阿里Qwen3系列开源:性价比多模态大模型矩阵抢市场
阿里云Qwen3系列重磅发布:重塑大模型开源标准
凌晨时分,阿里云正式揭晓了备受瞩目的Qwen3系列模型,一口气开源了从0.6B到235B共8款模型,包括2个MoE大模型和6个Dense大模型,构建起阿里完整的模型矩阵。此次Qwen3的开源动作,不仅刷新了大模型标准,更标志着在“后DeepSeek R1”时代,以阿里为代表的国内大厂正以产品化思维,凭借高性价比和多模态能力,全方位抢占DeepSeek的市场影响力。Qwen3系列在架构、性能、推理速度和应用方向上均实现了显著突破,再次拉高了世界开源标准。
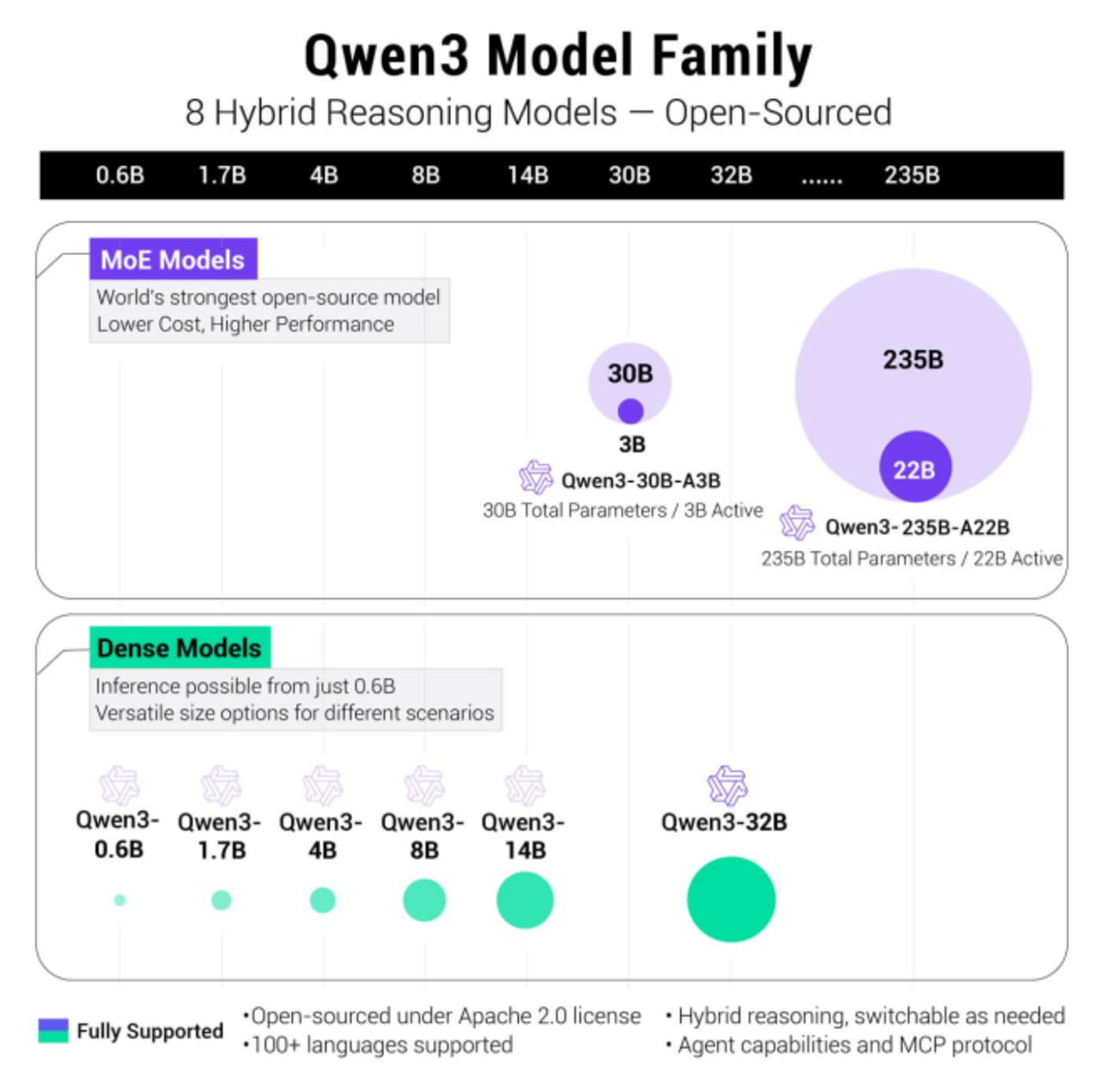

Qwen3系列的技术革新与全面超越
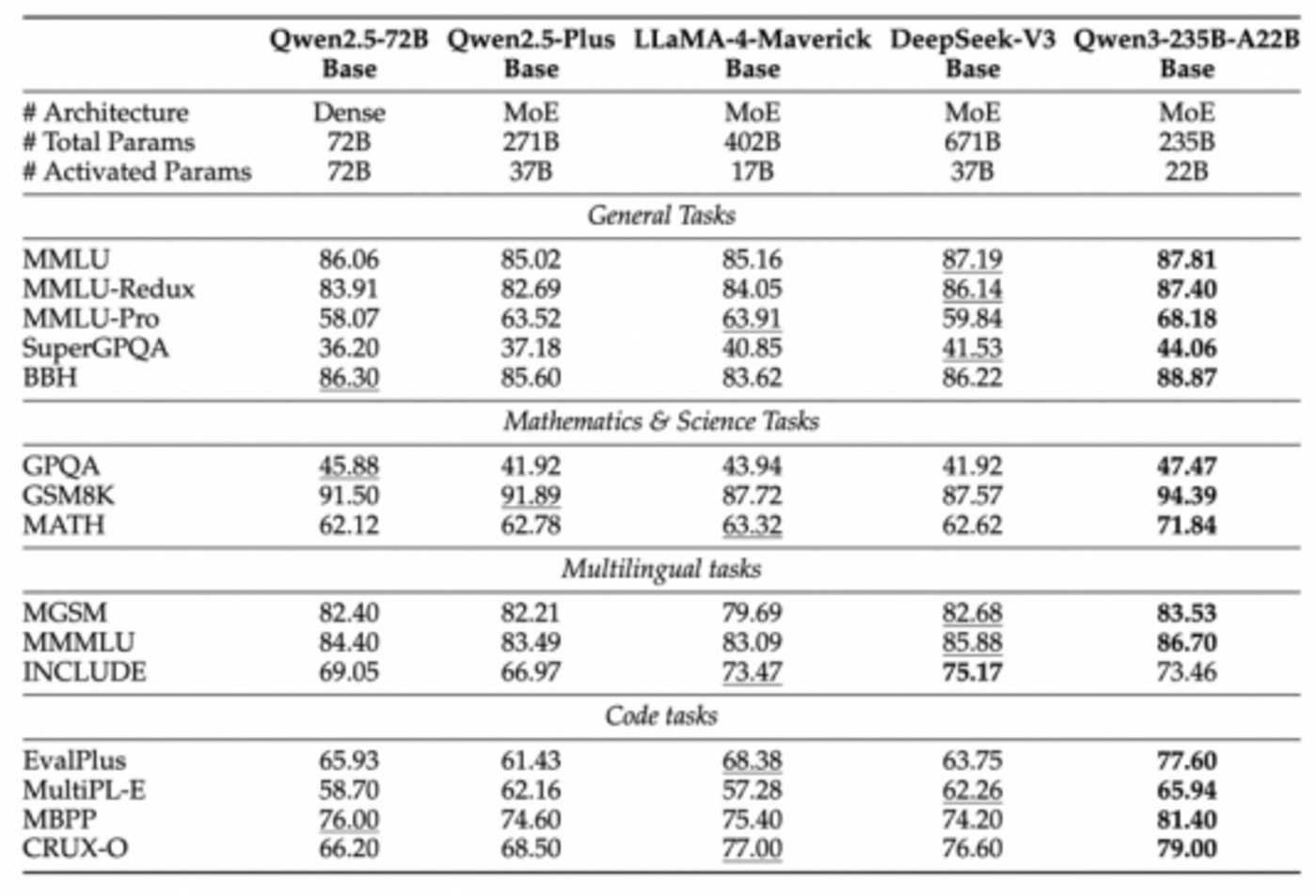
Qwen3系列采用了创新的MoE(混合专家)架构,旗舰模型Qwen3-235B-A22B拥有约2350亿总参数量,但在每次推理时仅激活约220亿参数,展现出极强的耐打性能。在综合能力、代码与数学、多语言能力、知识与推理等多项基准测试中,Qwen3均能与DeepSeek R1、OpenAI o1、o3-mini、Grok 3和谷歌Gemini 2.5 Pro等主流大模型相媲美。其中,Qwen3-4B模型凭借极低的参数量,在基准测试中与GPT-4o(2024-11-20版本)展开激烈对决,彰显了阿里在推理效率上的提升并未牺牲能力。其轻量化模型Qwen3-30B-A3B和32B在多项任务中也表现出色。
