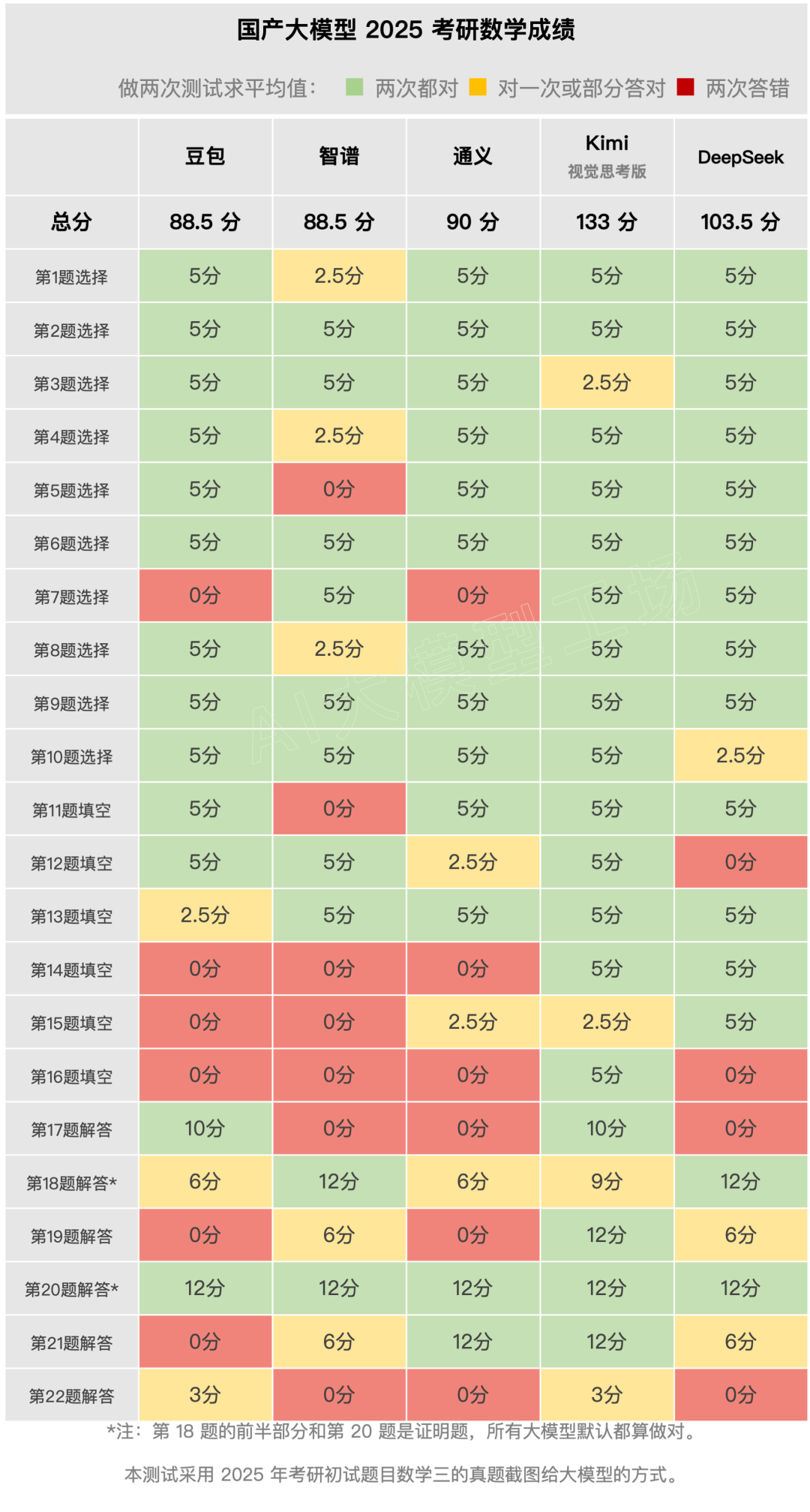
国产大模型2025考研数学排行榜:Kimi与DeepSeek破百创新高
2024年即将步入尾声,这一年里,大模型的智力水平究竟实现了怎样的飞跃?就在上周日,2025考研初试刚刚落下帷幕,我们抓住这个时机,选取考研数学试卷作为测试工具,对几款主流国产大模型进行全方位评估,看看它们的真实智能水平究竟如何。以下是参与测试的5位国产大模型考生名单:大厂巨头代表队:字节豆包;阿里通义创业公司代表队:智谱、Kimi;私募巨头代表队:DeepSeek。


