万相2.1开源模型评测:中文文生视频领先Sora?
开源周的热潮仍在继续,AI领域的创新者们纷纷展现出自己的实力。2月25日这一天,Claude发布了Sonnet 3.7版本,DeepSeek开源了DeepEP代码库,而阿里的万相2.1视频生成模型也正式亮相,共同构成了科技界的一幅精彩画卷。在众多AI技术中,视频生成模型无疑是最引人注目的焦点,它不仅吸引了开发者的目光,更让普通用户对AI的创造力产生了浓厚的兴趣。


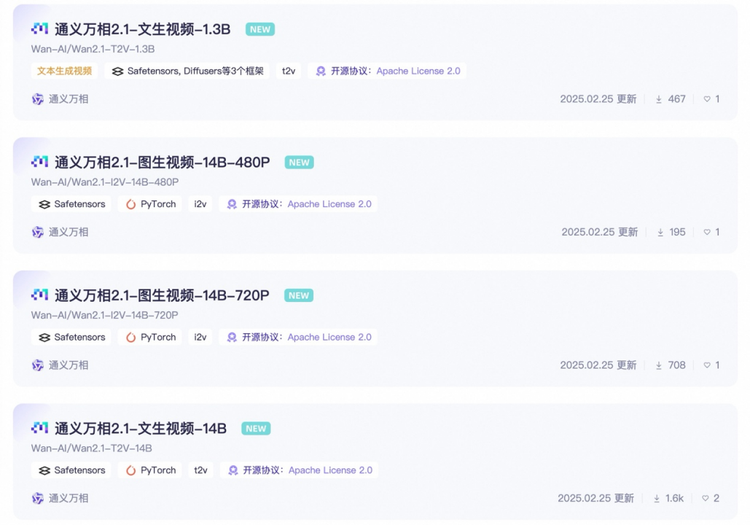
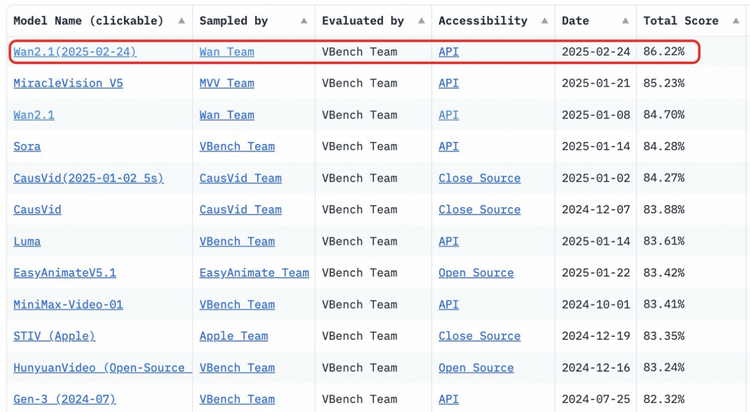
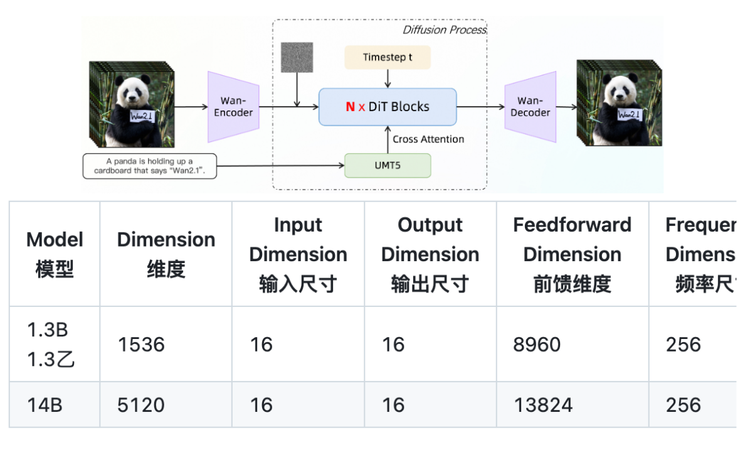
万相2.1模型秉持着”能开尽开”的理念,向全球开发者开放了14B和1.3B两个参数的全部推理代码和权重。这一举措不仅支持文生视频和图生视频任务,更采用了宽松的Apache2.0协议,确保生成内容的版权完全归开发者所有,无论是用于免费渠道还是商业用途都毫无限制。在评测集VBench中,万相2.1的表现超越了Sora、Luma、Pika等国内外开源模型,展现出强大的技术实力。
## 模型实测:效果与挑战并存
在通义万相中,我们测试了2.1极速版和专业版两个版本,它们都是基于14B参数的模型。极速版生成速度约为4分钟,而专业版则需要1小时左右,但效果更为稳定。在文生视频方面,专业版对文本理解的精确度更高,画面清晰度也相对出色。然而,两个版本生成的视频都存在明显变形,对物理世界的细节理解有所欠缺。
以”参考盗梦空间拍摄方式,俯拍广角镜头,酒店走廊以每秒15度角持续旋转,两位西装特工在墙壁与天花板间翻滚格斗,领带受离心力影响呈45度飘起”为提示词,专业版生成的视频在动作设计上表现出色,但画面变形问题依然存在。而”红裙女孩在蒙马特阶梯跳跃,每级台阶弹出旧物收藏盒(发条玩具/老照片/玻璃弹珠),暖调滤镜下鸽子群组成心形轨迹,手风琴音阶与脚步节奏精确同步,鱼眼镜头跟拍”这一提示词则展现了专业版在细节处理上的优势。

