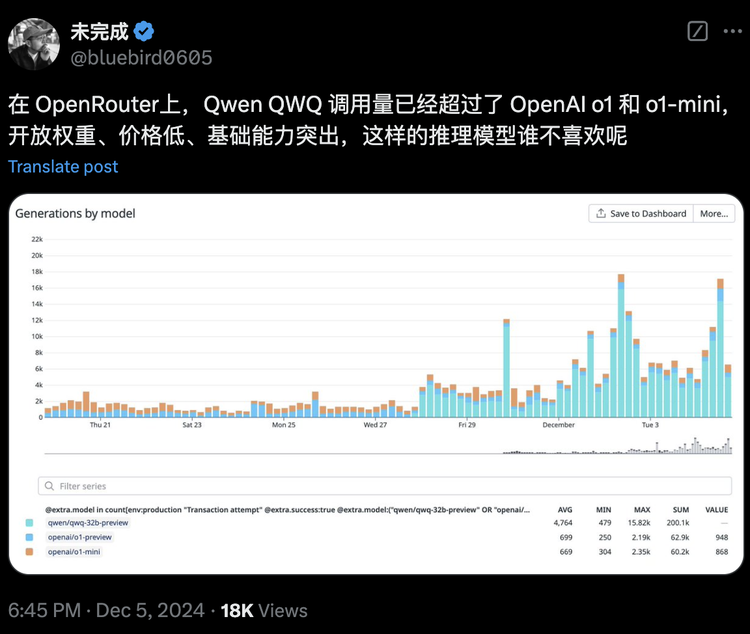
2、获陶哲轩点赞的开源推理模型QwQ时间回溯到2024年11月28日,Qwen团队开源了首个专注于推理能力的AI模型QwQ-32B-Preview。尽管参数量仅为32B,但在GPQA、AIME、MATH-500和LiveCodeBench等多个评测中,QwQ均取得优异成绩,部分测试甚至超越o1。QwQ具备深度自省能力,能够质疑自身假设并进行自我对话,从而解决复杂问题。虽然仍处实验阶段,但其强大分析能力和独特推理方式已吸引广泛关注,连数学界泰斗陶哲轩都公开称赞:”QwQ的表现超越了以往所有开源模型。”在AIMO(AI数学奥林匹克)挑战赛中,Qwen系列模型位列前三,成为参赛者最常用的工具之一。”开放权重、价格低、基础能力突出,这样的推理模型谁不喜欢呢”。
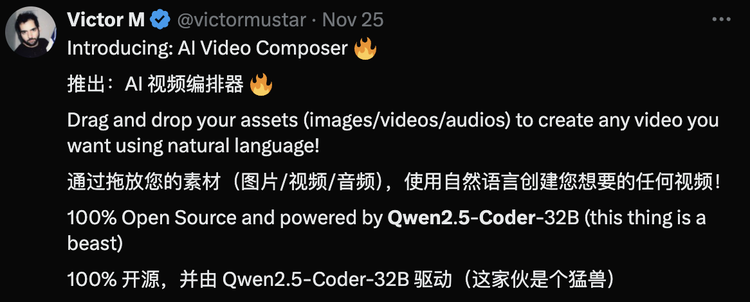
3、Qwen2.5-Coder:开源界的”代码扛把子”Qwen2.5系列的发布,尤其是Qwen2.5-Coder的亮相,在AI圈内引发热烈讨论。尽管模型体积相对较小,但Qwen 2.5 Coder32B在HumanEval等编程基准测试中表现优异,可与前沿模型媲美。海外技术博主调侃:”现在大家都在关注OpenAI、谷歌、Anthropic,却忽略了Qwen这个’狠角色’。”Qwen可是首个能与Claude Sonnet和GPT-4o正面交锋,还能在本地电脑运行的开放权重模型。许多体验者表示”真香”。相比之下,DeepSeek模型虽然性能卓越,但体积较大,本地运行有一定难度(彼时deepseek v3尚未发布)。Qwen2.5-Coder的出现,对开源社区意义重大。更值得称赞的是,阿里云将完整技术报告公开共享,毫无保留地与社区共享成果。开发者还基于Qwen2.5-Coder创建了AI视频编辑器Video Composer,用户可通过拖放素材(图片、视频、音频)并输入自然语言,让模型生成新视频(基于FFMPEG技术)。
