英伟达GB300AI芯片性能暴涨150% 捍卫算力霸主地位
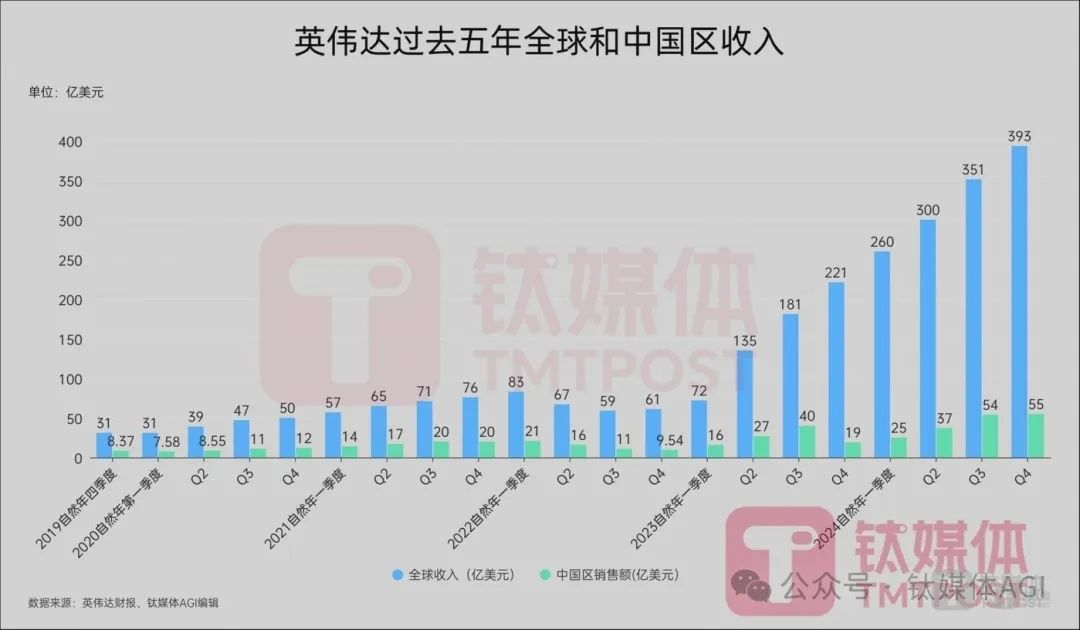
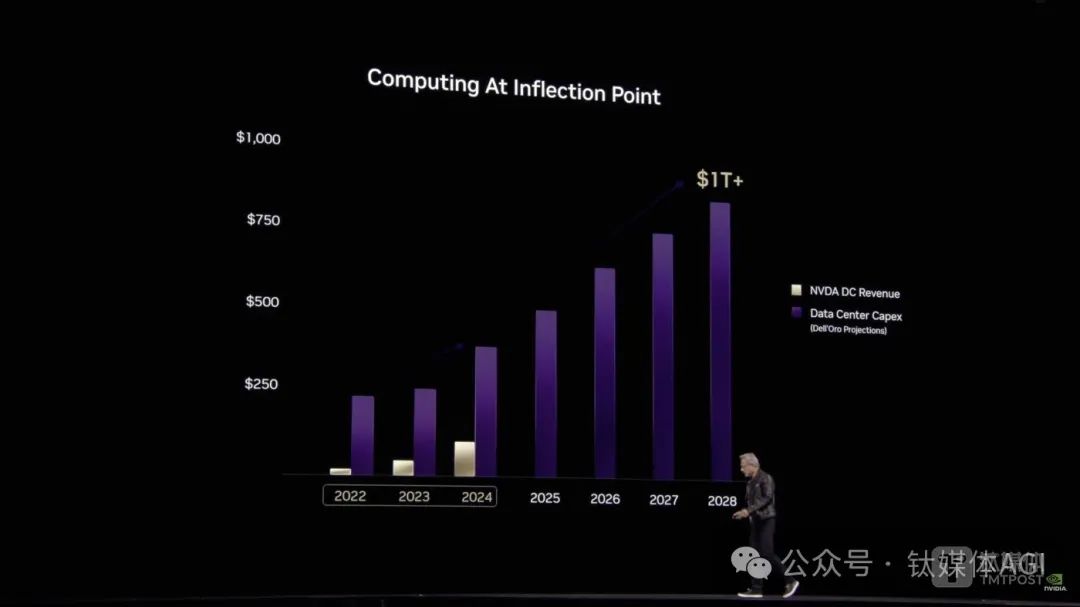
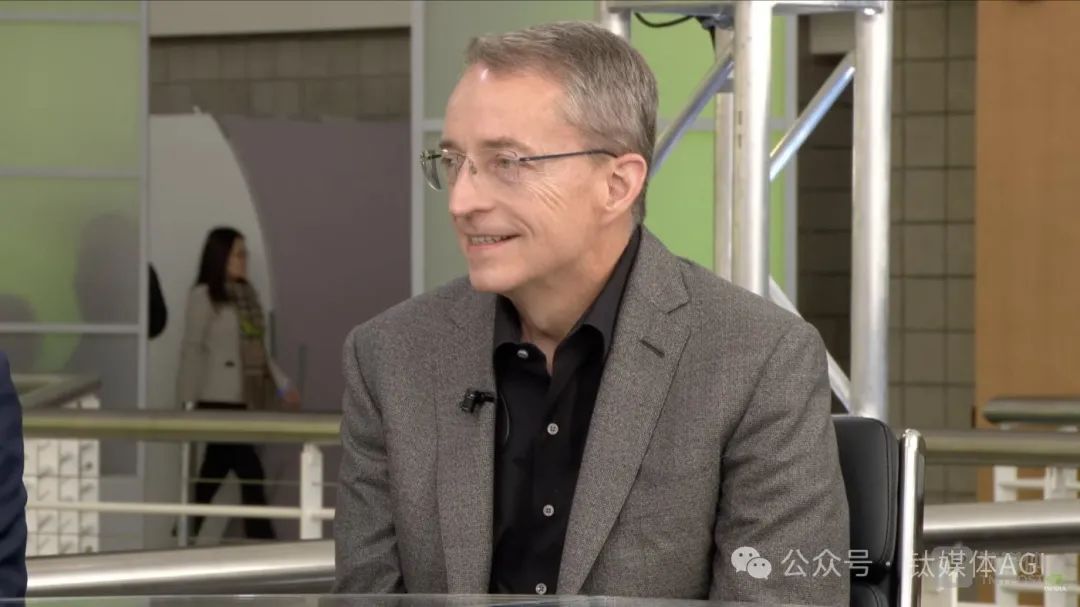
英伟达创始人兼CEO黄仁勋再度引领AI芯片等新品风暴。北京时间3月19日凌晨,在备受瞩目的“AI超级碗”GTC大会上,黄仁勋向全球隆重推出最强AI芯片GB300、个人AI超级计算机DGX Spark,并预告了新一代芯片Vera Rubin等重磅新品。GB300基于全新Blackwell Ultra架构,相较于去年发布的GB200,性能提升高达1.5倍,新的注意力机制(New Attention instructions)性能提升2倍,配备20TB HBM高带宽存储,性能提升1.5倍,预计将于今年下半年正式出货。英伟达表示,基于GB300的GB300 NVL72机架级解决方案的AI性能比GB200 NVL72高出1.5倍,与使用Hopper构建的工厂相比,Blackwell的AI工厂收入机会将增加50倍。此外,NVIDIA HGX B300 NVL16在大型语言模型上的推理速度提升11倍,计算能力提升7倍,内存增加4倍,为AI推理等复杂工作负载提供突破性性能。首批支持Blackwell Ultra服务器的厂商包括思科、戴尔、联想、超微电脑、华硕、富士康等,而AWS、谷歌云、微软云、甲骨文云等云厂商也将首批提供Blackwell Ultra支持实例。Vera Rubin作为CPU,与Grace Blackwell(GB)类似,但整体性能是GB300的3.3倍,CPU内存容量是Grace的4.2倍,内存带宽是Grace的2.4倍,预计将于2026年下半年量产出货;此外,黄仁勋还预览了下一代AI超级芯片Rubin Ultra,其内存带宽是前代的8倍,性能是GB300的14倍;Rubin下一代GPU架构则是Feynman。黄仁勋表示:“AI已经取得了巨大的飞跃——推理和Agentic AI需要更高数量的计算性能。我们为这一刻设计了Blackwell Ultra——它是一个单一的多功能平台,可以轻松高效地进行预训练、后训练和推理AI能力。”据黄仁勋透露,今年微软、谷歌、亚马逊和Meta四家大型云服务商已购入360万颗Blackwell芯片,预计2028年数据中心资本支出规模将突破1万亿美元。这场演讲对华尔街而言,也是黄仁勋的“股价保卫战”。尽管中国开源AI模型DeepSeek风靡全球,黄仁勋坦言当前AI模型所需的算力是此前模型的100倍,但资本市场质疑AI算力需求减弱,英伟达年内股价已下跌超10%。随着下一代Rubin Ultra架构最强AI芯片的揭晓,虽然英伟达股价未能重回巅峰,但CNBC表示黄仁勋已推动英伟达从数据中心转型,预测未来几年英伟达将在AI革命中发挥关键作用。黄仁勋强调:“我们现在必须以10倍的速度计算,我们要做的计算量要是当前的十倍、一百倍。”10年间,AI从感知和计算机视觉发展到生成式AI,如今又发展到具有推理能力的Agentic AI。