万相2.1是目前全球首个能够直接生成中文文字的开源视频模型,虽然能够准确生成短文本,但超出一定长度就会出现乱码。在图生视频方面,效果相对稳定,人物一致性较高,但提示词理解不完整,细节表现不足。例如,珍珠奶茶视频中缺少珍珠,石矶娘娘的变身效果也未达到预期。

## 技术创新:低成本、高效果、高可控

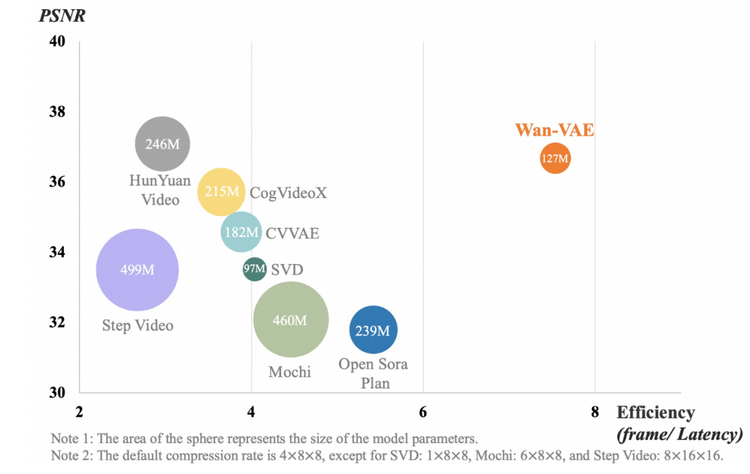
万相2.1基于主流DiT架构和线性噪声轨迹Flow Matching,采用3D时空变分自动编码器(VAE)技术,称为Wan-VAE。这一创新通过改进时空压缩,大幅减少了内存使用,类似于将三维信息压缩为二维表示,从而解决了传统扩散模型在视频生成中的计算量过大、内存消耗过高的问题。

Wan-VAE技术将视频分解为低维表示,先生成二维信息再还原三维,或采用分层生成方法提升效率。这一技术不仅降低了内存占用,还解决了长视频生产难题,使得模型能够在消费级显卡上流畅运行。传统高清视频数据量过大,普通显卡难以处理,而万相通过降低分辨率生成视频,再使用超分模型提升画质,在不损失性能的情况下进一步减少了29%的推理时内存占用。