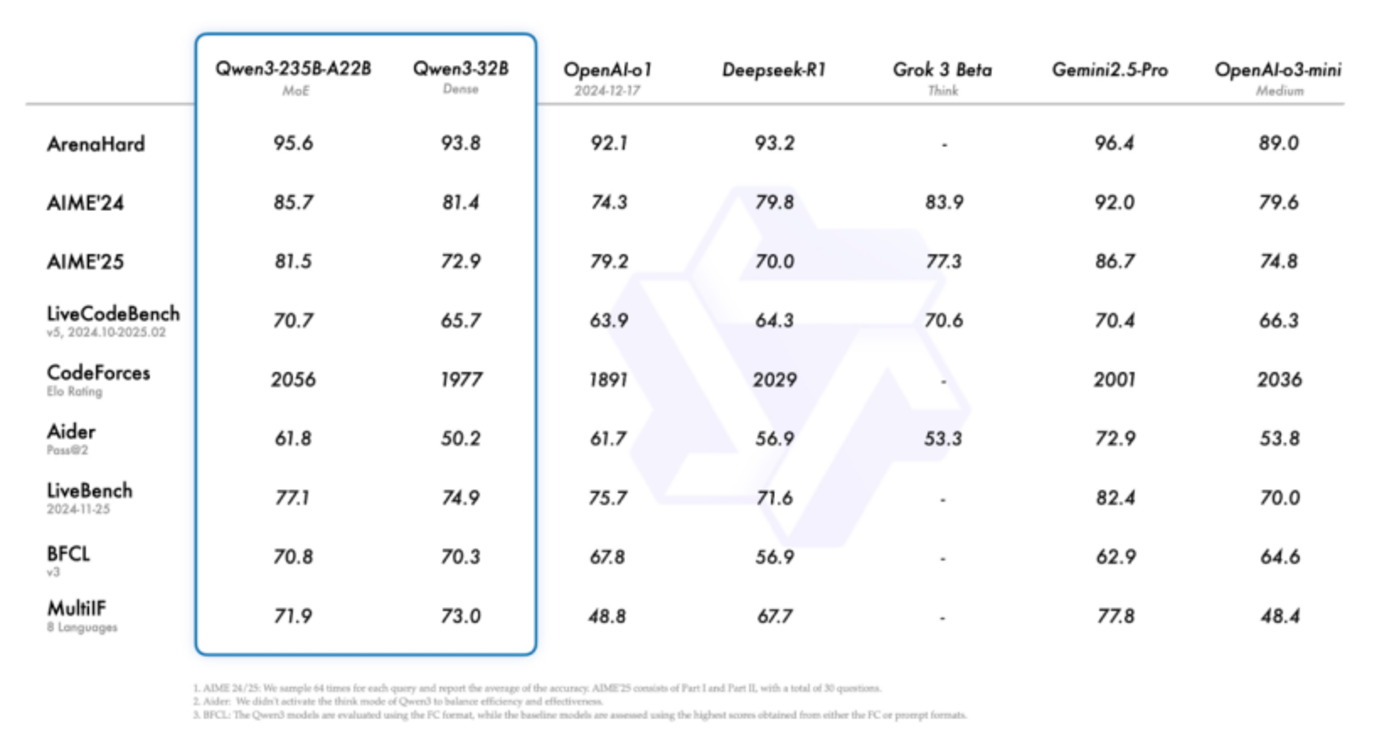
混合思考模式:按需分配算力,兼顾深度与速度
Qwen3系列的另一大创新是混合思考模式。用户可根据任务难度控制模型的推理量:在思考模式下,模型逐步推理,适合复杂问题;在无思考模式下,模型快速响应,适合简单问题。这种设计使Qwen3在处理难问题时能投入更多推理资源,而在简单问题中优先保证速度。此外,Qwen3已支持119种语言和方言,在国际应用端获得各国网友的高度评价,横向对比显示其已追上或超越OpenAI o1、谷歌Gemini 2.5 Pro。
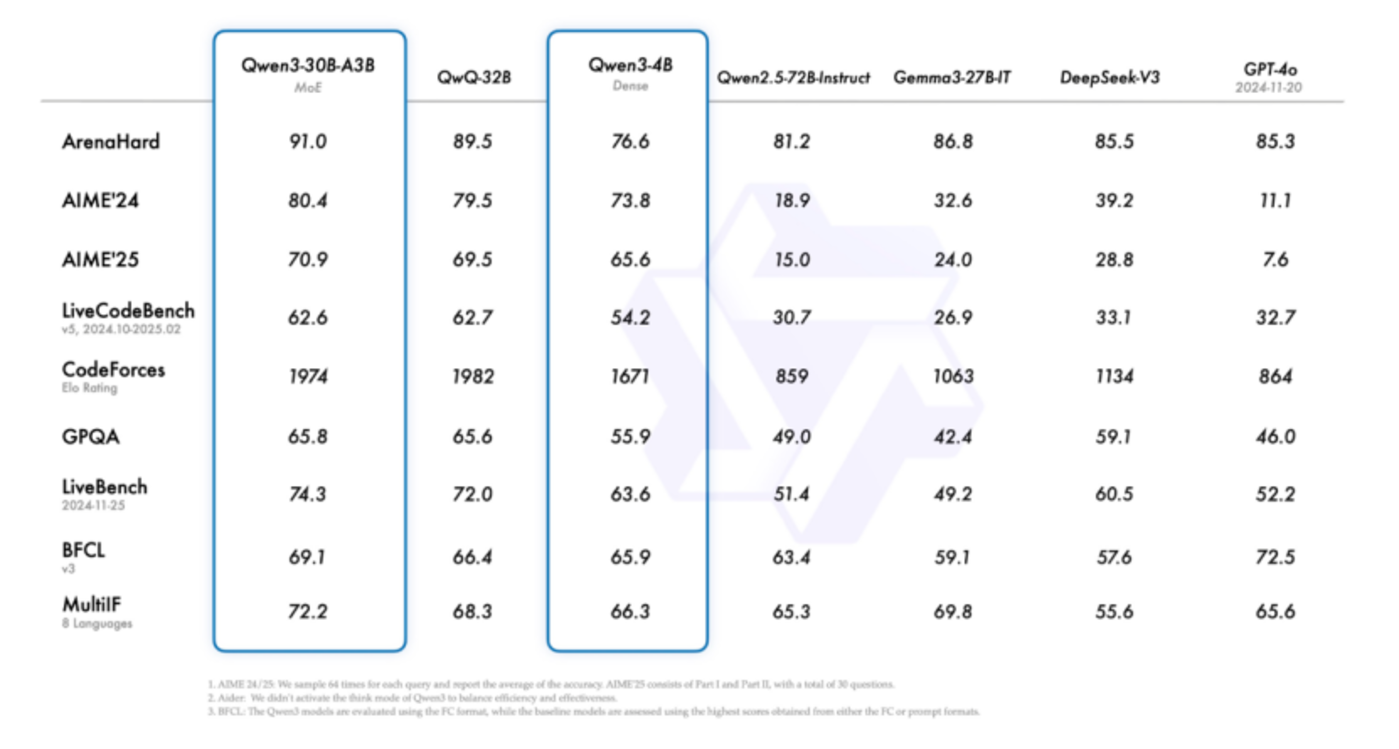
针对“AI智能体”概念的优化
Qwen3系列针对近期火爆的“AI智能体”概念进行了优化,强化了模型的编码和代理能力,并增强了对MCP的支持,使Qwen3能够学会思考及与环境交互。在预训练方面,Qwen3的数据集规模相比Qwen2.5几乎翻倍,达到3.6万亿个token,覆盖更广泛的领域知识和语境,进一步提升了在复杂任务处理和多语言场景中的表现。
统一采用Apache 2.0开源协议,构建“Qwen宇宙”