AI理解上下文,理解我们在问什么,现在它生成的答案,从根本上改变了计算的方式,而大规模推理是一种极限计算。黄仁勋指出,下一波AI浪潮已经到来:机器人技术。四大业务重新组合,个人超算每秒运算1000万亿次英伟da主要有四个营收来源:数据中心、游戏、专业可视化、汽车,后两者目前占比较小,营收主要依赖于数据中心业务和游戏业务。因此,GTC大会上,黄仁勋演讲围绕五个板块——RTX消费级显卡、汽车、GB系列数据中心AI芯片、CUDA和可视化等软件、以及机器人技术。首先是消费级显卡,黄仁勋表示基于BlackWell架构的RTX5090已售罄,与4090相比,体积小了30%,能量消耗提高30%,性能令人惊叹,AI的进步给计算机图形带来了革命性变化。英伟达推出新一代工作站和服务器GPU RTX PRO Blackwell系列,专为复杂的AI驱动工作负载、技术计算和高性能图形设计,ChatRTX更新现已支持NVIDIA NIM,RTX Remix推出测试版。英伟da强调,RTX PRO 6000 Blackwell是医疗保健、制造业、零售业、直播等行业的AI和视觉计算工作负载的终极通用GPU。此外,今年1月CES上发布的全球最小个人AI超级计算机Project Digits,如今被命名为DGX Spark,大小与Mac Mini4相当,内置GB10芯片,提供每秒1000万亿次的AI运算,用于微调和推理最新AI模型,采用NVLink-C2C互连技术,内存带宽是第五代PCIe的5倍,售价3000美元。其次是汽车,英伟da推出NVIDIA Halos,适用于自动驾驶汽车的全栈综合安全系统,将英伟da的汽车硬件和软件安全解决方案系列与其在自动驾驶安全领域的尖端AI研究结合,加速自动驾驶汽车发展。英伟da还宣布与通用汽车合作开发AI,助力下一代汽车体验和制造。再次是GTC大会重头戏——数据中心AI芯片,英伟da发布了一系列计算、通讯和高带宽产品。黄仁勋表示,超大规模数据中心能够解决巨大规模的问题,但英伟da的目标是“扩大规模”,建造AI超级芯片。他直言,在计算机科学和工厂中,延迟、响应、时间和吞吐量之间存在根本的紧张关系,世界需要一个伟大的超级电脑。会上,英伟da发布了支持AI推理的NVIDIA Blackwell Ultra、NVIDIA横向扩展基础设施,以及英伟da软件创新等。NVIDIA GB300 NVL72采用机架级设计,连接72个Blackwell Ultra GPU和36个基于Arm Neoverse的NVIDIA Grace CPU,充当专为测试时间扩展而构建的单个大型GPU。借助其设施,AI模型可以访问平台增强的计算能力,探索问题的不同解决方案,并将复杂请求分解为多个步骤,从而获得更高质量的响应。此外,Blackwell Ultra平台还适用于Agentic AI和Physical AI。网络和通讯层面,英伟da首次推出Spectrum-X Photonics,同封装光学网络交换机,将AI工厂扩展至数百万个GPU,每端口1.6兆兆位/秒交换机,称其光子交换机是世界上最先进的网络解决方案。与传统方法相比,它们将光学创新与4倍更少的激光器相结合,实现3.5倍的能效、63倍的信号完整性、10倍的大规模网络弹性和1.3倍的部署速度。