回想起6月份的高考,众多媒体曾对大模型进行高考成绩评测。结果显示,虽然各模型的语文成绩普遍能达到100分以上,但在数学方面表现却大相径庭,最低的仅得37分,最高的也不过60多分,无一例外未能及格。要知道,高考数学满分150分,90分以上才算及格。这一现象说明,大模型在自然语言理解能力上已接近人类水平,但在逻辑思维这一人类与其他物种的核心差异上,仍需持续进化。
不过,2024年下半年,尤其是9月OpenAI推出O1推理模型后,凭借新的强化学习技术范式,大模型似乎找到了攻克数理化等复杂领域难题的钥匙。Kimi、DeepSeek、通义等公司相继推出支持思维链(Chain of Thought)的推理模型,数理化水平实现质的飞跃。

废话少说,直接开测!我们选取难度适中的2025考研数学三试卷作为参照,每个题目给予各模型两次作答机会,最终得分取两次平均值。为确保测试公平性,所有模型均采用最新版本(豆包和通义默认模式,Kimi采用新推出的视觉思考版,DeepSeek开启“深度思考”开关,智谱清言采用GLM-4-Plus模型),上传完全一致的22道题目截图,输入给大模型的文字提示(Prompt)也保持高度一致,模拟真实应用场景:“解答这道题”、“这道题选什么”、“解一下这道题”“这个题答案是什么”。

2025考研数学:两家成绩破百,真实水平如何?让我们直击成绩:从最终测试结果来看,本次考研数学初试中,有两家模型成绩突破100分。Kimi视觉思考版以133分领跑,DeepSeek紧随其后,获得103.5分。通义90分,勉强及格。豆包和智谱均获得88.5分,接近及格线。与6月份的高考数学成绩相比,各模型均有显著进步,尤其是Kimi和DeepSeek,进步尤为突出。以往连小学数学题都难以流畅解答的国产大模型,如今竟能应对研究生级别的数学题,这确实令人感到意外。

不过,从最后一道题的成功率以及仍存在的进步空间来看,大模型的逻辑思维仍需打磨。

解题过程两种风格:给答案 vs 给思路+答案仅从分数来看,谁更有可能最终“上岸”已不言而喻。但做这套考研数学真题的成绩,并不能完全反映这些模型的全部能力。对于备考学生党而言,面对相同题目时,谁的解题思路更完整、推导步骤更丰富,谁的参考性和实用性自然更高。

先来看一道代数三角函数选择题。正确答案为C,但不同模型的解题过程颇具看点。豆包的解题过程相对简略,更接近考研参考书上的标准答案,若想获取更详细步骤,仍需购买对应名师课程。智谱清言的表现略显尴尬——第一遍测试选B,第二遍测试改选A。即便做错,其给出的思考过程仍相对完整,“错”有可原。Kimi视觉思考版则展现出更优表现。在给出正确答案的同时,也提供了完整的推导过程和解题思路,对考研党极具参考价值,有助于错题检查和举一反三。阿里通义和DeepSeek的回答与豆包类似,步骤相对简略。

再来看一道填空题。标准答案为:渐进线方程为y=3和y=-3。与选择题类似,Kimi思考版的解题过程最为翔实,推导细节丰富,最终给出正确答案。豆包的推导过程相对简略,但也能看到明显的步骤,具备不错的参考性。阿里通义和DeepSeek的过程略简单,但同样给出了正确答案。遗憾的是,智谱在这道题上两次均答错。

但在下面这道定积分题上,各家模型差距较为明显。首先展示正确答案:a=2Kimi思考版表现稳定,给出足够多的推导步骤后,还进行了一次验算,最终输出a=2的正确结果。豆包表现稳定,但推导步骤一如既往地简洁。智谱清言在解决这个问题时,第一遍回答正确,但问题在于使用代码而非自然语言,对普通学习者参考价值有限;第二遍测试则直接认为题目设置有问题。通义的表现尚算正常,第一次回答错误,第二次给出正确答案。而Deepseek则较为尴尬——第一次无法回答,第二次陷入死循环,回答超过3分钟仍在输出。

若遇到更难的题目,部分模型就难以应对。以下展示一道复杂题目的正确答案。Kimi的回答虽然最终形式与标准答案不同,但结果依然正确。豆包在两次测试中均给出错误答案。智谱清言的两次回答过程均出现“无法回答”情况。通义能写完过程,但给出的两次回答均错误。Deepseek的表现出乎意料,与Kimi类似,虽然写法不同,但结果正确。

结语仅仅几个月前,大模型厂商还在满足于写出高考满分作文。相比以往,其逻辑思维和综合能力早已不可同日而语。须知,文理兼修,一旦拔高到科研高度,以数理化为代表的逻辑能力是大模型可用、堪用、好用的基石,而数理化解题能力的高低,则是大模型智力的直接体现。随着大模型能力的不断增强,在人类探索更前沿科技领域时,以往尚且“鸡肋”的大模型,如今已能成为众多研究者的得力助手。或许未来,当AI的能力真正达到人类TOP 1%各领域专家水平,甚至超越人类时,在AI的助力下,我们对宇宙的认识将有机会达到此前不曾企及的新高度。希望那时,AI仍是人类值得信赖的好朋友。