Qwen3系列全面采用Apache 2.0开源协议开放权重,通过“小杯-中杯-大杯-超大杯”的产品逻辑构建完整的“Qwen宇宙”。综合来看,Qwen3在技术性能、成本价格、工具调用和MCP调用等所有方面均实现全面提升,将开源世界的标准提升至新高度。
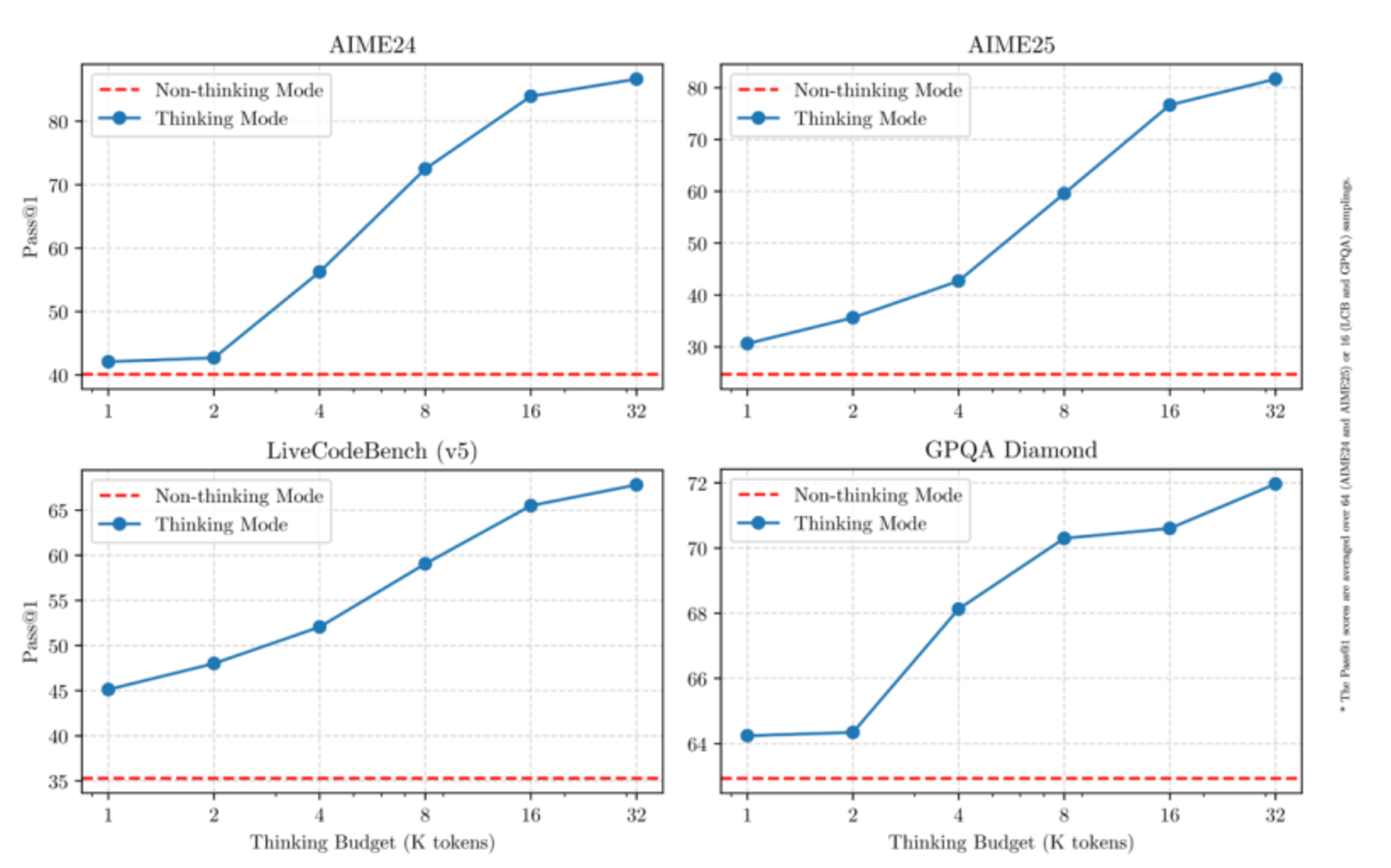
DeepSeek光环下的大厂竞争格局
4月25日,2025百度AI开发者大会上,百度创始人李彦宏公开批评DeepSeek“只能处理单一文本,无法理解声音、图片、视频等多模态内容”,并指出其“慢且贵”。他强调,中国市场上大模型API价格普遍更低,响应速度更快。这一言论揭示了DeepSeek光环下,国内大厂正以性价比抗衡其现状:用更小参数、更低成本的方式实现更快响应,并拓展多模态能力。
阿里Qwen3的差异化竞争策略
阿里的Qwen3迅速引入MoE架构和双模式推理设计,大幅降低庞大模型的实际使用成本。以Qwen3-235B-A22B为例,尽管总参数达235B,但每个token仅需计算约9%(22B)的参数,推理延迟远低于参数规模所暗示的高度。此外,双模式推理设计高效分配算力:在“非思考模式”下直接生成答案,实现即时响应;在“思考模式”下才投入额外计算资源进行多步推理。这种按需分配策略,使模型在简单交互中保持快速,在复杂问题中发挥深度推理能力,与腾讯的双轨思路异曲同工。