同时,英伟da称,借助GB200和GH200架构的NVLink-CNC互连,可以在单个GPU上扩展内存和应用,使用NVIDIA Warp加速数据生成和空间计算应用框架,Autodesk使用八个GH200节点执行了多达480亿个单元的模拟,比使用八个H100节点进行的模拟大5倍以上。此外,英伟da宣布Blackwell Ultra与NVIDIA Spectrum-X以太网和NVIDIA Quantum-X800 InfiniBand平台无缝集成,通过ConnectX-8 SuperNIC为系统中的每个GPU提供800 Gb/s的数据吞吐量。而DPU方面,拥有英伟daBlueField-3 DPU的Blackwell Ultra系统,可支持多租户网络、GPU计算弹性、加速数据访问和实时网络安全威胁检测。英伟da强调,先进的横向扩展网络是AI基础设施的关键组成部分,可提供最佳性能,同时减少延迟和抖动。软件创新上,整个Blackwell产品组合均由全栈英伟daAI平台支持。今天推出的NVIDIA Dynamo开源推理框架,扩展了推理AI服务,实现了吞吐量的飞跃,同时缩短了响应时间和模型服务成本;同时,NVIDIA Dynamo是一款新型AI推理服务软件,旨在为部署推理AI模型的AI工厂最大限度地提高token收入,确保最大程度地利用GPU资源。此外,NVIDIA AI Enterprise包括NVIDIA NIM微服务,以及企业可以在NVIDIA加速云、数据中心和工作站上部署的AI框架、库和工具。英伟da强调,Blackwell平台建立在英伟da强大的开发工具生态系统、NVIDIA CUDA-X库、超过600万开发人员和4000多个应用之上,可在数千个GPU上扩展性能。事实上,英伟da全场都在谈及软件对GPU和AI计算的影响。比如,利用NVIDIA cuDSS加速工程求解器,用于解决涉及稀疏矩阵的大型工程模拟问题,适用于设计优化、电磁模拟工作流程等应用,利用Grace CPU内存和超级芯片架构,使用相同的GPU和cuDSS混合内存,可将最繁重的解决方案步骤加速高达4倍,从而进一步提高效率。模型层面,英伟da宣布,经过英伟da后期训练,全新开源Llama Nemotron推理模型为Agentic AI提供业务基础,使模型的准确率较基础模型提升高达20%,推理速度较其他领先的开放推理模型提升5倍,埃森哲、德勤、微软、SAP和ServiceNow与英伟da合作开发推理AI代理,以改变工作方式。此外,英伟da还宣布与Alphabet和Google就Agentic和Physical AI的未来展开合作。最后是机器人。英伟da宣布,全球首个开放式人形机器人基础模型Isaac GR00T N1,以及加速机器人开发的仿真框架。GR00T N1基础模型采用双系统架构,灵感来自人类认知原理,“系统1”是一种快速思考的行动模型,反映了人类的反应或直觉。“系统2”是一种慢速思考的模型,用于深思熟虑、有条不紊的决策。而在视觉语言模型的支持下,系统2可以推理其环境和收到的指令,从而规划行动。