阿里开源32B推理模型性能媲美DeepSeek R1
中国企业在人工智能领域的创新实力正不断刷新全球认知。继DeepSeek通过大规模强化学习(Reinforcement Learning, RL)显著提升模型推理性能后,阿里巴巴(阿里)推出的QwQ-32B新型大语言模型再次引发轰动,以更高效的性能突破惊艳业界。
DeepSeek的开创性贡献
作为中国AI领域的先行者,DeepSeek率先将大规模强化学习技术应用于AI模型的后训练阶段,成功实现了模型推理能力的飞跃。其旗舰模型DeepSeek-R1拥有高达6710亿参数(其中370亿为激活参数),在数学推理、编程能力等关键领域展现出卓越表现,令全球AI研究界为之振奋。这一突破不仅为AI模型性能提升开辟了全新路径,更为后续研究奠定了坚实基础。
阿里QwQ-32B:更高效的性能突破
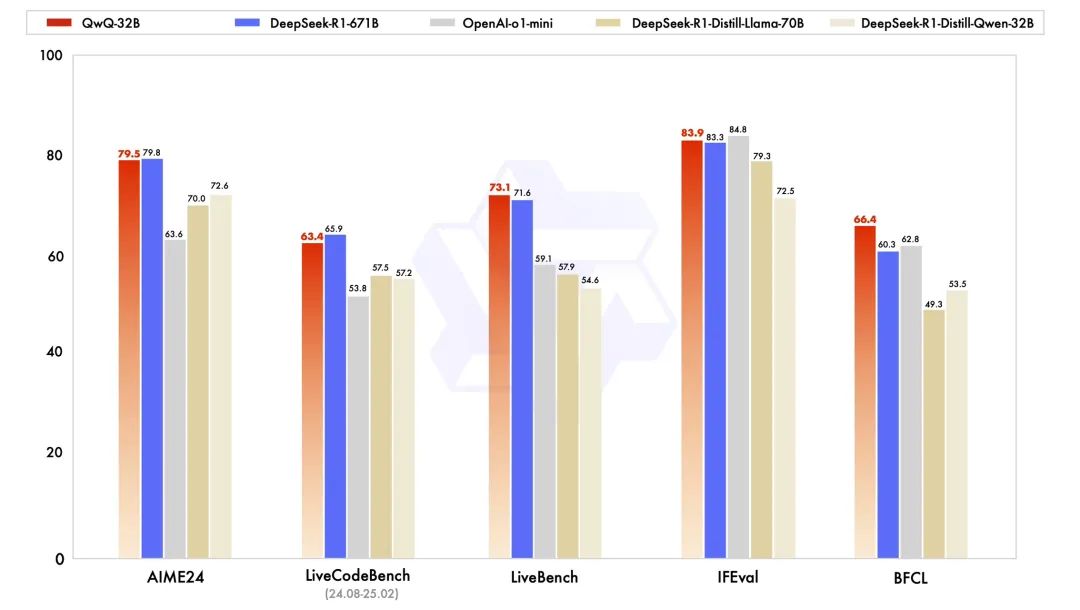
基于DeepSeek的开创性工作,阿里进一步验证并优化了大规模强化学习技术,推出了参数规模更小却性能更优的QwQ-32B模型。该模型仅拥有320亿参数,远低于DeepSeek-R1的规模,却在多个基准测试中展现出与之媲美的能力,具体表现在:


数学推理:能够高效解决各类复杂数学问题
编程能力:生成高质量代码并通过严格测试用例验证
通用能力:在广泛任务场景中表现出色
更令人惊叹的是,QwQ-32B还集成了先进的智能体(Agent)功能,使其在使用工具时具备批判性思考能力,可根据环境反馈动态调整推理过程。这一特性显著增强了模型在实际应用中的灵活性和实用性,为AI落地场景提供了更多可能。
创新的强化学习策略
阿里团队在QwQ-32B的训练中采用了独特的强化学习策略,从冷启动开始,针对数学和编程任务进行大规模优化。具体方法包括:
直接反馈机制
数学任务:通过验证答案正确性提供精准反馈
编程任务:利用代码执行服务器检查生成代码是否通过测试用例
两阶段强化学习
第一阶段:专注提升数学和编程能力
第二阶段:引入针对通用能力的训练,结合通用奖励模型和基于规则的验证器,仅通过少量步骤就显著提升整体性能,同时保持数学和编程任务的高水平表现
这一策略不仅验证了强化学习在提升模型智能方面的巨大潜力,还通过高效的训练流程实现了性能最大化,为AI模型训练提供了新思路。
开源共享,推动全球AI发展
为了加速AI技术的普及与发展,阿里将QwQ-32B以Apache 2.0开源协议在Hugging Face和ModelScope平台发布,供全球研究人员和开发者免费使用。此外,公众还可以通过Qwen Chat直接体验这一模型的强大功能,进一步拉近了尖端技术与普通用户之间的距离。
QwQ-32B的成功再次证明,将强大的基础模型与大规模强化学习相结合,能够在保持高性能的同时有效控制参数规模,为未来通向通用人工智能(AGI)提供了可行路径。从DeepSeek的创新性探索到阿里的惊艳优化,中国企业在AI领域的接力突破正推动着全球技术的前进,为人类智慧发展注入新动力。