腾讯的混元模型:双轨策略应对不同需求
2025年2月13日,腾讯元宝接入DeepSeek R1满血版后,迅速上线“强推理深度思考模型”混元T1,并推出Turbo S模型,号称响应速度比DeepSeek R1更快。Turbo模型针对日常对话优化,弱化长链推理而追求即时回答。腾讯AI助手“元宝”集成了Turbo快思考和T1深思考两种模型,用户可根据需求选择。这种双轨策略与阿里Qwen3的单模型双模式设计,均是为不同复杂度问题提供差异化解决方案,兼顾效果与速度。
百度的战略转向:开源与多模态突围
DeepSeek R1上线后频发的幻觉现象,成为各大厂商的攻坚对象。百度经历了从闭源到开源的战略转折:在DeepSeek冲击下,宣布全面免费开源,并于2025年3月16日发布文心大模型4.5。文心4.5被定义为百度首个“原生多模态”大模型,具备图像、文本、音频等多模态联合理解与生成能力,引入深度思考能力并集成百度自研的iRAG检索增强技术,显著降低幻觉率。在价格方面,文心4.5Turbo价格下降80%,每百万token输入输出成本仅为DeepSeek V3的40%,彻底打破DeepSeek的成本优势。
字节跳动的多模态战略:淡化参数,聚焦落地