然后,系统1将这些计划转化为精确、连续的机器人动作,并接受人类演示数据和NVIDIA Omniverse平台生成的大量合成数据的训练,因此,GR00T N1可以轻松实现常见任务,例如抓取、用一只或两只手臂移动物体以及将物品从一只手臂转移到另一只手臂,或者执行需要长时间上下文和一般技能组合的多步骤任务。这些功能可应用于物料搬运、包装和检查等用例。目前,GR00T N1已经上市,是英伟da将预先训练并发布给全球机器人开发人员的一系列完全可定制模型中的第一个,加速了全球劳动力短缺(估计超过5000万人)所带来的行业转型。此外,英伟da对NVIDIA GR00T N1训练数据和任务评估场景已经开源。而用于合成操作运动生成的NVIDIA Isaac GR00T蓝图现在也可以下载,而英伟daDGX Spark个人AI超级计算机为开发人员提供了一个相关系统,无须大量定制编程即可扩展GR00T N1的功能,以适应新的机器人、任务和环境。最后的最后,黄仁勋在谢幕之前成功“召唤”出了配有GR00T N1模型的机器人——Blue(星球大战机器人)。黄仁勋表示,“通用机器人时代已经到来。借助NVIDIA Isaac GR00T N1以及新的数据生成和机器人学习框架,世界各地的机器人开发人员将开拓AI时代的下一个前沿。”此外,英伟da还宣布与Google DeepMind和迪士尼研究中心合作开发Newton,这是一个开源物理引擎,可让机器人学习如何更精确地处理复杂任务。总结这场演讲,黄仁勋提及最多的几个关键词:tokens、推理和Agentic AI。在他看来,未来AI需要更多的tokens和推理能力,算力需求也会攀升,进一步加速Agentic AI和Physical AI发展,使得AI从虚拟世界转向物理世界。黄仁勋表示,BlackWell正在全力生产,客户需求令人难以置信,因为AI出现一个拐点,作为推理的结果,AI计算量要大得多,AI和推理训练,AI系统和代理AI系统;第二,Blackwell、Vera Rubin与Dynamo性能不断提升,用于计算和推理的AI工厂将成为未来十年最重要的工作负载之一。市场对英伟daGPU供不应求,但算力“霸主”难持续尽管ChatGPT热潮至今已有两年多,但全球对于AI算力需求依旧不减。据统计,2024年,微软、谷歌、亚马逊和Meta四家大型云服务商合计资本支出高达2283亿美元,比2023年的1474亿美元增长55%。预计2025年,四家大型云服务商资本支出总额将超过3200亿美元,增长超40%。黄仁勋透露,四大云厂商今年已采购360万个Blackwell芯片,预计2028年数据中心资本支出规模将突破1万亿美元。“回看历史,半导体大爆发,第一个是PC,第二个爆发是手机,第三个大爆发是AI,未来半导体最少还有10-15年来消化AI需求。”群联电子董事长潘健成对钛媒体AGI表示。2025年,DeepSeek重新燃起AI大模型产业发展新热潮。Omdia最新报告显示,2023年,全球生成式AI市场规模占总AI市场的9%,达68亿美元;2024年,生成式AI市场预计增长一倍以上,达到146亿美元;预计到2029年,生成式AI市场规模占比达三分之一,约合73亿美元,五年复合增长率达38%,市场前景广阔。