4、满足多样化需求,全球化的QwenQwen的另一大优势在于其广泛的适用性。Qwen2.5系列不仅面向技术专家和大型企业,更致力于让普通用户轻松使用。从适用于资源受限设备的0.5亿参数版本,到满足企业级应用需求的720亿参数版本,Qwen提供了丰富的选择。在日本,阿里云与东京大学初创企业Lightblue合作,借助阿里云架构和Qwen LLM技术优化模型,显著提升东亚语言准确性。知名投资人Coinbase前CTO Balaji Srinivasan也公开认可Qwen的多模态和多语言能力。如今,全球各地的工程师都能轻松获取Qwen各类模型。更难得的是,Qwen在处理多种语言方面表现出色,即使是缅甸语、孟加拉语等全球AI训练数据较少的”小语种”,也能应对自如。相比之下,Meta的开源AI模型Llama主要针对英语应用。不少日本开发者在认真研究Qwen2.5的技术报告。
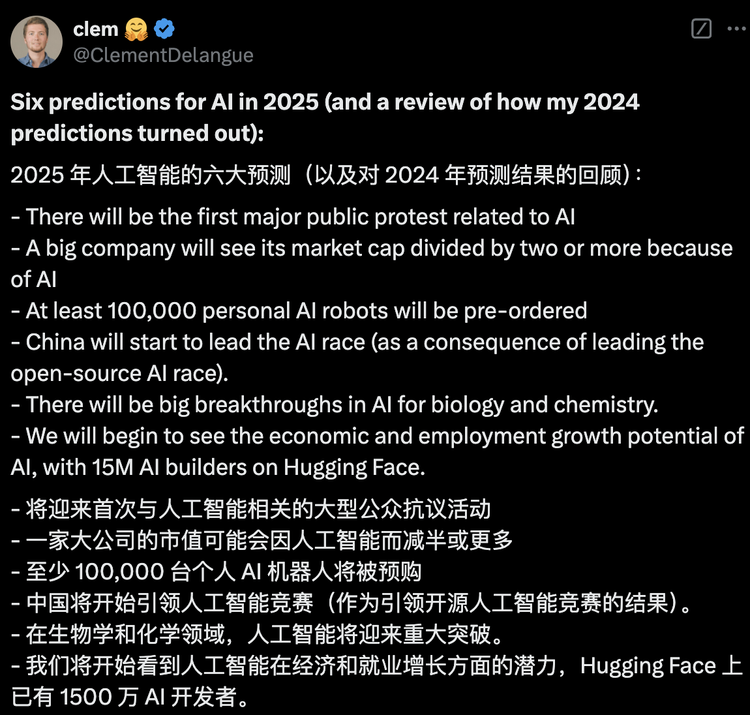
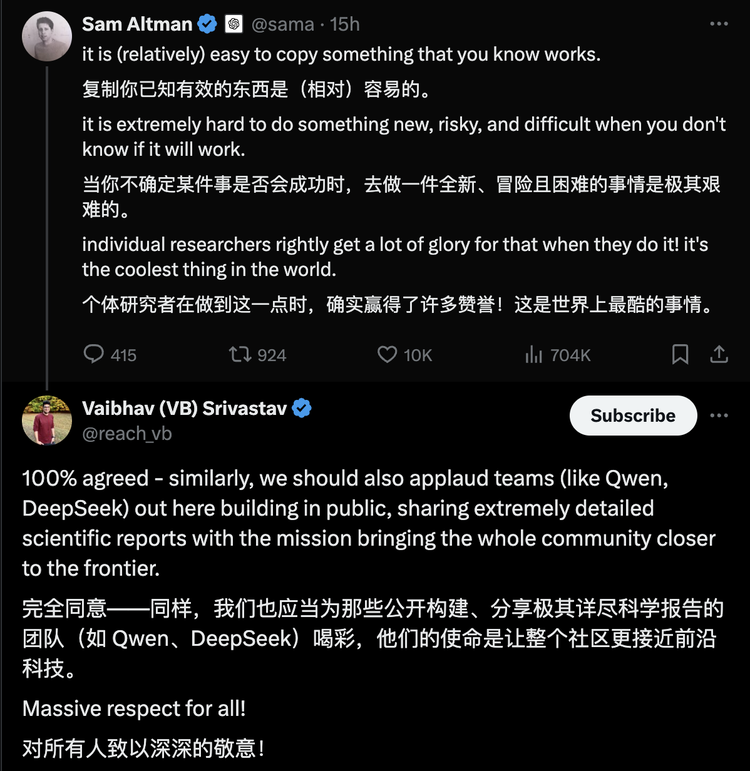
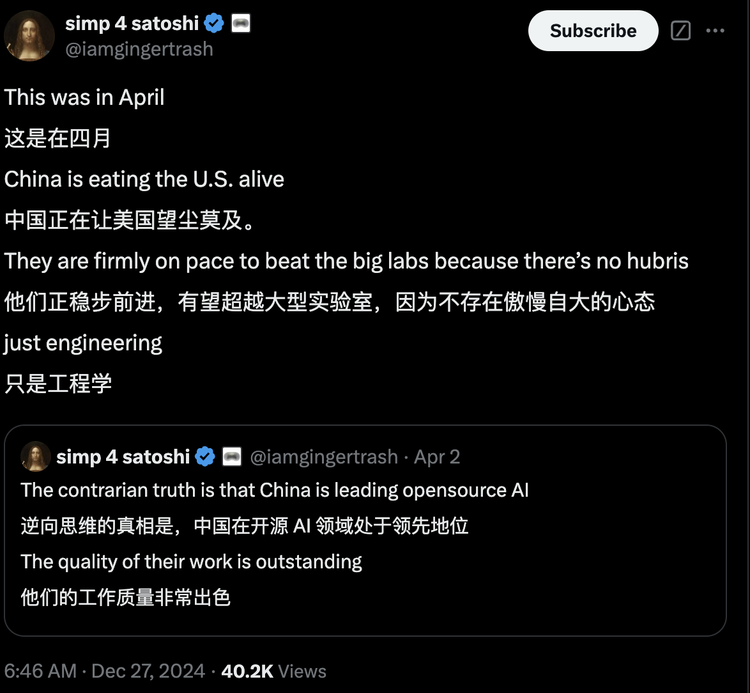
5、中国AI开源势力崛起Qwen等中国AI模型的崛起,为国内企业提供了更多选择和发展空间。在当前国际环境下,这一意义尤为重大。更关键的是,它们不仅是”备胎”选项,而是真正具备与美国顶尖技术掰手腕的实力。Qwen的意义远不止技术层面,其背后代表的开放协作精神表明,中国在AI领域并未掉队,反而通过开源展现出强劲竞争力。事实证明,GPU限制并未阻碍中国AI发展。如果这一势头持续,中国很可能在LLM市场占据更核心地位。当开源模型比Meta(发布带有特殊Llama研究许可的模型)还要开放,当人人都能使用性能不输甚至更强的开源模型时,谁会拒绝呢?CNBC近期发文指出,中国在LLM领域取得显著进展,Qwen、DeepSeek等模型在某些方面已超越美国竞争对手。