Science突破:AI模拟5亿年进化创造全新蛋白质
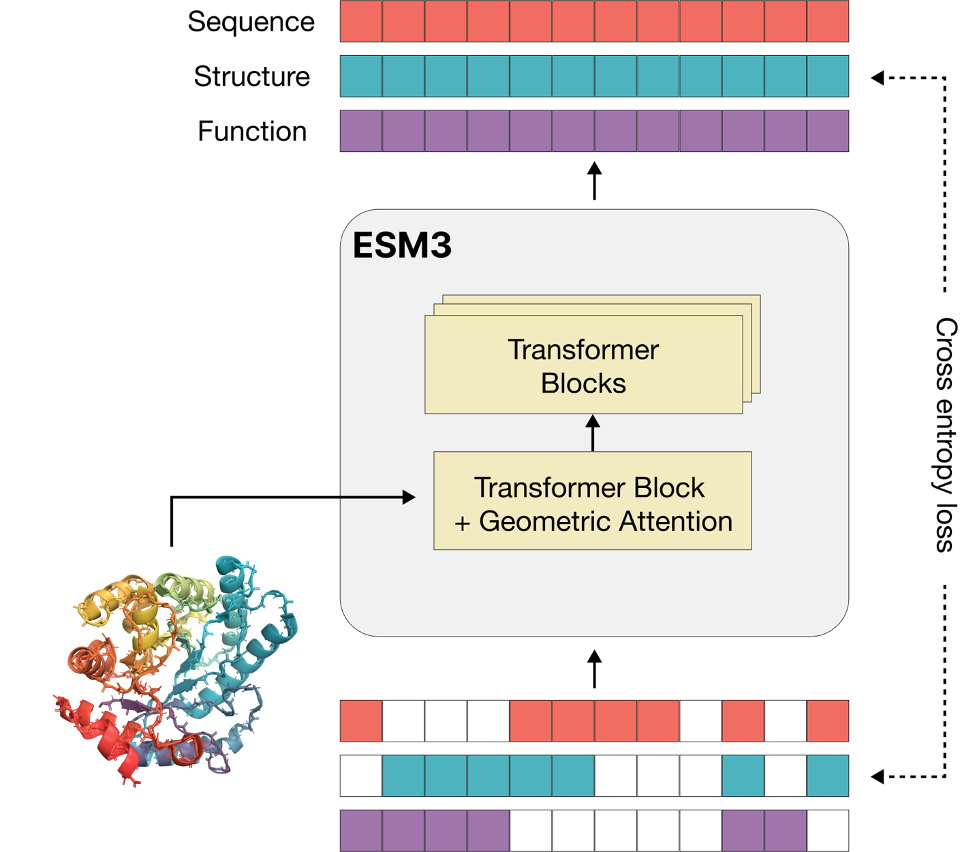
蛋白质作为生物体中至关重要的功能性分子,其形成过程历经数十亿年的自然选择与进化。在这一漫长过程中,蛋白质的序列和结构经历了无数次随机突变,并通过生物系统的选择机制进行筛选,最终演化出具有特定生物学功能的蛋白质。近年来,随着深度学习和语言模型(LM)技术的飞速发展,科学家们开始探索将这些先进工具应用于生物系统研究,尤其是对蛋白质的深入理解。近日,Science杂志发表了一项突破性研究成果,展示了如何利用语言模型生成和推理蛋白质序列、结构与功能,并正式推出名为ESM3的多模态生成式模型。该模型不仅能够高效生成功能性蛋白质,还能模拟超过5亿年的进化过程,创造出与自然界已知蛋白序列截然不同的全新蛋白质。ESM3由人工智能初创公司Evolutionary Scale研发,致力于帮助科学家们理解、构思和创造蛋白质,为生物医学研究带来革命性突破。在这项研究中,研究人员借助ESM3成功设计出一种新型绿色荧光蛋白(GFP),其基因序列与已知荧光蛋白存在巨大差异。若通过天然荧光蛋白的生物进化途径,这一突变过程需要超过5亿年的时间。这一成果有力证明,语言模型不仅能解读自然进化中积累的生物数据,还能通过深度分析生成新型生物分子,为蛋白质设计和药物开发开辟全新路径。AI解码生物语言的奥秘生物体本质上是一种可编程系统。这是因为所有生物体都共享相同的遗传密码,构成生命物质基础的蛋白质仅由20种氨基酸组成,因此有人将其比作生命的”字母表”。生物体中复杂的蛋白质信息蕴含着深层的生物学规律和演化历史。近年来,科学家们通过对基因组序列和蛋白质结构的测序,积累了海量的蛋白质数据,包括数十亿条序列和数亿个结构信息。随着AI技术的蓬勃发展,科学家们开始尝试利用深度学习模型,如大语言模型(LLM),将这些遗传信息”解码”,以揭示蛋白质序列中隐藏的深层模式和逻辑,并通过这些模式推断、设计全新的蛋白质结构和功能。目前,已有多个语言模型(如ProtBERT、ProtGPT)证实蛋白质序列中的模式能够被语言模型”解码”,从而有效帮助理解其功能。这一领域的研究还表明,随着模型规模的扩大,语言模型的能力和准确性也随之显著提升。为此,研究人员使用了超过31.5亿条蛋白质序列、2.36亿个蛋白质结构,以及5.39亿个带有功能注释的蛋白质数据来训练ESM3模型。该模型总共有三种不同的规模,分别为14亿、70亿和980亿参数。实验表明,随着模型参数规模的增加,ESM3在生成能力和表示学习上的性能有显著提升,特别是在生成蛋白质结构时,980亿参数的模型表现出超越现有模型的强大能力。作为该领域的前沿成果,ESM3不仅仅是一个传统的序列生成模型,而是一个创新的多模态生成模型,能够同时处理蛋白质的序列、三维结构和功能信息。ESM3还展示了其在多种生成任务上的卓越性能。ESM3采用了一种名为”生成掩码语言模型”的方法,在输入中对蛋白质的序列、结构和功能进行随机掩码,然后通过模型推理生成缺失的部分。(来源:Evolutionary Scale)研究人员通过随机掩码并生成序列和结构,对比生成结果与真实蛋白质的匹配情况,发现模型能够生成高质量的蛋白质序列和结构,其与真实结构的平均差异仅为0.5Å。此外,研究表明,ESM3能够通过不同的提示生成具有目标功能的蛋白质,这为蛋白质设计带来了高度灵活性。