然而,DeepSeek在架构和算法上实现了训练推理效率提升,同时模型训练成本也大幅下降至560万美元。因此,行业普遍认为,AI推理会让英伟daGPU需求降低。今年1月,DeepSeek热潮使得投资人抛售英伟da股票,导致其市值蒸发6000亿美元。黄仁勋本人的净资产在这场暴跌中也一度缩水近20%,如今稍有回落。潘健成对钛媒体AGI表示,云端的训练GPU可能已经达到顶峰,但推理AI还没开始。意味着,市场需求已经进入GPU发展瓶颈期,英伟da算力“霸主”难以持续。2月27日英伟da发布的四季度财报显示,英伟daQ4营收393.31亿美元,同比增长78%;调整后毛利率为73.5%,同比下降3.2个百分点;公认会计准则下,季度净利润220.91亿美元,同比增长80%,环比增长14%,非GAAP下调整后同比增长72%,均低于分析师预期。整个2025财年,英伟da营收首次突破1000亿美元,达1305亿美元,较上年同期增长114%;非公认会计准则下,净利润达742.65亿美元,较上年同期增长130%;毛利率75.5%,同比上涨1.7个百分点,调整后EPS2.99美元。其中,去年全年,英伟da中国区营收171.08亿美元,为史上最高,比前一年103.06亿美元增长66%。英伟da现在的营收中,大约有53%是在美国之外。黄仁勋表示,AI芯片Blackwell的需求惊人,目前公司已成功实现Blackwell AI超级计算机的大规模生产,第一季度的销售额就达到数十亿美元。预计Blackwell Ultra将于2025年下半年发布,一旦Blackwell完成增产,利润将改善,重申利润率到2025年年底为“70%-80%区间中部”。黄仁勋今天提供了数据中心和英伟da AI芯片的份额。Dell Oro预测,到2028年,全球数据中心资本支出高达1万亿美元以上,而英伟da数据中心收入将在其中发挥关键作用。很显然,黄仁勋非常有信心在数据中心方面取得更大进展。“推理带来的潜在需求让人感到兴奋。这将要求比大语言模型更多的计算。这可能会要求比当前多出(至少)数百万倍的计算。”黄仁勋强调,AI行业正以光速发展。下一波浪潮即将到来,企业的agentic AI,机器人的Physical AI),以及不同地区为自己的生态系统构建主权AI,每一个都刚刚离开地面。“很明显,我们处于这一发展的中心。”长期来看,英伟da希望构建一座基于计算基础设施的AI工厂。与传统数据中心不同,AI工厂不仅存储和处理数据,它们以规模制造智能,将原始数据转化为实时洞察。对于全球的企业和国家来说,这意味着价值实现时间将大大缩短,将AI从长期投资转变为立即推动竞争优势的动力,今天投资于专门设计的AI工厂的公司将在明天的创新、效率和市场竞争中领先。黄仁勋称,智能不是副产品,而是核心。这种智能通过AI Token吞吐量来衡量——即驱动决策、自动化以及全新服务的实时预测。AI工厂则优化于从AI中创造价值,它们协调整个AI生命周期,包括从数据摄取到训练、微调和最关键的高量推理。当然,黄仁勋的目的很简单:多买英伟daGPU,尽管性能很难快速提升但可以多买芯片实现庞大计算规模,AI需要的大量算力都可以在英伟da平台计算,计算、通信、模型、工具、软件平台通通都有,英伟da能得到收入,各国能得到AI最强国地位。