在生成效果方面,万相2.1实现了精细化的运动控制,允许用户通过文本、关键点或简单草图控制视频中物体的运动方式。模型将用户输入的运动轨迹转化为数学模型,并引入物理引擎计算结果,以提升运动的真实性。这些技术创新不仅解决了视频生成模型的大规模应用难题,还为后续迭代留下了广阔空间。

## 开源策略:打破商业模式,降低创作门槛

万相2.1的全面开源策略彻底打破了视频模型付费的商业模式,为普通用户降低了视频创作的门槛。其核心优势在于通过工程化能力解决实际生产场景中的难题,同时通过模块化设计为后续迭代提供了可能。2025年的视频生成赛道,万相2.1的出现无疑将带来更多精彩与创新。随着技术的不断发展和完善,我们有理由期待万相2.1在未来能够呈现更加出色的效果,为AI视频生成领域开启新的篇章。
相关推荐
-
AI赋能无障碍科技,助力残障人士拥抱美好生活
《小小的我,拥抱大大的AI——科技无障碍事业的光辉篇章》 在电影《小小的我》中,刘春和的脑瘫形象引发了社会对残障人士真实处境的深刻反思。这部作品让我们欣慰地看到影视界开始正视障碍群…
-
DeepSeek开源大模型惊艳硅谷:低成本创新引领AI新潮流
DeepSeek – V3 的横空出世,在硅谷掀起了一场前所未有的 AI 革命。这款由中国杭州人工智能创业公司 DeepSeek 开发的大语言模型,以其惊人的性能和极低…
-
美国FBI突袭华裔教授住宅 引发学术界对特朗普反华政策的强烈抗议 超千科学家考虑离开美国
特朗普重返白宫后,一股强劲的“反华之风”席卷美国,其发起的对华人科研学者极具争议的“中国行动计划”正有死灰复燃之势。4月5日,据美国《印第安纳学生日报》(IDS)报道,美国联邦调查…
-
大模型隐私危机:7款主流产品数据安全形同虚设
在人工智能蓬勃发展的时代,用户输入的信息不再仅仅是个人隐私的范畴,更成为了推动大模型进步的重要资源。无论是“帮我制作一份PPT”、“帮我设计一版新春海报”,还是“帮我总结一下文档内…
-
美国芯片EDA巨头断供中国市场 将如何冲击国内产业链
经历两天传闻发酵后,两家美国芯片EDA巨头Synopsys(新思科技)与Cadence(楷登电子)正式官宣确认,美国商务部工业和安全局(BIS)要求其对中国企业断供芯片设计EDA软…
-
微软谷歌AI战略聚焦开放代理网络与Gemini操作系统
《窄播Weekly》第55期:微软与Google的AI战略交锋 本周商业动态聚焦于微软和Google在开发者大会上的AI战略布局。微软的Build 2025大会与Google的I/…
-
AI数据价值:7.5万亿产业赋能中国经济新机遇
近期,美国对华数据访问的限制措施引发全球瞩目。5月18日,美国国立卫生研究院(NIH)正式宣布禁止中国访问人类基因组、疾病研究等关键数据库及相关数据。与此同时,美国SEER、TCG…
-
DeepEP开源王炸:MoE全栈通信库引爆AI算力革命
2月25日,DeepSeek以开源姿态震撼业界,推出全球首款面向MoE模型的全栈通信库——DeepEP,为AI算力瓶颈带来革命性解决方案。GitHub平台数据飙升1500星,圈内反…
-
芯驰发布全新AI座舱芯片X10系列 智控芯片E3系列出货超800万片
WpBull.comApp 4月24日消息,备受瞩目的第二十一届上海国际汽车工业展览会(简称“2025上海车展”)于4月23日正式拉开帷幕,将持续至5月2日。在车展首日,国内汽车芯…
-
英特尔CEO陈立武上任14天首把火:剥离非核心业务聚焦AI芯片
英特尔CEO陈立武上任14天,便以一场震撼行业的变革宣告其领导力。4月1日凌晨,英特尔(Intel)CEO陈立武(Lip-Bu Tan)在Intel Vision活动上发表了一场长…