字节跳动为应对DeepSeek竞争,将重心放在多模态模型上。从2024年5月火山引擎团队首次介绍“豆包”大模型家族(9个模型)开始,字节刻意淡化参数规模与榜单,转而突出实际落地效果和低使用门槛。本月中旬,豆包1.5深度思考模型上线,在数学推理、编程竞赛等专业领域超越DeepSeek R1,最大亮点是Doubao-1.5-thinking-pro-vision具备视觉推理能力,同时豆包文生图模型3.0版本进一步丰富多模态生态。字节跳动的多模态战略,源于其敏锐洞察到大模型从技术概念转向产品概念的路径。单纯追求参数规模已不足以构建护城河,字节凭借“互联网基因”和大模型全面开花,以极低价格和广泛产品植入赢得规模和数据。
开源生态的长短期利益结合
随着DeepSeek、Llama、Qwen、智谱等厂商在开源生态上的持续投入,开源已成为主流路线。过去大厂倾向于闭源谋利,而如今开源被证明是赢得生态和快速迭代的有效途径。阿里全面开源千问印证了“模型开源是AI时代的主题”。国内大模型正进入比拼综合实力和效率的时代,不再以参数和单点性能论英雄。Qwen3、DeepSeek及腾讯、百度、字节等厂商的模型迭代实践,折射出对更高性价比的追求——既要性能好,又要成本低、应用广。AI的下半场已到来。OpenAI研究员姚顺雨曾发文指出,AI将转向定义问题,从业者需更接近产品经理水平。
阿里云CTO周靖人强调,开源大模型能加速普及、推动产业快速发展,并成为创新的重要驱动力。未来国内大模型的落地方向将更贴近实际应用,参数效率和推理成本将成为激烈竞争的焦点。