相关推荐
-
DeepSeek赋能AI公务员上岗 提升政务效率创新应用
近日,镇江市数据局通过新闻发布会正式亮相其本地化部署的DeepSeek AI系统,相关负责人在会上透露,该系统单日可处理的数据量相当于全市公务员十年工作量总和。这一表述虽略显夸张,…
-
拜登急攻中国AI芯片巨头 智谱等20余实体被列入美国黑名单
路透社最新消息显示,美国政府在当地时间1月15日对《出口管制条例》(EAR)进行了重大修订,将包括智谱AI在内的20多家中国实体正式列入美国限制贸易的黑名单。此次行动不仅涉及对华芯…
-
2025全球产品经理大会:AI产品实战与未来趋势深度解析
用户体验至上是乔布斯在产品设计中恪守不渝的核心理念。他曾深刻指出:”人们并不知道他们想要什么,直到你把它摆在他们面前。”在 AI 大模型蓬勃发展的时代背景下…
-
微软谷歌AI战略聚焦开放代理网络与Gemini操作系统
《窄播Weekly》第55期:微软与Google的AI战略交锋 本周商业动态聚焦于微软和Google在开发者大会上的AI战略布局。微软的Build 2025大会与Google的I/…
-
奥特曼激战梁文锋 AI营销巅峰对决
“AI营销大师”奥特曼的声名正日益巩固。在被梁文锋短暂抢占风头后,奥特曼以每周推出新产品的惊人速度,强势占据AI热搜榜首。仅在过去一周内,OpenAI就接连…
-
京东入股智元机器人估值150亿 稚晖君公司或瞄准IPO
京东科技正式入股估值150亿元的智元机器人,加速布局具身智能领域 5月24日,工商信息显示,智元机器人主体”上海智元新创技术有限公司”完成新一轮融资,新增股…
-
AI算命热潮:赛博安慰剂背后的情绪价值探索
新学期开学后的家庭聚餐上,五年级小学生林朵偶然听到大人们谈论用DeepSeek“算命”,虽然她既不懂算命,也不明白DeepSeek是哪两个单词,但还是好奇地向爸爸要来手机,向那个画…
-
DeepSeek引爆国内AI市场:从搜索到创作全场景接入热潮
DeepSeek正以惊人的速度席卷中国互联网,从科技巨头到独立开发者,众多应用纷纷接入这一AI引擎,掀起了一场前所未有的技术革命。如今,打开手机,”是否接入DeepSe…
-
AI儿童硬件竞争激烈 学习机成焦点
AI技术正在硬件领域绽放光彩,逐渐融入人们的日常生活,其中最受关注的话题之一便是:哪些人群是AI硬件的现实用户?以智能穿戴设备为例,这类产品的主要受众是年轻人,但目前市场上价格与质…
-
睿思芯科发布灵羽处理器 中国首款全自研高性能RISC-V服务器芯片问世
刚刚过去的三月底,国产RISC-V迎来了历史性的破局时刻。知名芯片设计企业睿思芯科在深圳正式发布了中国首款全自研高性能RISC-V服务器处理器——灵羽处理器,标志着中国在高端芯片领…