与传统的三维空间中的复杂建模方法不同,ESM3将三维结构离散化为token,这使得它能够与序列和功能信息一同被输入模型进行处理。这种方法避免了复杂的三维空间扩散架构,使得生成过程更加高效、可控。用5亿年时间进化才能诞生的荧光蛋白为了展示ESM3模型在生成全新蛋白质方面的巨大潜力,研究人员选择绿色荧光蛋白进行挑战。绿色荧光蛋白在生物学研究中扮演着至关重要的角色,常用于标记和跟踪细胞内的分子与结构。然而,现有的荧光蛋白大多来自自然界,其突变通常限制在已有序列周围,很难大幅度改变其序列。在少数情况下,借助高通量实验和机器学习,科学家仅能够引入至多40-50个突变(即80%的序列同源性),同时保留蛋白的荧光功能。(来源:Evolutionary Scale)为了突破这一瓶颈,研究人员通过对ESM3模型进行特定的功能提示,尝试生成一个全新的绿色荧光蛋白,要求该蛋白的序列与已知的绿色荧光蛋白序列相似性较低,但仍要保持其荧光特性。首先,研究人员定义了一个229个氨基酸长的蛋白质序列,其中包含了与绿色荧光蛋白荧光活性相关的关键氨基酸,研究人员还提供了绿色荧光蛋白的三维信息,尤其是与形成荧光色素的活性位点相关的氨基酸残基。ESM3模型在接收到这些提示后,会生成一个蛋白质的三维结构,尤其是确保活性位点的氨基酸位置协调良好。然后,基于生成的结构,模型进一步推理生成合适的氨基酸序列,并尝试保持活性位点的正确结构。在这个过程中,ESM3不仅仅是根据已有的绿色荧光蛋白结构生成新的序列,还能够在”已知”结构的基础上进行创新,生成具有低序列相似性的新型蛋白质。经过一系列的生成和优化步骤,研究人员获得了多个新的绿色荧光蛋白,其中一个特别的设计被命名为esmGFP。这个全新的蛋白质与现有的荧光蛋白(如tagRFP)之间的序列相似性为58%,与最接近的天然蛋白(eqFP578)之间的序列差异为107个氨基酸,序列相似性为53%。研究人员还进一步验证了生成的绿色荧光蛋白是否具有实际的荧光功能。结果表明,尽管esmGFP发光特性有所延迟,成熟时间较长,但最终的荧光亮度与已知的绿色荧光蛋白相似,且具有稳定的荧光特性。研究人员还提供了时间校准系统发育分析,指出如果通过现有蛋白的自然界进化过程得到esmGFP,则需要超过5亿年的等效时间。ESM3的未来潜力与应用ESM3的另一个显著亮点是其在多模态条件下的生成和控制能力。也就是说,研究人员能够通过提示特定的蛋白质结构、功能或特定的关键氨基酸,生成满足这些条件的新型蛋白质。例如,模型能够生成具有特定功能位点的蛋白质,同时保持整体结构的完整性。此外,通过组合不同的提示,模型也能够生成符合复杂要求的蛋白质。例如,研究人员提示蛋白质的二级结构和功能关键词,并生成了与这些提示高度一致的蛋白质。ESM3模型的这种提示响应能力和可控特性,使得它在蛋白质设计领域具有高度实用价值,尤其是在生成与现有已知蛋白质具有显著差异的新型蛋白质方面。在ESM3模型的帮助下,研究人员不仅能够设计出新型的绿色荧光蛋白,还能在设计中创新,突破自然进化的局限。这为未来蛋白质工程、合成生物学和药物开发等领域提供了新的可能性,也为蛋白质的设计和功能验证提供了更加高效的工具。例如,与自然进化相比,ESM3能够大大加速蛋白质设计的速度,并生成在自然界中无法轻易获得的新蛋白质,而这对于基础研究和应用研究来说都是巨大的突破。另外,在药物设计领域中,生成具有特定功能的蛋白质是一个重要的研究方向,而通过ESM3,研究人员能够设计出符合特定靶点的蛋白质,减少实验验证的时间和成本。