相关推荐
-
DeepSeek与颜文字:大模型圈新格局解析
这两天的大模型领域可谓是风起云涌,一边是DeepSeek凭借其低成本高性能的表现惊艳四座,引得无数技术大牛点赞;另一边社交媒体和技术论坛上却掀起了一股奇特的”颜文字&#…
-
美的磁悬浮离心机技术引领国产突破卡脖子领域
美的集团近日发布的2025年第一季度财报彰显出强劲的增长势头,营业总收入高达1284亿元,同比增长20.6%;净利润达到127.5亿元,同比增长41.1%;归母净利润为124亿元,…
-
大模型隐私危机:7款主流产品数据安全形同虚设
在人工智能蓬勃发展的时代,用户输入的信息不再仅仅是个人隐私的范畴,更成为了推动大模型进步的重要资源。无论是“帮我制作一份PPT”、“帮我设计一版新春海报”,还是“帮我总结一下文档内…
-
Submagic3个月流量暴涨10倍至千万 AI视频编辑工具如何突围
在10月AI产品榜全球访问量Top100榜单中,一款名为Submagic的视频编辑产品异军突起,位列第56名,本月访问量高达1262万,环比增幅惊人,达到119.87%。在AI榜单…
-
3月AI市场:双端下载2.6亿 腾讯阿里字节上演买量三国杀
3月份,DeepSeek的热潮虽已逐渐退去,但其影响仍在持续发酵。各大AI厂商纷纷在深度思考模型上加大投入,应用端也同步加大了市场推广力度。尤其是腾讯、字节、阿里这三家互联网巨头旗…