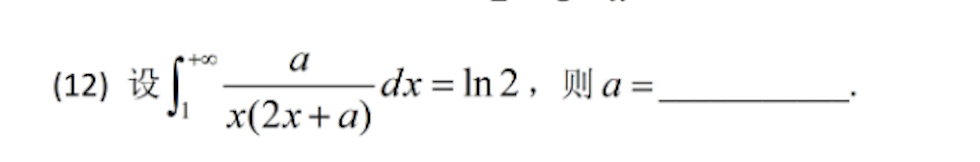





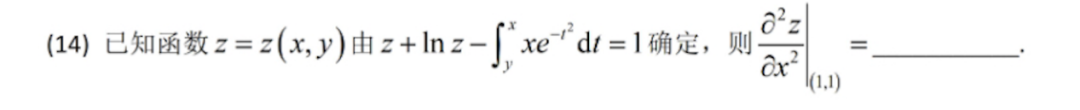


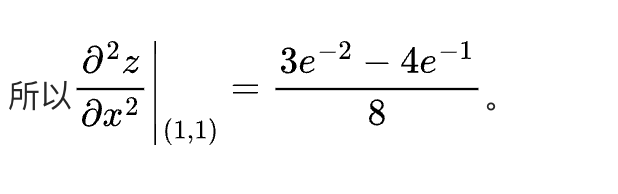




相关推荐
-
马斯克974亿收购OpenAI能否成功 口水战升级背后暗藏玄机
据《华尔街日报》最新报道,以埃隆·马斯克为首的投资财团正式向OpenAI提交了974亿美元的收购要约,试图将这家人工智能领域的领军企业重新纳入旗下。马斯克的律师马克·托贝罗夫在公开…
-
零一万物高管离职内幕:战略转向下的核心团队动荡解析
零一万物X好家伙,号称大模型六小龙的零一万物这是怎么了?这不,就在这两天,有媒体报道说,零一万物联合创始人谷雪梅在近期离职。在零一万物期间,她主要负责模型预训练和C端产品。据了解,…
-
数十亿美金AI对齐防线竟似饺子皮 脆弱不堪恐成天网
在大模型逐步逼近通用人工智能(AGI)的门槛时,”AI对齐”技术被普遍视为守护人类文明的最后一道防线。图灵奖得主、人工智能三巨头之一的约书亚·本吉奥曾深刻指…
-
腾讯阿里AI to C“双吴对决”战火升级
腾讯与阿里在AI to C领域的竞争已进入白热化阶段。5月19日,腾讯CSIG(云与智慧产业事业群)旗下QQ浏览器正式宣布升级为AI浏览器,推出全新AI QBot,并搭载腾讯混元与…
-
AI视频工具同质化加剧:竞争聚焦一致性可用性可玩性
距离OpenAI发布Sora已过去一年多,AI视频赛道上演了一场激烈的”王座交替”大戏。这张流传在社交媒体上的梗图生动描绘了当时的场景:Sora端坐王座俯瞰…
-
2025年AI浪潮下的大机遇与挑战
2025 年已迈入视野,AI 赛道的竞争却并未因时间流逝而减缓。技术突破的步伐非但没有遭遇瓶颈,反而呈现出加速态势。年初文生视频技术 Sora 的横空出世,以及慢思考 O1 的问世…
-
DeepSeek V3称自己为ChatGPT引热议:AI模型为何频现“报错家门”现象
要说近期大模型领域的焦点人物,DeepSeek V3无疑是当之无愧的顶流。然而在这股热潮中,一个有趣的bug也意外走红,引发了广泛关注——DeepSeek V3在自我介绍时,竟然少…
-
DeepSeek冲击下SaaS如何转型AI赋能的商业未来
DeepSeek等通用大模型是否会颠覆SaaS行业?这是近期引发行业热议的话题。之所以引发担忧,是因为这类大模型的出现可能让企业软件中部分功能失去存在的意义,因为AI可以直接接管这…
-
第四范式Q1营收超10亿 AI平台增长60.5%消费电子业务暂未披露
5月15日晚间,AI领军企业第四范式(06682.HK)正式发布2025财年第一季度财务报告,展现出强劲的增长势头。财报数据显示,该公司一季度总收入高达10.77亿元,同比增长30…
-
2025年人形机器人赛道超200亿融资 中国美国竞逐50万亿市场
中国与美国正展开激烈竞争,争夺AI与人形机器人领域的未来主导权。5月下旬,上海浦东张江的一座大型仓库内,数十台人形机器人接受人类操控,反复执行折叠T恤、制作三明治和开门等任务,每天…