中国公司正积极拥抱开源模式,推动AI技术发展和应用,以促进创新并扩大全球影响力。文章认为,中国正在AI领域快速崛起,其AI模型已具备相当国际竞争力,并努力构建自主可控的AI生态。Hugging Face CEO Clem在其2025年AI预测中提到,中国将开始引领人工智能竞赛,主要得益于其在开源AI竞赛中的领先地位。Sam Altman最近感叹:”复制相对容易,而做全新且有风险的事情极其困难。”但也表示,成功的个体研究人员理应获得赞誉,因为这”是世界上最酷的事”。评论区中,Vaibhav Srivastav回应:”公开共享不应被忽视”,并点名Qwen和DeepSeek团队,他们同样值得喝彩。开放心态加上对工程实践的重视,正在加速中国AI行业发展。曾经被认为受半导体限制和计算能力制约的中国AI产业,正以开源模型为代表向世界证明,它有能力与全球顶尖水平同台竞技,并在全球范围内创造更大价值。






相关推荐
-
Manus通用AI agent能否真正改变工作流
Manus的走红速度之快,质疑声也随之而来。3月6日凌晨,华人团队Monica.im突然发布Manus,自称为”全球第一款通用agent产品”。与只能提供文…
-
抖音接入豆包AI能力 打破平台割裂提升用户体验
抖音App近期悄然测试接入豆包App的AI能力,并在应用内开放了两个显著入口。一个位于短视频界面,与点赞、评论、转发等核心功能并列;另一个则出现在消息列表中。这一举措的核心目标在于…
-
国产大模型2025考研数学排行榜:Kimi与DeepSeek破百创新高
2024年即将步入尾声,这一年里,大模型的智力水平究竟实现了怎样的飞跃?就在上周日,2025考研初试刚刚落下帷幕,我们抓住这个时机,选取考研数学试卷作为测试工具,对几款主流国产大模…
-
