微软开源phi-4小模型 超越GPT-4o 商业化许可
微软研究院今凌晨震撼发布全新开源模型phi-4,正式揭开其作为目前最强小参数模型的神秘面纱。这款仅含140亿参数的phi-4,自去年12月12日首次亮相以来便备受瞩目,其卓越性能在多个权威基准测试中脱颖而出,不仅超越了OpenAI的GPT-4o,更在顶级开源模型Qwen 2.5 -14B和Llama-3.3-70B之上实现了碾压式胜利。在美国数学竞赛AMC的测试中,phi-4更是以惊人的91.8分遥遥领先,不仅击败了Gemini Pro 1.5、GPT-4o、Claude 3.5 Sonnet、Qwen 2.5等知名开闭源模型,其整体性能甚至可与4050亿参数的Llama-3.1相媲美。这一突破性成果终于迎来开源时刻,phi-4全面支持MIT许可证下的商业用途,为全球开发者带来前所未有的机遇。开源地址:https://huggingface.co/microsoft/phi-4/tree/main


HuggingFace官方团队对此盛况纷纷祝贺,官推盛赞phi-4是”有史以来最好的14B模型”,并期待其在Azure上实现无服务器功能。众多开发者表示,phi-4的小参数设计为创意写作领域带来革命性突破,其每秒约12个tokens的流畅运行速度更是在苹果M4 Pro笔记本上实现了完美适配。这款模型的横空出世,标志着人工智能领域在效率与性能之间找到了新的平衡点。
phi-4的卓越表现源于其创新的数据训练策略。与传统的网络爬取数据相比,phi-4采用高质量的合成数据进行预训练,这种结构化、逐步呈现的学习材料使模型能够更高效地掌握语言逻辑与推理过程。在数学问题解答中,合成数据可按解题步骤逐步展示,帮助模型深入理解问题结构与解题思路。此外,phi-4的合成数据生成严格遵循多样性、细腻性与复杂性、准确性、推理链等原则,涵盖50余种不同类型的合成数据集,通过多阶段提示流程、种子策划、改写与增强、自我修订等先进方法,累计生成约4000亿个未加权的tokens。
在数据筛选方面,微软研究团队从网络内容、授权书籍和代码库等多渠道收集数据,采用基于小分类器的过滤方法,并针对多语言数据(德语、西班牙语、法语、葡萄牙语、意大利语、印地语、日语等)进行专门处理,确保模型具备全球化的语言处理能力。预训练阶段,phi-4主要使用合成数据,同时辅以少量高质量有机数据,这种混合策略既强化了模型的推理与问题解决能力,又丰富了其知识储备。中期训练阶段,phi-4将上下文长度扩展至16384,并新增长于8K上下文的非合成数据样本及4K序列要求的合成数据集,显著提升了对长文本的处理能力。

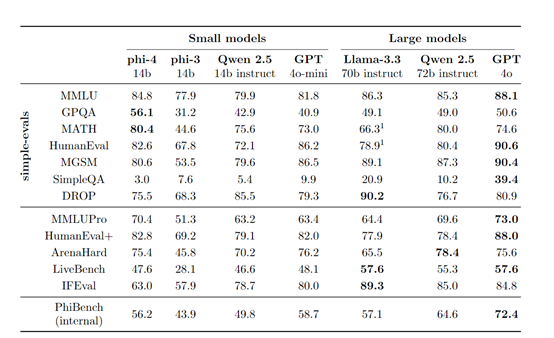
后训练阶段是phi-4性能优化的关键。微软采用监督微调(SFT)和直接偏好优化(DPO)技术,使用约8B tokens的高质量数据(含40种语言)对预训练模型进行微调,并引入关键tokens搜索(PTS)技术生成DPO对,精准提升模型在推理任务中的表现。这种多维度优化策略使phi-4在学术基准测试中全面开花,在MMLU测试中取得84.8分的高分,在GPQA和MATH测试中超越GPT-4o,在数学竞赛相关任务中展现出惊人的推理能力。与其他类似规模模型比较,phi-4在12个基准测试中的9个上表现优于Qwen – 2.5 – 14B – Instruct,充分证明其技术领先性。








相关推荐
-
DeepSeek引领低成本革命 国产大模型如何兼顾高精度低能耗
2025年伊始,DeepSeek在国内外大模型领域掀起了一场波澜壮阔的变革。凭借其卓越的深度推理模型DeepSeek-R1,DeepSeek不仅在国际大模型排行榜上崭露头角,更给国…
-
万相2.1开源模型评测:中文文生视频领先Sora?
开源周的热潮仍在继续,AI领域的创新者们纷纷展现出自己的实力。2月25日这一天,Claude发布了Sonnet 3.7版本,DeepSeek开源了DeepEP代码库,而阿里的万相2…
-
英特尔CEO陈立武上任14天首把火:剥离非核心业务聚焦AI芯片
英特尔CEO陈立武上任14天,便以一场震撼行业的变革宣告其领导力。4月1日凌晨,英特尔(Intel)CEO陈立武(Lip-Bu Tan)在Intel Vision活动上发表了一场长…
-
OpenAIAnthropicAgent市场竞争格局创业公司突围策略
OpenAI首席产品官表示不担心模型商品化问题,认为技术发展曲线陡峭,领先者始终在定义新可能。而Anthropic首席产品官则承认模型正在产品化,且未来模型差异将越来越大。但产品产…
-
OpenAI品牌重塑:以全新设计彰显“人味十足”的AI哲学
新年伊始,OpenAI 在其估值攀升至 3400 亿美元的新巅峰之际,也迎来了品牌形象的全面革新。公司更换了新字体、新标志、新配色方案,进行了一次深刻的品牌重塑。这一系列变革背后,…
-
Meta官宣2025大会:AI眼镜成焦点 Meta押注未来科技
作为全球XR领域的领军企业,Meta的每一步动态都备受业界瞩目。近日,Meta正式宣布2025年Meta Connect大会将于9月17日盛大召开,这一消息再次点燃了全球科技界的期…
-
美国无限期封禁英伟达H20芯片对华出口 致400亿季度收入损失
(图片来源:英伟达官网)北京时间4月16日凌晨,全球AI芯片领导者英伟达正式向美国证券交易委员会(SEC)提交8-k文件,宣布已收到美国特朗普政府的通知,将对中国、以色列等D-5国…
-
Runway发布超逼真文生图模型Frames创意无限
Runway平台隆重推出其最新力作——超逼真文生图模型Frames,为创意领域带来革命性突破。Frames不仅完美保持风格一致性,更赋予用户无限创意空间,可生成复古、数码、杂志、动…
-
AI一键美颜妆造 30秒解锁旅拍新姿势 AI摄影助力景区揽客
2月26日至27日,2025年全省艺术创作工作会议在富阳隆重召开,这标志着省文化广电和旅游厅组建后的“新春第一会”正式拉开帷幕。会议聚焦当前文化广电旅游工作的核心要义,旨在进一步明…
-
Flowith Neo:无限智能体创新突破引领AI新潮流
Flowith Neo:重塑AI生成力的无限可能 在AI智能体领域,Manus的”上帝之手”称号正被Flowith旗下的Neo悄然取代。这款智能体背后的团队…