而在合成生物学领域中,ESM3能够为开发新的合成途径提供帮助,生成具备新功能的酶或代谢途径。研究人员还指出,随着模型规模和数据量的进一步增加,ESM3有潜力生成更加复杂和创新的蛋白质。未来,ESM3的应用可能涵盖从基础研究到药物设计等更多领域,为蛋白质工程开辟全新的可能性。目前,ESM3已通过API推出公开测试版,使科学家能够通过编程或基于浏览器的交互式app来设计蛋白质。科学家们可以通过免费学术访问层使用EvolutionaryScale Forge API,也可以使用开放模型的代码和权重。




相关推荐
-
OpenAI推博士级AI Agent月费2万美元 面向企业高端需求
3月6日,据The Information独家报道,OpenAI正酝酿一项颠覆性的商业策略——面向企业用户推出”博士级AI Agent”订阅服务,每月收费高…
-
2025机器人产业高地争夺战:谁将领跑具身智能赛道
各大城市产业竞争的风潮率先吹向了「机器人」领域。国资力量积极布局具身智能企业,展现出对该领域的强烈关注。据「硅基研究室」不完全统计,今年机器人赛道已发生110余笔投融资事件,投资总…
-
2024年,人类开始用AI治愈自己
文章来源:听筒Tech Image source: Generated by AI 23年前,科幻影片大师斯皮尔伯格拍摄了《人工智能》,电影主角是一位由AI生成的小男孩“大卫”,他…
-
DeepSeek爆火三月,第一批赚钱者现状揭秘
如果你在2023年错过了ChatGPT,2024年又未能及时拥抱Sora,那么2025年你很可能成为DeepSeek的潜在用户,不知不觉间陷入它精心编织的数字网络中。张蕾至今仍记得…
-
奥特曼激战梁文锋 AI营销巅峰对决
“AI营销大师”奥特曼的声名正日益巩固。在被梁文锋短暂抢占风头后,奥特曼以每周推出新产品的惊人速度,强势占据AI热搜榜首。仅在过去一周内,OpenAI就接连…
-
DeepSeek赋能AI公务员上岗 提升政务效率创新应用
近日,镇江市数据局通过新闻发布会正式亮相其本地化部署的DeepSeek AI系统,相关负责人在会上透露,该系统单日可处理的数据量相当于全市公务员十年工作量总和。这一表述虽略显夸张,…
-
2025年人形机器人赛道超200亿融资 中国美国竞逐50万亿市场
中国与美国正展开激烈竞争,争夺AI与人形机器人领域的未来主导权。5月下旬,上海浦东张江的一座大型仓库内,数十台人形机器人接受人类操控,反复执行折叠T恤、制作三明治和开门等任务,每天…
-
宇树科技股改迎北京国资董事 拟IPO上市布局加速
国内备受瞩目的智能机器人领军企业宇树科技近日宣布完成股改,正式迈出IPO上市的关键一步。5月29日晚间,公司发布正式通知,因业务发展需要,杭州宇树科技有限公司将更名为”…
-
人形机器人破局工厂:体育养老新场景探索
几乎所有人形机器人厂商在展示落地应用案例时,都不约而同地将目光聚焦于工厂场景,甚至将其视为人形机器人商业化落地的”最优解”。一时间,工厂车间仿佛成为人形机器…
-
DeepSeek日入409万背后 AI大模型商业化困境与破局之路
DeepSeek大模型近期引发科技行业热议,其率先打通商业闭环的举措备受关注。2025年3月1日,DeepSeek发布技术文章披露,2月27日至28日间,平台日均GPU租赁成本达8…