没有博士学位却开启了GPT时代,奥特曼盛赞Alec Radford,爱因斯坦级天才
Image source: Generated by AI 几天前,OpenAI 宣布组织结构调整,裂变成了一家营利性公司和一个非营利组织。与此同时,OpenAI CEO 山姆・奥…
-
OpenAI组建NextGenAI联盟 探索机器人模型未来
随着开源AI模型在全球范围内发挥日益重要的作用,OpenAI却因被指不够开放、过度商业化而饱受争议。这家曾经以宏伟愿景——通过AI研究促进友好型人工智能发展、造福全人类——赢得广泛…
-
博乐仁:中国创新引领全球增长 西门子助力AI转型
WpBull.comAGI 3月23日消息,由国务院发展研究中心主办、中国发展研究基金会承办的中国发展高层论坛2025年年会于今日上午在北京隆重开幕。本届论坛聚焦”全面…
-
OpenAI成功为自己制造了危机
文章来源:AI燎原 Image source: Generated by AI OpenAI的算盘失算了。 OpenAI将一场原本可以2个小时讲完的发布会,拆成了12天,每天讲15…
-
芯明智能完成数亿A+轮融资 开远实业领投加速空间智能布局
合肥芯明智能科技有限公司(简称:芯明)近日宣布成功完成数亿元人民币的A+轮融资,这一重要里程碑不仅彰显了资本市场对芯明创新实力的高度认可,更标志着其在空间智能领域的加速布局。本轮融…
-
海光信息并购中科曙光,国产算力巨头重组应对市场挑战
5月25日晚间,海光信息(688041.SH)与中科曙光(603019.SH)同时发布公告,正式宣布双方将进行重大资产重组。根据方案,海光信息将通过向中科曙光全体A股换股股东发行A…
-
OpenAI谷歌AI激战正酣AGI时代加速到来
2024年,人工智能领域见证了Google与OpenAI的激烈交锋。每当Google高调宣布即将推出重要AI产品时,OpenAI总能以更具竞争力的产品抢先一步,让Google的发布…