此外,黄仁勋再次更新了“黄氏定律”,他认为,推理已成为AI经济的主要驱动力,因此Scaling Law有三个层面:预训练扩展:更大的数据集和模型参数可带来可预测的智能增益,但要达到这一阶段需要对熟练的专家、数据管理和计算资源进行大量投资。在过去五年中,预训练扩展使计算需求增加了5000万倍。但是,一旦模型经过训练,其他人在其基础上进行构建的门槛就会大大降低。训练后扩展:针对特定实际应用对AI模型进行微调,在AI推理过程中所需的计算量是预训练的30倍。随着组织根据其独特需求调整现有模型,对AI基础设施的累计需求猛增。测试时间扩展(又称长期思考):代理AI或物理AI等高级AI应用需要迭代推理,其中模型会探索多种可能的响应,然后再选择最佳响应。这比传统推理消耗的计算量最多高出100倍。所以,黄仁勋如此努力,连前英特尔CEO基辛格(Pat Gelsinger)都来现场夸奖老黄,成为黄仁勋最新拥趸者。基辛格表示,英伟da团队对AI做出了巨大贡献。据悉,如今“退休”的基辛格,创立了教会通讯平台Gloo,他担任董事长,并将大模型作为其聊天机器人的基石,当然,他们也买了英伟da的算力。基辛格还谈到量子计算,认为其发展对于通用AI至关重要。基辛格称,不太同意老黄的一点是,他认为量子计算将在这个十年结束之前以可实现的形式出现,即未来5年内人类将在生产中使用可实现的量子计算机。“绝对的,未来数据中心有部分工作负载、数据处理等,会有训练工作量,因此,我们会有量子计算处理器,如果你想想量子,人类的大部分,人类最有趣的事情就是量子效应。有一个计算模型来研究这些事情是非常合适的。就像GPU看起来更像是大脑,用于训练、人类和语言以及所有这些东西,所以我坚信这就是未来的数据中心。”基辛格表示。因此,今年GTC大会,除了黄仁勋的主题演讲,还有一件事最值得期待:首次设立“量子日”活动。届时,黄仁勋将与D-Wave Quantum和Rigetti Computing等十余家量子计算行业领军企业的高管同台,讨论量子计算的技术现状、潜力以及未来发展方向。今天,英伟da已经宣布在波士顿建立一个量子研究中心 (NVAQC) ,以提供推动量子计算发展的尖端技术,把领先的量子硬件与AI超级计算机集成在一起,实现所谓的加速量子超级计算,帮助解决量子计算最具挑战性的问题,从量子比特噪声到将实验性量子处理器转变为实用设备。该研究院包括Quantinuum、Quantum Machines 和QuEra Computing,以及哈佛大学科学与工程量子计划 (HQI) 和麻省理工学院 (MIT) 的工程量子系统 (EQuS) 小组等。“NVAQC是一个强大的工具,将有助于引领整个量子生态系统的下一代研究,”麻省理工学院电子工程与计算机科学教授、物理学教授、EQuS小组负责人兼量子工程中心主任William Oliver表示。“NVIDIA是实现实用量子计算的重要合作伙伴。”黄仁勋则强调,量子计算将增强AI超级计算机的能力,以解决从药物发现到材料开发等世界上一些最重要的问题。英伟da加速量子研究中心将与更广泛的量子研究界合作,推动CUDA-量子混合计算的发展,并取得突破,打造出大规模、实用、加速的量子超级计算机。很显然,下一个AI计算未来,黄仁勋也想全面布局,推动英伟da成为AI算力领域的持续性“霸主”。