-
2025年AI浪潮下的大机遇与挑战
2025 年已迈入视野,AI 赛道的竞争却并未因时间流逝而减缓。技术突破的步伐非但没有遭遇瓶颈,反而呈现出加速态势。年初文生视频技术 Sora 的横空出世,以及慢思考 O1 的问世…
-
AI假孙子骗局揭秘老年人为何深陷其中
近期AI假视频频频引发热议,其中一些AI生成的“假孙子”视频更是让众多老年人深陷其中,场面既荒诞又令人啼笑皆非。视频中,纸尿裤里的婴儿独自下地摘茄子,洗净后竟还能抄起菜刀为全家备齐…
-
Gemini 2.5弯道超车揭秘:AI强化学习如何引领大模型新突破
Gemini 2.5 Pro的崛起:谷歌大模型的底层逻辑与竞争优势 谷歌最新发布的Gemini 2.5 Pro在各项评测中表现卓越,成为当前大模型领域的佼佼者。硅谷101创始人泓君…
-
SEO衰退GEO兴起谁在重塑流量分配规则
谷歌的核心业务——搜索引擎正面临AI技术带来的重大挑战。埃隆·马斯克提出的”AI将取代搜索”的观点正获得越来越多行业认同。这一转变正在深刻影响整个数字营销生…
-
英特尔营收下滑陈立武称成败攸关将裁员重组
英特尔Logo(图片来源:林志佳拍摄)4月25日消息,据WpBull.comAGI获悉,全球芯片巨头英特尔(Intel,NASDAQ: INTC)于今日凌晨正式发布2025财年第一…