相关推荐
-
大模型幻觉陷阱:AI编织的美丽谎言如何影响互联网
当DeepSeek以惊人的速度攀升至日下载量500万、DAU逼近ChatGPT的23%之际,大模型正以前所未有的速度走进普通人的生活。然而,在这场AI与人类的密切接触中,我们遇到了…
-
腾讯AI视频生成对决Sora同提示词效果测评
腾讯版Sora迎来重大进展,相关视频生成模型与产品正经历紧张的升级与调试阶段。虽然正式上线时间尚未确定,但幸运的内测用户已率先体验其强大功能,让我们抢先一探究竟。 作为腾讯首款文生…
-
宇树机器人春晚爆红后商业价值飙升成顶流广告主角
当宇树机器人在春晚身着大花棉袄扭秧歌时,或许无人预料到这个看似抽象的表演嘉宾,会在接下来的两个月里成为社交媒体的顶流。在各大社交平台上,宇树机器人G1时而模仿邓超的舞蹈动作,时而展…
-
DeepSeek V3称自己为ChatGPT引热议:AI模型为何频现“报错家门”现象
要说近期大模型领域的焦点人物,DeepSeek V3无疑是当之无愧的顶流。然而在这股热潮中,一个有趣的bug也意外走红,引发了广泛关注——DeepSeek V3在自我介绍时,竟然少…
-
上海光机所突破EUV光源技术 中国芯片生产不再受制于人
中国芯片极紫外(EUV)光刻光源技术取得重大突破,成功绕过美国技术封锁,采用固体激光器技术实现LPP-EUV光源开发,达到国际领先水平。这一突破对中国自主芯片制造具有重要意义。据环…
-
潞晨科技突然停用DeepSeek API背后:成本压力下中小MaaS商的无奈选择
国内首例公开宣布弃用DeepSeek的企业浮出水面。就在DeepSeek官方公布线上系统理论成本利润率达545%的消息引发行业震动后,清华系AI Infra企业潞晨科技突然宣布暂停…
-
Grok-3语音功能上线 马斯克手把手教你建10万GPU超算中心
Grok APP迎来重大升级,全新实时语音模式现已正式上线!这款由xAI精心打造的智能应用,如今支持高达10种语音交互模式,让用户能够通过自然语言与AI进行流畅对话,甚至模拟电话式…
-
惊喜!Sam Altman确定OpenAI新产品,AGI、Agents、成人模式
Image source: Generated by AI 今天凌晨3点30,Sam Altman公布了2025年OpenAI即将发布的技术产品。 分别是:AGI(通用人工智能)、…
-
ChatGPT每月 200 美金仍在亏损,OpenAI或调整定价模式
文章来源:AI范儿 Image source: Generated by AI 在人工智能领域的激烈竞争中,即便是行业领军企业 OpenAI 也面临着严峻的经营挑战。该公司首席执行…
-
贝壳AI赋能业绩飙升:科技驱动行业新变革
(图源:贝壳,下同)近年来,人工智能技术的迅猛发展令人瞩目,从ChatGPT到DeepSeek等应用的快速迭代,充分展现了AI的强大效能与进化速度。随着AI技术逐渐渗透到各行各业,…